TNG科技微调 olmOCR推出olmOCR-7B-faithful:更忠实的 OCR 模型,适用于业务场景中的全面信息提取光学字符识别(OCR)技术在文档数字化和信息提取领域扮演着重要角色。然而,传统的基于流水线的 OCR 系统虽然功能强大,却常常因无法处理复杂布局而受到限制。最近,艾伦人工智能研究所推出的 olmOCR...多模态模型# olmOCR# olmOCR-7B-faithful9个月前02140
PyVision:基于动态工具生成的多模态智能视觉推理框架随着大语言模型(LLMs)的发展,我们正进入一个代理式人工智能(Agent AI)时代。这些模型不仅能够生成文本,还能进行任务规划、逻辑推理,并调用外部工具来扩展能力边界。 但真正的前沿在于:不是仅仅...多模态模型# PyVision# 多模态智能视觉推理7个月前02130
Meta推出基于视频训练的“世界模型”V-JEPA 2:AI“世界模型”迈出理解物理世界的重要一步Meta 发布了其最新 AI 研究成果 —— V-JEPA 2,一个基于视频训练的“世界模型”,旨在帮助 AI 更好地理解现实世界的物理规律,并用于机器人控制、任务规划等复杂场景。 项目主页:http...多模态模型# Meta# V-JEPA 2# 世界模型8个月前02130
过程奖励模型WEB-SHEPHERD :专门用于评估网络导航任务中的智能代理行为延世大学和卡内基梅隆大学的研究人员推出一个名为 WEB-SHEPHERD 的过程奖励模型(PRM),专门用于评估网络导航任务中的智能代理行为。网络导航是一个复杂的领域,需要智能代理能够进行长期的序列决...多模态模型# WEB-SHEPHERD# 过程奖励模型8个月前02130
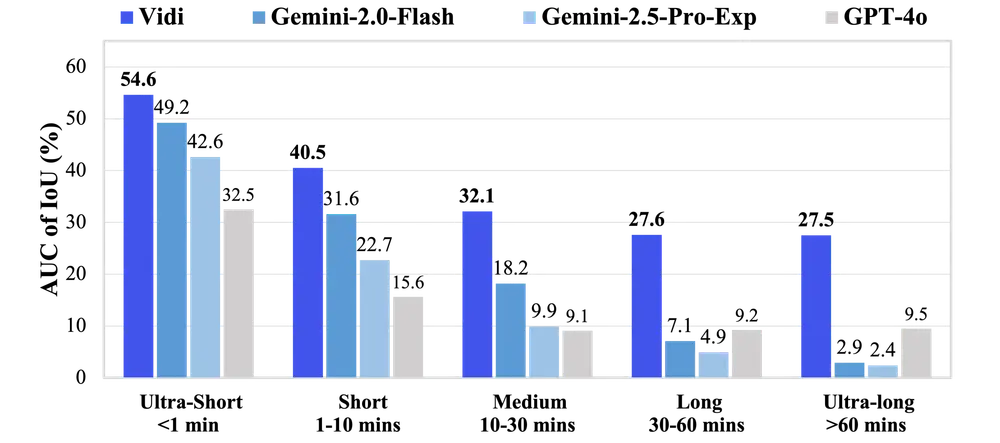
字节跳动推出多模态模型Vidi:专门用于视频理解和编辑字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成...多模态模型# Vidi# 多模态模型# 字节跳动9个月前02130
阿里 Qwen 项目组正式推出全新多模态模型Qwen VLo随着多模态大模型的不断发展,我们对技术边界的认知也在持续被刷新。从最初的 QwenVL 到如今的 Qwen2.5 VL,我们在提升模型图像理解能力方面不断取得进步。 项目主页:https://qwen...多模态模型# Qwen VLo# Qwen 项目组# 阿里巴巴7个月前02040
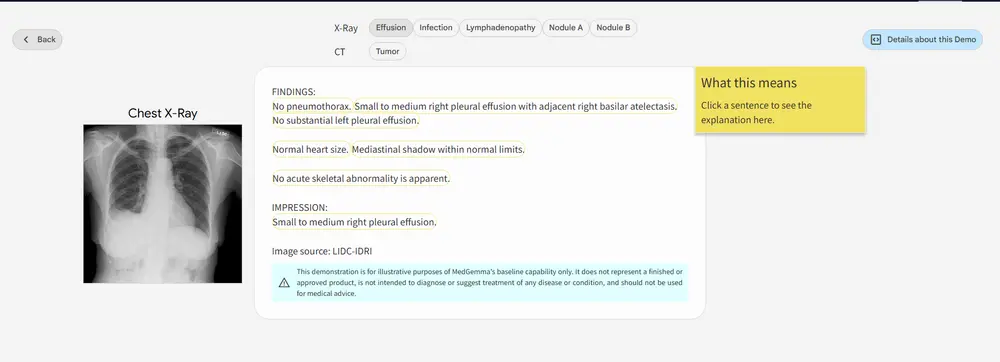
