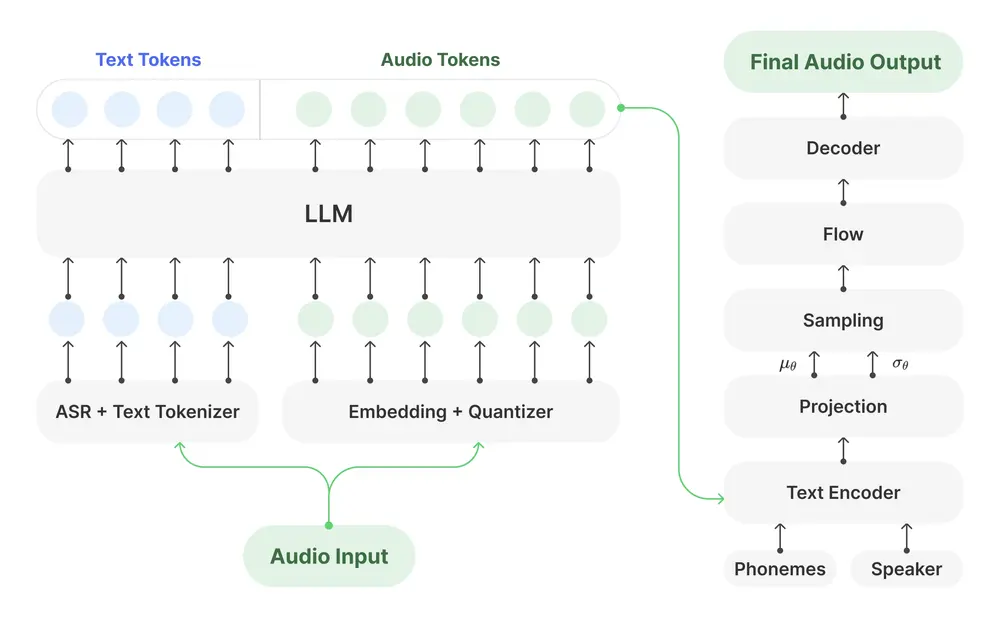
北京沐言智语科技开源专为播客场景优化的可训练TTS模型 Muyan-TTS 北京沐言智语科技开源可训练文本到语音(TTS)模型 Muyan-TTS ,专为播客场景优化,并在5万美元的预算内开发。该模型通过在超过10万小时的播客音频数据上进行预训练,能够实现高质量的零样本文本到...语音模型# Muyan-TTS# TTS模型7个月前02940
INTELLECT-2 发布:首个通过全球分布式强化学习训练的 32B 参数模型Prime Intellect发布 INTELLECT-2,这是首个通过全球分布式强化学习训练的 32B 参数模型。与传统的集中式训练不同,INTELLECT-2 使用完全异步的强化学习(RL),在一...大语言模型# INTELLECT-2# 强化学习7个月前02330
多模态模型RoboBrain:让机器人从抽象指令到具体操作的多模态大脑近年来,多模态大语言模型(MLLMs)在多种场景中展现了卓越的能力,但在机器人领域,尤其是在长时段复杂操作任务中,其表现仍存在显著局限性。这些局限主要源于当前 MLLMs 缺乏三种关键能力:规划能力...多模态模型# RoboBrain# 多模态模型# 机器人7个月前02380
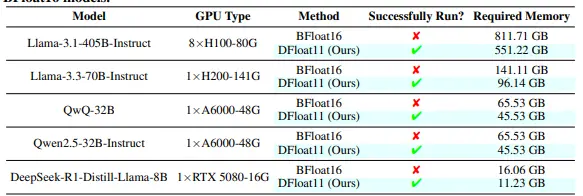
无损压缩框架DFloat11:可将大语言模型的规模缩小约 30%,同时保持与原始模型完全一致的逐位相同输出DFloat11 是一个无损压缩框架,可将大语言模型(LLM)的规模缩小约 30%,同时保持与原始模型完全一致的逐位相同输出。它支持在资源受限的硬件上进行高效的 GPU 推理,且不牺牲准确性。 Git...大语言模型# DFloat11# 无损压缩框架7个月前02950
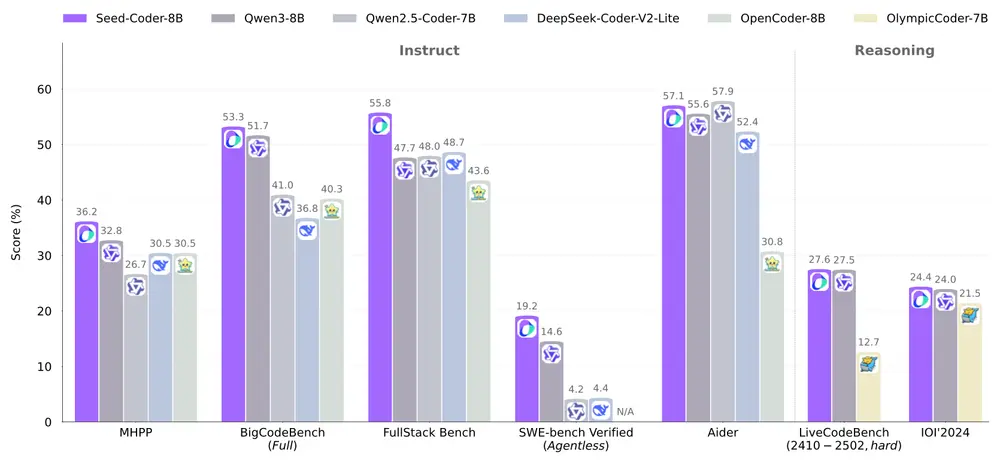
