Sesame 团队推出新一代语音技术 CSM:让语音助手更像真人Sesame 团队近期发布了一项名为 Conversational Speech Model (CSM) 的全新语音技术,旨在解决当前语音助手普遍存在的“死板”问题。这项技术的目标是让语音助手不仅能够...语音模型# CSM# 语音技术11个月前03390
aiOla发布了集成命名实体识别(NER)和自动语音识别(ASR)的新型模型WhisperNER语音识别技术在过去几年取得了显著进展,AI的进步大大提高了其可访问性和准确性。然而,该技术仍面临一些挑战,特别是在理解和转录人名、地点和特定术语等口语实体方面。这些挑战不仅在于准确地将语音转换为文本...语音模型# aiOla# WhisperNER# 自动语音识别12个月前03390
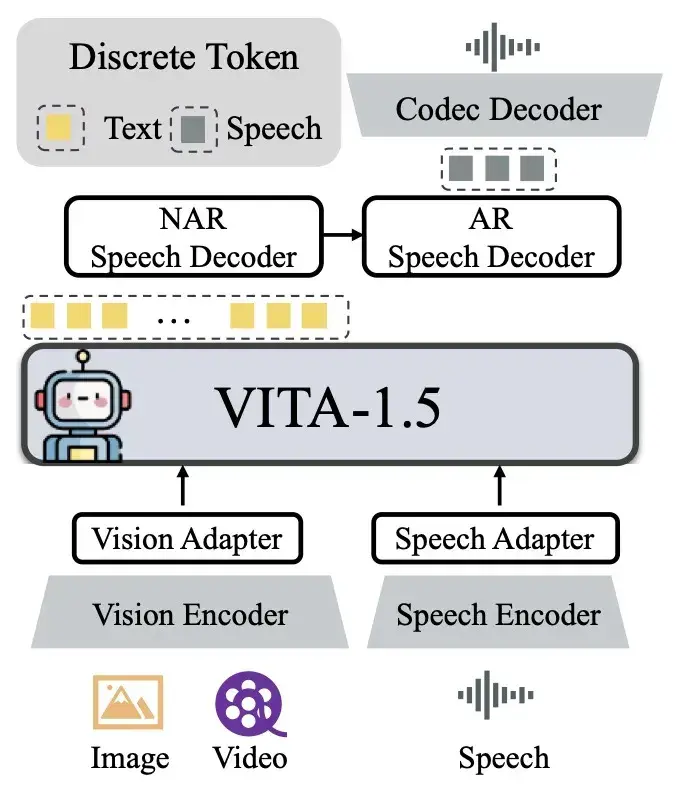
开源多模态视频语音大模型VITA-1.5: 基于Qwen2.5模型,实现接近实时的视觉和语音交互能力随着多模态大语言模型(MLLMs)的发展,如何有效地整合视觉、语言和语音成为了人工智能领域面临的一个重要挑战。VITA-1.5 是由南京大学(NJU)、腾讯优图实验室(Tencent Youtu La...语音模型# Qwen2.5模型# VITA-1.512个月前03360
北京沐言智语科技开源专为播客场景优化的可训练TTS模型 Muyan-TTS 北京沐言智语科技开源可训练文本到语音(TTS)模型 Muyan-TTS ,专为播客场景优化,并在5万美元的预算内开发。该模型通过在超过10万小时的播客音频数据上进行预训练,能够实现高质量的零样本文本到...语音模型# Muyan-TTS# TTS模型9个月前03330
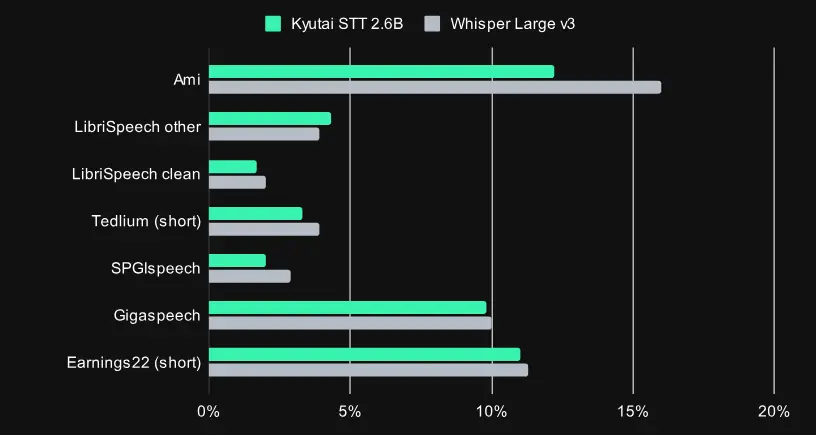
