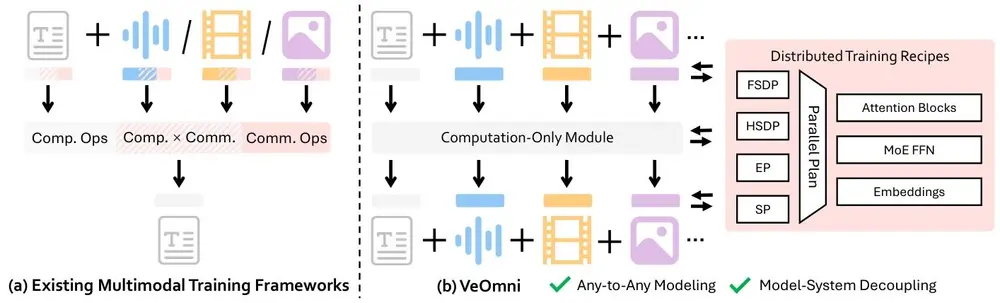
字节跳动开源 VeOmni:一个面向全模态大模型的 PyTorch 原生训练框架在大模型从“能说”向“能看、能听、能理解”演进的当下,多模态统一模型(Omni-Modal LLMs)正成为技术前沿。然而,训练一个同时处理文本、图像、语音和视频的全能模型,仍面临工程复杂、扩展困难...多模态模型# VeOmni# 多模态统一模型# 字节跳动6个月前01890
拥有20亿参数的多模态大语言模型Open-Qwen2VL在多模态大语言模型(MLLMs)的研究与应用中,视觉与文本模态的融合正在不断拓展其边界,从图像描述到视觉问答,再到复杂文档的解读,这些模型展现出了强大的能力。然而,这一领域的进一步发展面临着诸多挑战...多模态模型# Open-Qwen2VL# 多模态大语言模型10个月前01870
艾伦AI研究所推出 olmOCR:高性能的 PDF 和文档图像文本提取工具包艾伦AI研究所正式推出了 olmOCR,这是一款高性能的开源工具包,专为将 PDF 和文档图像转换为干净、结构化的纯文本而设计。 GitHub:https://github.com/allenai/o...多模态模型# olmOCR# 艾伦AI研究所11个月前01780
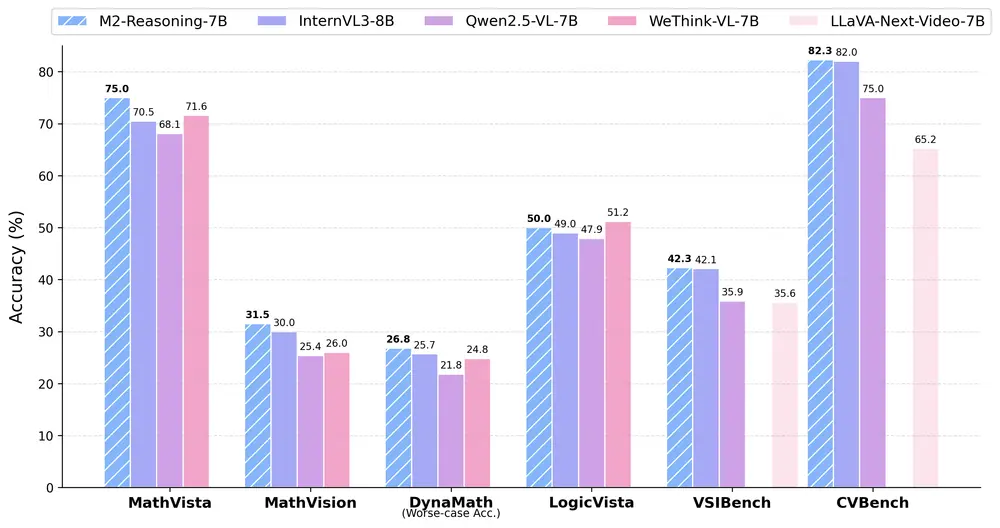