字节跳动推出Seed-Coder:轻量级开源代码大模型,性能媲美更大规模模型字节跳动近日发布了全新的开源代码大语言模型(LLM)系列——Seed-Coder,标志着其在开源大语言模型生态系统中的首次重要贡献。这一系列模型以轻量化和高性能为核心特点,包括基础模型、指令模型和推理...大语言模型# Seed-Coder# 代码大模型# 字节跳动7个月前03110
基于FLUX模型的图像定制框架DreamO:支持多种图像定制任务,同时实现多种条件(如身份、主体、风格、背景等)的无缝集成字节跳动和北京大学深圳研究生院的研究人员推出一个基于DiT模型的图像定制框架DreamO ,旨在支持多种图像定制任务,同时实现多种条件(如身份、主体、风格、背景等)的无缝集成。它通过引入特征路由约束和...图像模型# DreamO# 图像定制框架7个月前02750
新型视频法线估计模型 NormalCrafter :能够从任意长度的开放世界视频中生成具有时间一致性和细粒度细节的法线序列香港理工大学、腾讯 PCG ARC 实验室、香港城市大学和华中科技大学的研究人员推出新型视频法线估计模型 NormalCrafter ,它能够从任意长度的开放世界视频中生成具有时间一致性和细粒度细节的...视频模型# NormalCrafter# 视频法线估计模型8个月前03400
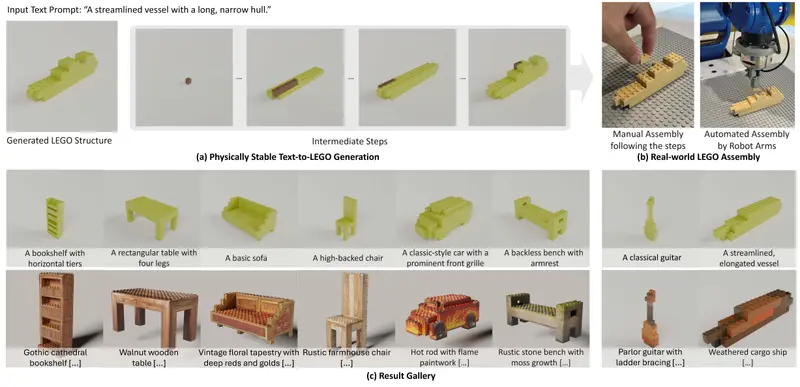
专为乐高设计的大模型LegoGPT:通过简单的文本输入生成独特的乐高设计卡内基梅隆大学的研究团队推出了一款名为 LegoGPT 的AI模型,它能够通过简单的文本输入生成独特的乐高设计。这一工具不仅展示了AI在创意领域的潜力,还为乐高爱好者提供了一个全新的设计方式。 项目主...多模态模型# LegoGPT# 乐高8个月前01920
