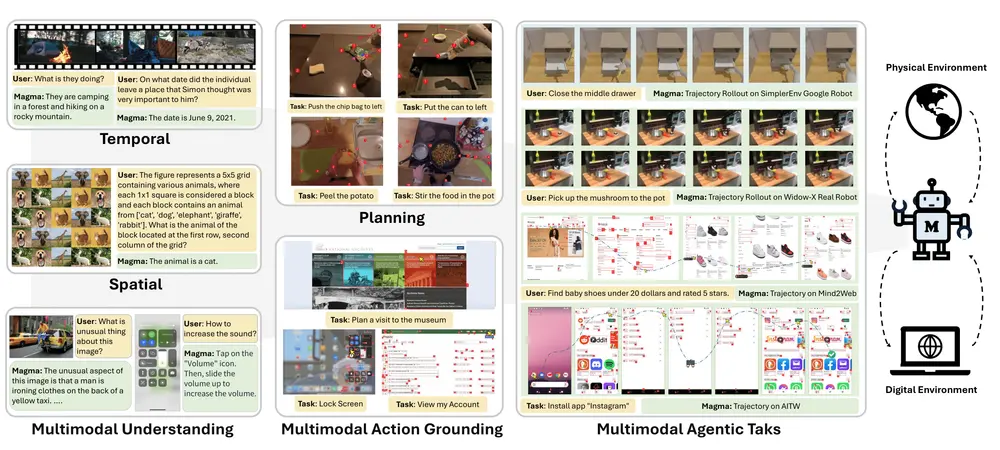
微软研究院推出的多模态 AI 代理基础模型MagmaMagma 是由微软研究院推出的一款面向多模态AI代理的基础模型,为一系列智能任务提供强大的支持。它不仅具备视觉-语言(VL)模型的理解能力(即语言智能),还拥有在视觉空间世界中规划和执行动作的能力...多模态模型# Magma# 多模态# 微软研究院11个月前03000
首个截图就能生成现代前端代码的多模态模型Flame尽管前沿的多模态模型(如 GPT-4O)在代码生成上展现了强大的能力,但它们在真实的前端开发场景中仍无法满足现代前端工作流程的动态需求。这些模型虽然能够生成代码,但输出的前端代码通常是静态的,缺乏模块...多模态模型# Flame# 前端代码# 多模态模型11个月前03950
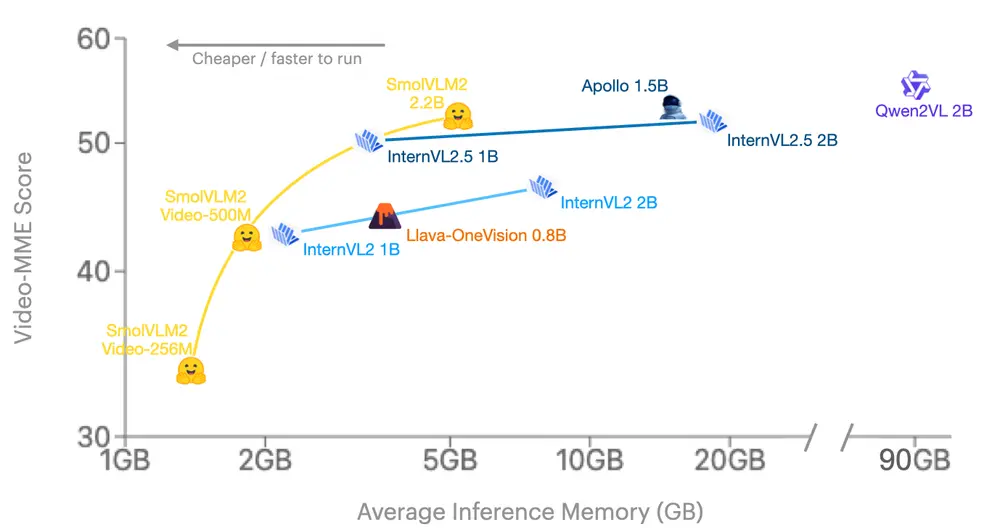
Hugging Face 发布轻量级多模态模型SmolVLM2:专为视频内容分析而设计Hugging Face 最新发布了一款轻量级多模态模型SmolVLM2,专为视频内容分析而设计。该模型以高效性和适应性为核心目标,旨在将视频理解能力扩展到从手机到服务器的各种设备上。SmolVLM2...多模态模型# Hugging Face# SmolVLM2# 多模态模型11个月前02840