蚂蚁集团发布 M2-Reasoning-7B:通用与空间推理能力领先的多模态大模型蚂蚁集团 inclusionAI 项目组 正式发布 M2-Reasoning-7B,一个在通用推理与空间推理领域表现卓越的多模态大语言模型(MLLM)。该模型基于 70 亿参数架构,通过创新的数据生成...多模态模型# M2-Reasoning-7B# 多模态大模型# 蚂蚁集团7个月前01750
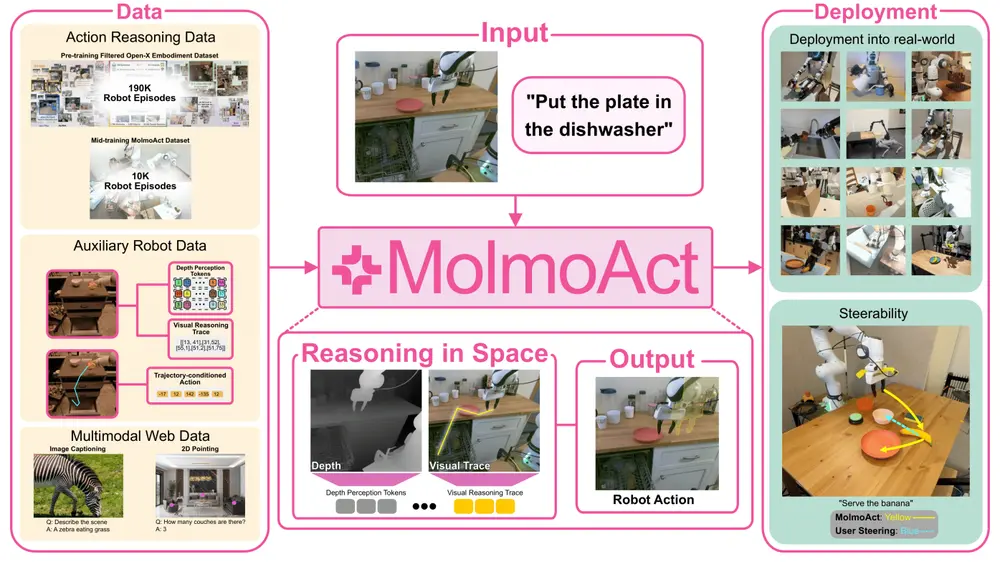
机器人行动推理模型MolmoAct:通过结构化的三阶段推理流程(感知、规划和控制)将视觉、语言和行动相结合,使机器人能够更智能地执行任务艾伦AI研究所和华盛顿大学的研究人员推出机器人行动推理模型MolmoAct ,它通过结构化的三阶段推理流程(感知、规划和控制)将视觉、语言和行动相结合,使机器人能够更智能地执行任务。MolmoAct ...多模态模型# MolmoAct# 机器人行动推理模型6个月前01720
面壁智能发布高效多模态模型 MiniCPM-V 4.0:4B 模型,超越 GPT-4.1-mini面壁智能正式推出 MiniCPM-V 4.0 —— MiniCPM-V 系列中最新的高效多模态模型,参数总量仅 4.1B,却在图像理解能力上实现显著突破。 GitHub:https://github...多模态模型# MiniCPM-V 4.0# 面壁智能6个月前01700