腾讯混元团队开源多模态定制化视频生成工具Hunyuan Custom:融合文本、图像、音频、视频等多模态输入生视频的能力在内容创作领域,视频生成技术正不断进化,但如何让生成的视频既保持主体一致性,又能实现多样化的场景和动作变化,一直是创作者面临的难题。今天,腾讯混元团队正式推出并开源了一款全新的多模态定制化视频生成工具...视频模型# Hunyuan Custom# 多模态定制# 腾讯8个月前03240
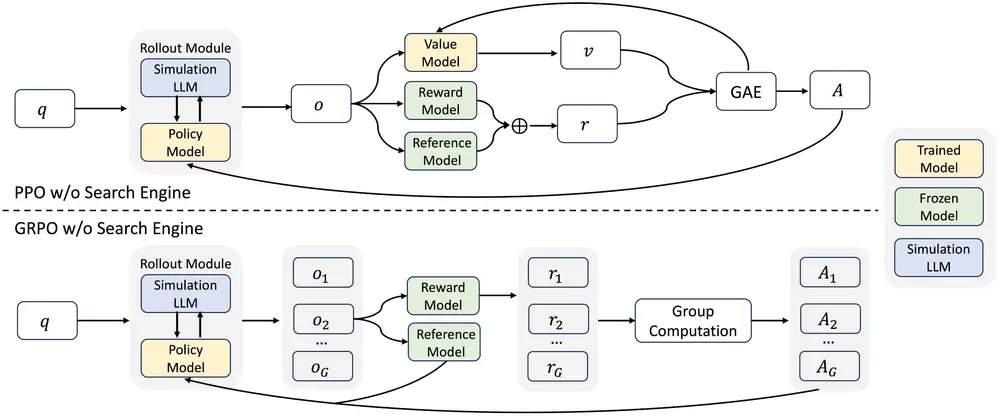
阿里通义实验室推出强化学习框架ZEROSEARCH:通过模拟搜索引擎来提升大语言模型的信息检索能力阿里通义实验室推出一种创新的强化学习框架ZEROSEARCH,通过模拟搜索引擎来提升大语言模型(LLMs)的信息检索能力,而无需与真实搜索引擎进行交互。该框架通过轻量级的监督微调(SFT),将 LLM...大语言模型# ZEROSEARCH# 强化学习框架8个月前01860
3D 原语组装生成框架PrimitiveAnything:通过自回归变换器将复杂的 3D 形状分解为简单几何原语的组合腾讯和清华大学的研究人员推出一种新型3D 原语组装生成框架PrimitiveAnything,旨在通过自回归变换器将复杂的 3D 形状分解为简单几何原语的组合。该框架通过学习人类如何将复杂形状分解为基...3D模型# 3D# PrimitiveAnything8个月前03000
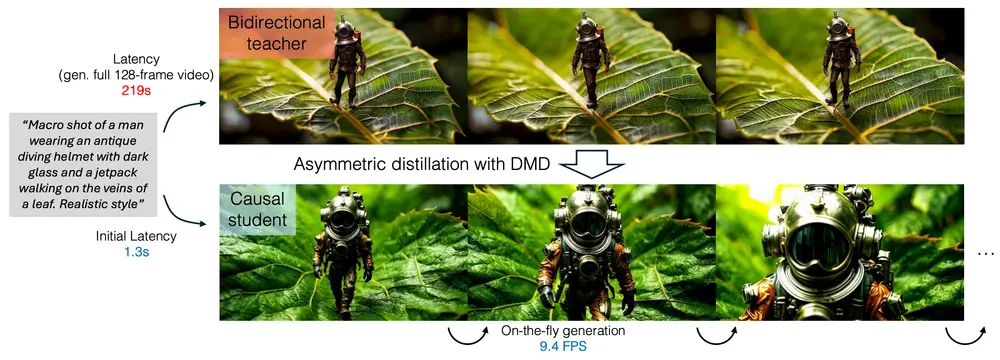
新型自回归视频扩散模型CausVid:解决传统双向扩散模型在交互式应用中的高延迟问题麻省理工学院和Adobe的研究人员推出新型自回归视频扩散模型CausVid,旨在解决传统双向扩散模型在交互式应用中的高延迟问题。通过将双向扩散模型蒸馏为快速自回归生成器,CausVid 能够实现低延迟...视频模型# CausVid# 自回归视频扩散模型8个月前03030