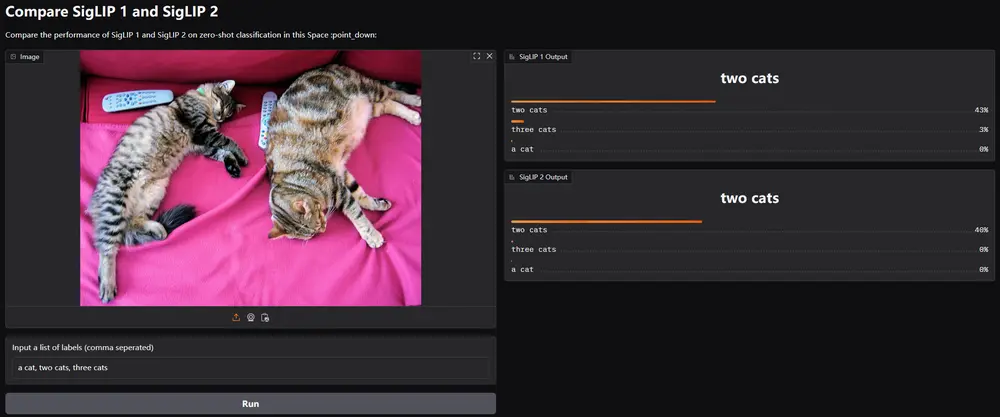
谷歌发布多语言视觉语言编码器SigLIP 2今天,谷歌正式发布了 SigLIP 2——一个全新的多语言视觉语言编码器系列。SigLIP 2 在语义理解、定位和密集特征方面进行了显著改进,进一步提升了视觉语言模型的性能。 官方说明:https...多模态模型# PaliGemma 2# SigLIP 2# 视觉编码器11个月前02540
谷歌推出PaliGemma 2 Mix:在混合视觉语言任务上进行微调的视觉语言模型版本,涵盖 OCR、长短字幕等多种任务去年 12 月5日,谷歌发布了 PaliGemma 2,这是一个基于 SigLIP 和 Gemma 2 的新型预训练视觉语言模型(VLM)系列。这些模型提供了三种不同的尺寸(3B、10B、28B)和三...多模态模型# PaliGemma 2 Mix# 视觉语言模型# 谷歌12个月前02370
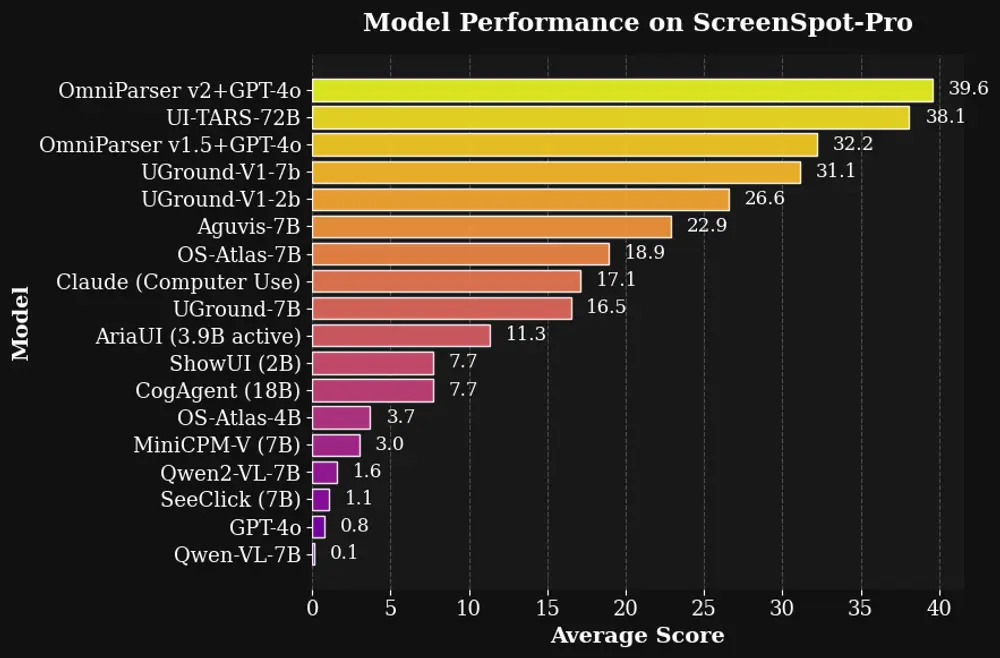
让大语言模型“看懂”图形界面!微软推出 OmniParser V2.0:将大语言模型转化为 GUI 交互智能体微软的 OmniParser 发布了 V2 更新,这一版本的核心目标是将任何大语言模型(LLM)转化为能够理解和交互图形用户界面(GUI)的智能体。相比前一代,OmniParser V2 在检测更小可...多模态模型# OmniParser V2.0# 微软# 智能体12个月前02900