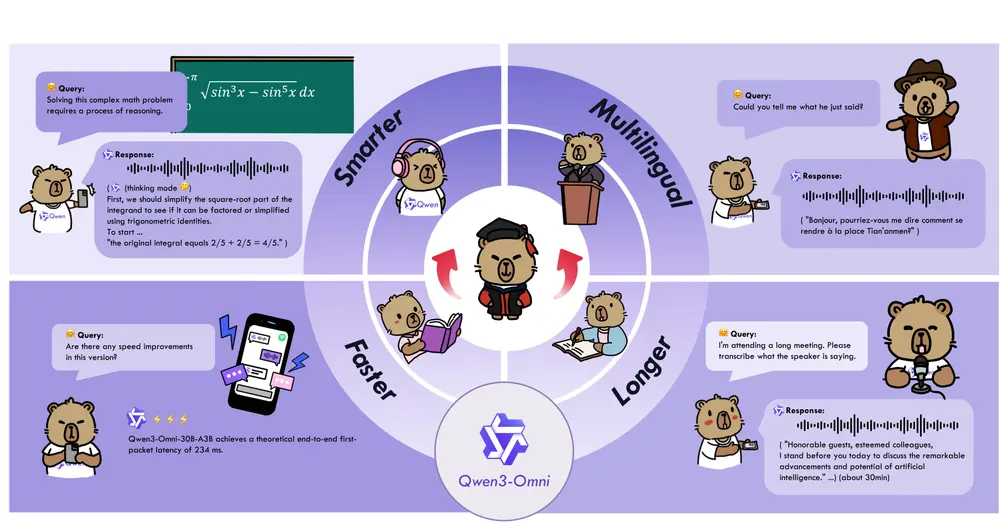
阿里通义实验室推出Qwen3-Omni:支持文本、语音、图像、视频的全模态大模型通义实验室正式推出 Qwen3-Omni——一款统一处理多模态输入并支持流式文本与语音输出的大语言模型。该模型已在 Qwen API 平台上线,开发者可通过接口体验其在音频对话、跨模态理解与指令执行方...多模态模型# Qwen3-Omni# 通义实验室4个月前01650
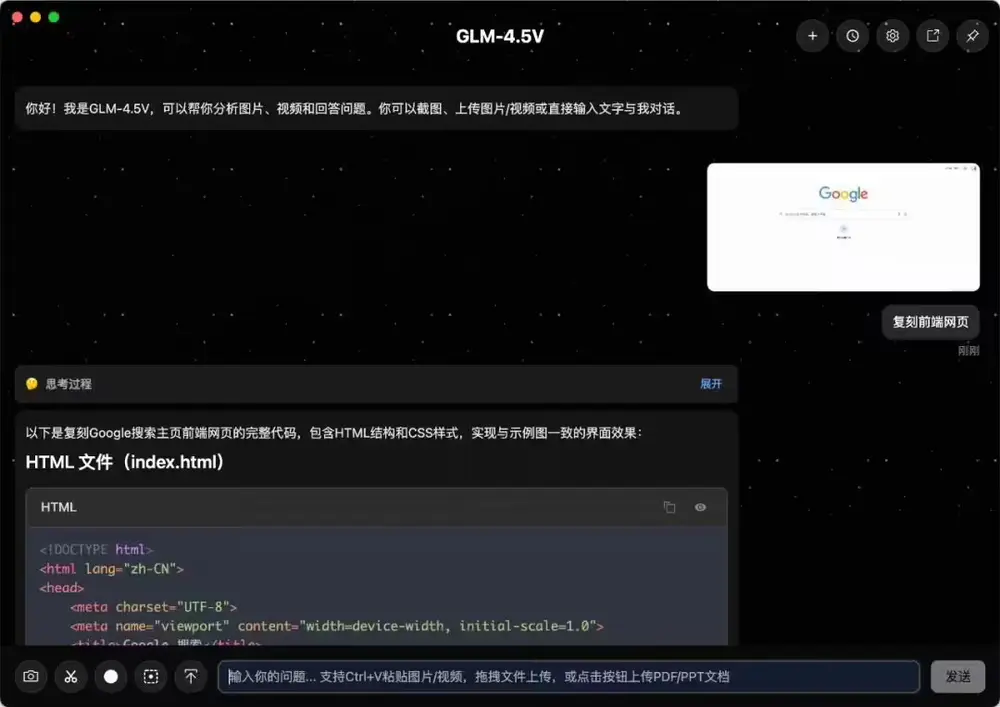
智谱AI发布GLM-4.5V:106B参数的开源视觉推理模型,支持“思考模式”切换今日,智谱 AI 正式推出其新一代开源视觉语言模型 GLM-4.5V,并在魔搭社区与 Hugging Face 同步开源。该模型总参数达 106B,采用 MOE(Mixture of Experts...多模态模型# GLM-4.5V# 智谱AI6个月前01650
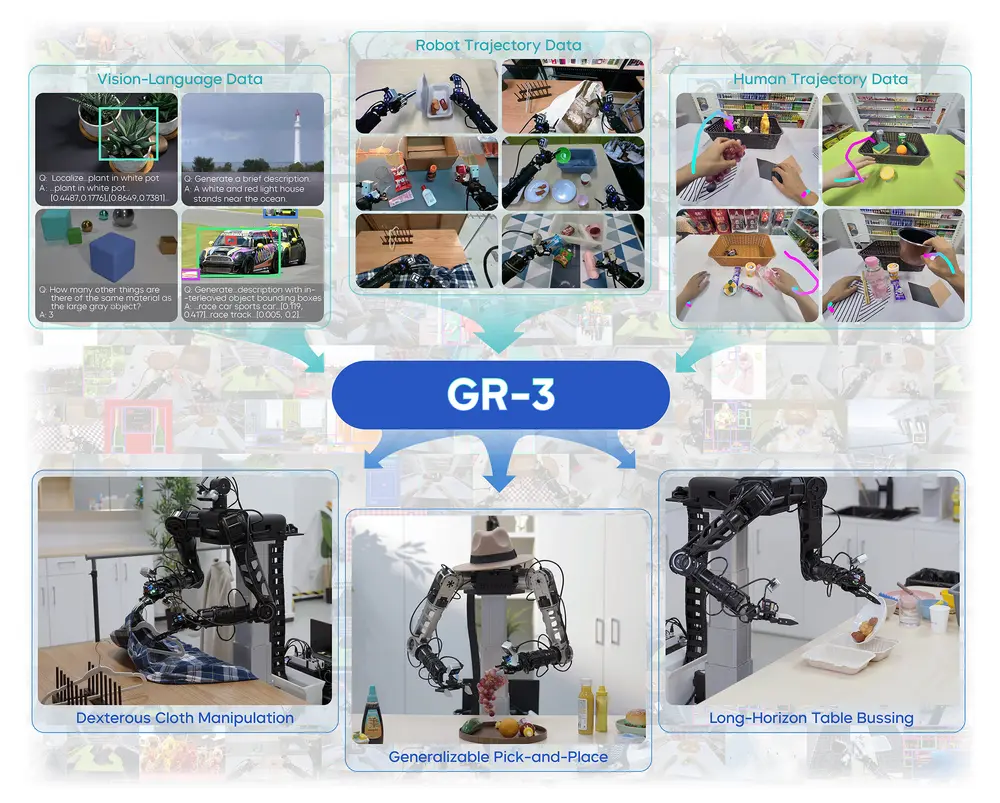
字节跳动Seed团队发布新一代机器人操作大模型Seed GR-3字节跳动Seed团队近日推出一款面向复杂操作任务的大规模机器人模型——Seed GR-3(Generalist Robot Model-3)。该模型具备良好的泛化能力,支持长序列任务执行与多模态指令理...多模态模型# Seed GR-3# 字节跳动6个月前01650
SignGemma:谷歌推出全球最强手语翻译模型,为听障人群打开沟通新通道谷歌近日宣布推出全新 AI 模型 SignGemma,作为 Gemma 家族的新成员,它专注于将手语(尤其是美式手语 ASL)翻译成英文文本或语音输出,是目前最强大的开源手语理解模型之一。 SignG...多模态模型# SignGemma# 手语翻译模型8个月前01620
谷歌推出新型 AI 模型Gemini 2.5 Computer Use,可操作浏览器完成网页任务谷歌发布一款名为 Gemini 2.5 Computer Use 的新型 AI 模型,能够通过浏览器窗口执行点击、滚动、输入文本等交互操作,帮助用户在那些没有开放 API 的网站上自动完成任务。 这项...多模态模型# Gemini 2.5 Computer Use# 谷歌4个月前01580
ColQwen2.5-Omni:首个支持视觉+音频检索的ColBERT风格模型ColQwen2.5-Omni 是基于 Qwen2.5-Omni-3B-Instruct 的新一代多模态检索模型。该模型采用 ColBERT 策略,支持从图像、音频等多模态内容中高效检索信息,是目前首...多模态模型# ColQwen2.5-Omni7个月前01560