谷歌发布医学多模态开源模型MedGemma:支持图像与文本理解,支持X光CT分析谷歌近日推出了一款面向医疗领域的开源模型系列 —— MedGemma,该模型基于 Gemma 3 构建,在医学图像识别与文本理解方面表现出色,标志着医疗 AI 在开源方向上的重要进展。 MedGemm...多模态模型# MedGemma# 医学多模态开源模型# 谷歌8个月前02020
让大模型真正“看懂”界面:InfiGUI-G1提升 GUI 操作中的语义理解能力在图形用户界面(GUI)自动化任务中,让多模态大语言模型(MLLM)准确执行自然语言指令,远不只是“点击坐标”那么简单。真正的挑战在于:既要精准定位界面上的元素(空间对齐),又要正确理解指令背后的意图...多模态模型# InfiGUI-G16个月前02010
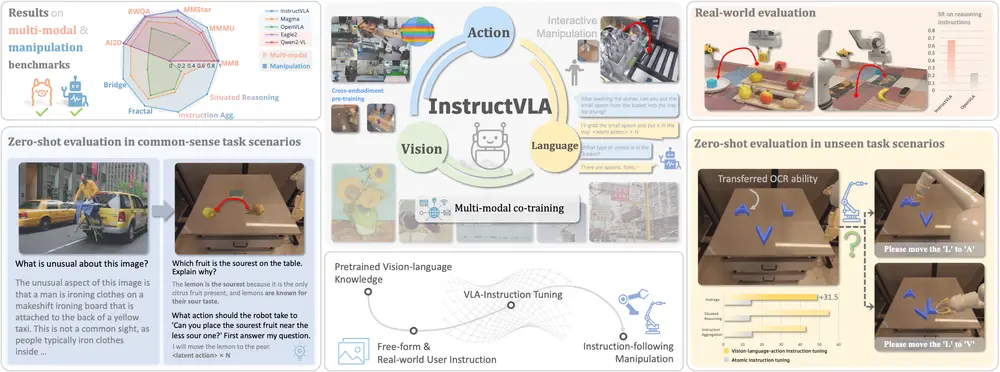
端到端的 VLA 模型InstructVLA:让机器人真正“听懂”指令并准确执行要让机器人走进真实世界,完成诸如“把苹果放进桌上的红碗”这样的任务,仅靠预设程序远远不够。它必须具备两项关键能力: 理解复杂语义——分辨“红碗”是颜色还是材质?“桌上”是否包含边缘? 生成精确动作...多模态模型# InstructVLA# VLA 模型6个月前02000
字节跳动 & 港大推出 Mini-o3:可扩展多轮推理的开源视觉智能体字节跳动与香港大学联合发布 Mini-o3 ——一个具备强大图像理解与长程多轮交互能力的开源多模态模型。该模型能够生成类似 OpenAI o3 风格的代理行为轨迹,在复杂视觉搜索任务中实现数十轮持续推...多模态模型# Mini-o3# 视觉智能体5个月前01990
POINTS-Reader:无需蒸馏、端到端的轻量级文档视觉语言模型腾讯、上海交通大学与清华大学联合推出 POINTS-Reader —— WePOINTS 家族最新成员,一款专为文档图像转文本设计的轻量级视觉-语言模型(VLM)。 GitHub:https://gi...多模态模型# POINTS-Reader# 文档视觉语言模型5个月前01960
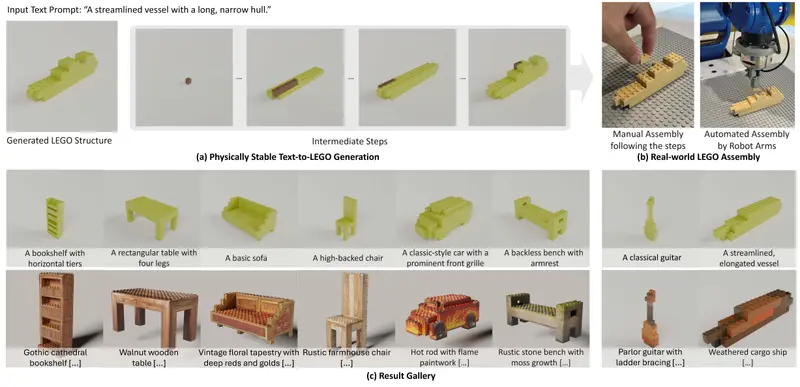
专为乐高设计的大模型LegoGPT:通过简单的文本输入生成独特的乐高设计卡内基梅隆大学的研究团队推出了一款名为 LegoGPT 的AI模型,它能够通过简单的文本输入生成独特的乐高设计。这一工具不仅展示了AI在创意领域的潜力,还为乐高爱好者提供了一个全新的设计方式。 项目主...多模态模型# LegoGPT# 乐高9个月前01940