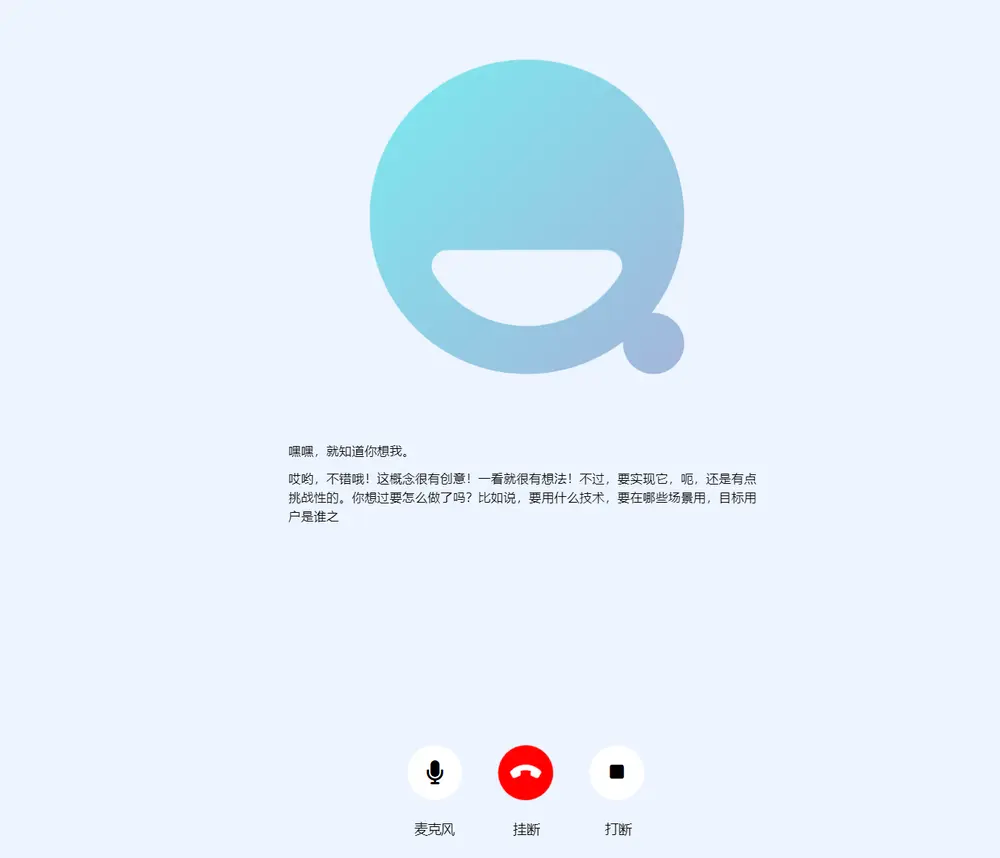
拟人化实时交互系统SpeechGPT 2.0-preview:支持多种音色,200毫秒延迟复旦大学自然语言处理实验室近期推出了SpeechGPT 2.0-preview,这是他们为实现情景智能而开发的第一个拟人化实时交互系统。基于百万小时级别的语音数据训练而成,这款端到端的语音大模型不仅能...多模态模型# SpeechGPT 2.0-preview# 语音模型12个月前03010
阿里通义实验室发布了Qwen 模型家族的旗舰视觉语言模型Qwen2.5-VL阿里通义实验室发布了Qwen 模型家族的旗舰视觉语言模型Qwen2.5-VL,对比此前发布的 Qwen2-VL 实现了巨大的飞跃。欢迎访问 Qwen Chat 并选择 Qwen2.5-VL-72B-I...多模态模型# Qwen2.5-VL# 视觉语言模型11个月前02500
深度求索开源多模态理解与生成模型 Janus-Pro,已释出两个版本Janus-Pro-7B和Janus-Pro-1B深度求索(DeepSeek-AI)在DeepSeek-R1爆火后,又在今天释出了多模态理解与生成模型 Janus-Pro,它是之前工作 Janus 的升级版本,目前释出了两个版本Janus-Pro-7...多模态模型# Janus-Pro# Janus-Pro-1B# Janus-Pro-7B12个月前02880
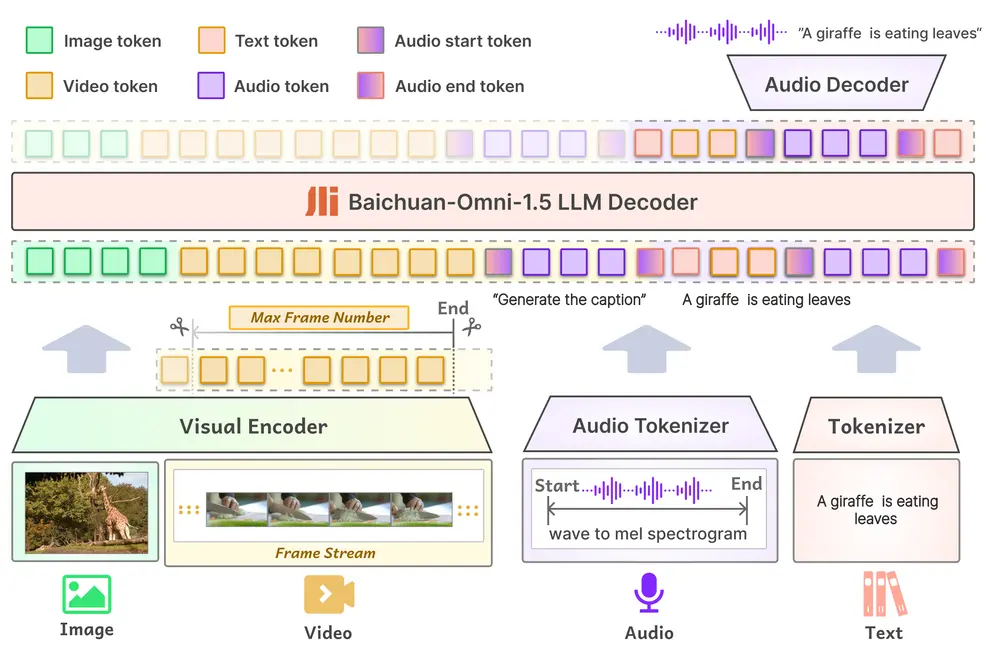
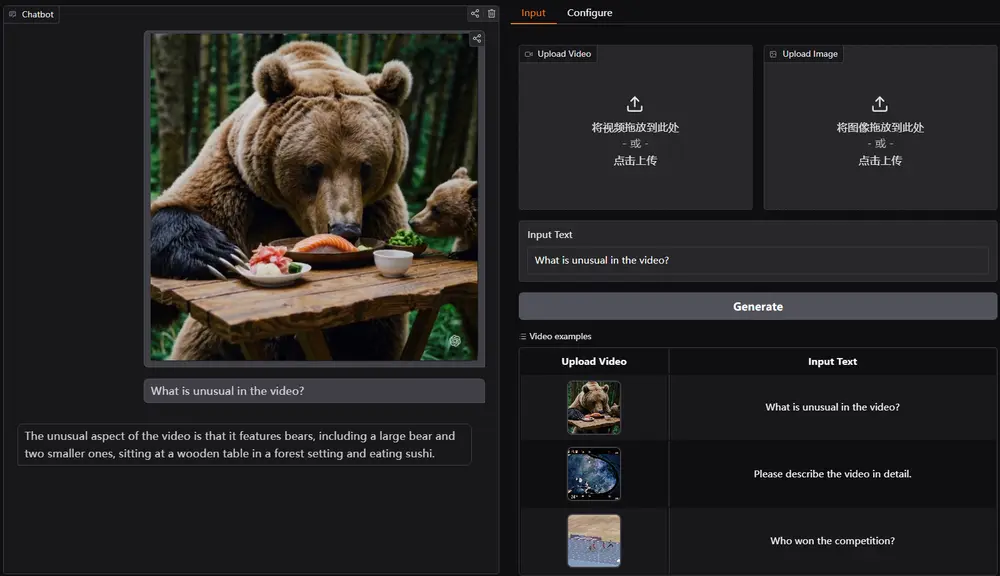
百川智能发布全模态开源模型Baichuan-Omni-1.5百川智能宣布其最新研发的Baichuan-Omni-1.5开源全模态模型正式上线。这款模型支持文本、图像、音频和视频等多种格式的数据处理,并具备文本与音频的双模态生成能力。Baichuan-Omni...多模态模型# Baichuan-Omni-1.5# 百川智能12个月前02650
新型多模态基础模型VideoLLaMA 3:提升图像和视频理解的性能阿里巴巴达摩院的研究人员推出新型多模态基础模型VideoLLaMA 3,旨在提升图像和视频理解的性能。该模型的核心设计理念是“以视觉为中心”(vision-centric),通过高质量的图像-文本数据...多模态模型# VideoLLaMA 312个月前04470
Hugging Face发布号称同类最小的多模态模型SmolVLM系列Hugging Face团队最近发布了两款名为SmolVLM-256M和SmolVLM-500M的新模型,它们被宣称为能够分析图像、短视频以及文本的最小AI模型。这两款模型特别设计用于在资源受限的设备...多模态模型# Hugging Face# SmolVLM12个月前02720