Kyutai STT:低延迟、高吞吐的流式语音识别模型,专为实时交互优化近日,Kyutai 实验室发布了一款全新的流式语音转文本(Speech-to-Text)模型——Kyutai STT,专为实时语音交互场景设计,在延迟与准确性之间实现了出色平衡,非常适合如语音助手、在...语音模型# Kyutai STT# 语音识别模型7个月前03240
Resemble AI推出首个情感可控的开源TTS模型ChatterboxResemble AI正式发布了其首个生产级开源TTS模型——Chatterbox。这是目前市面上少有的、具备高质量语音合成能力并支持情感控制的开源项目。目前仅支持英文。 GitHub:https...语音模型# Chatterbox# Resemble AI# TTS模型5个月前03230
高效语音分离模型TIGER:解决低延迟语音处理系统中的高效率问题清华大学的研究人员推出高效语音分离模型TIGER,解决低延迟语音处理系统中的高效率问题。语音分离是指从混合音频信号中准确分离出不同声音源的任务,类似于人类在嘈杂环境中专注于特定语音信号的“鸡尾酒会效应...语音模型# TIGeR# 语音分离模型8个月前03200
阿里巴巴语音实验室发布开源语音处理框架 ClearerVoice-Studio:支持语音增强、分离和目标说话人提取在当今的音频环境中,清晰沟通面临诸多挑战。背景噪音、重叠对话以及音频和视频信号的混合等因素常常破坏了沟通的清晰度和理解力。这些问题不仅影响个人通话,还波及专业会议和内容制作等场景。尽管音频技术有所进步...语音模型# ClearerVoice-Studio# 阿里巴巴12个月前03200
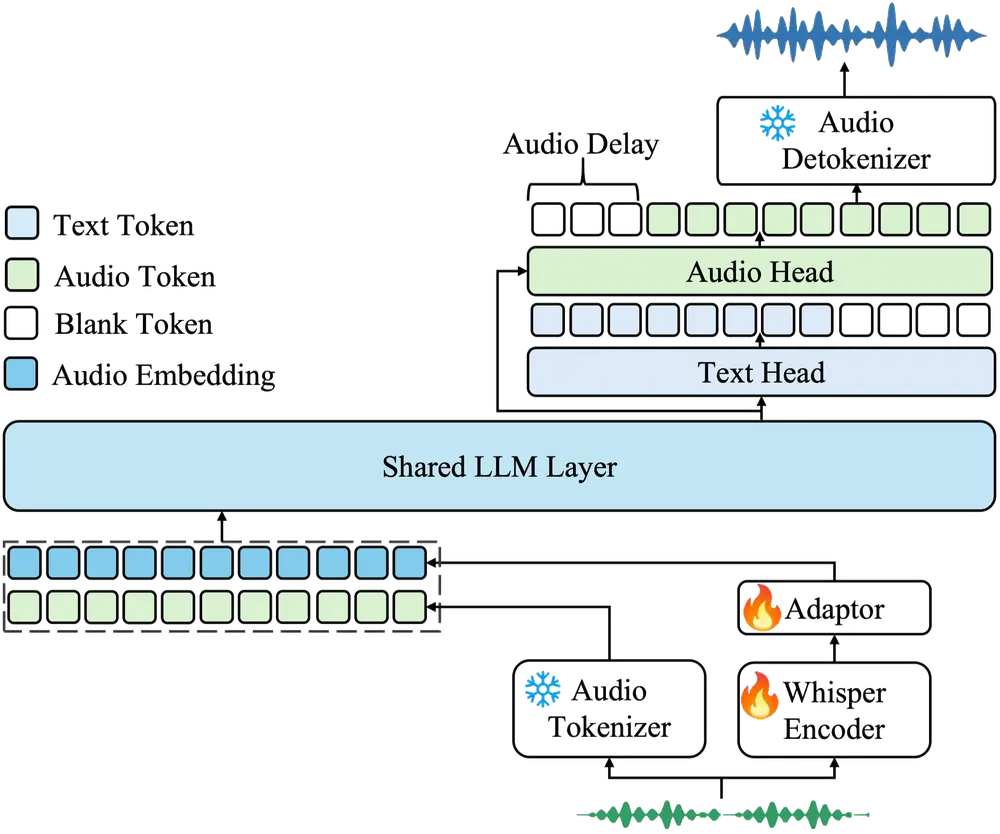
月之暗面开源端到端语音对话的通用音频模型Kimi-Audio月之暗面开源了一款名为 Kimi-Audio 的通用音频模型。这款模型以其统一的框架和强大的多功能性,在音频处理领域引起了广泛关注。Kimi-Audio 不仅能够处理语音识别、音频问答、字幕生成等任务...语音模型# Kimi-Audio# 月之暗面9个月前03050
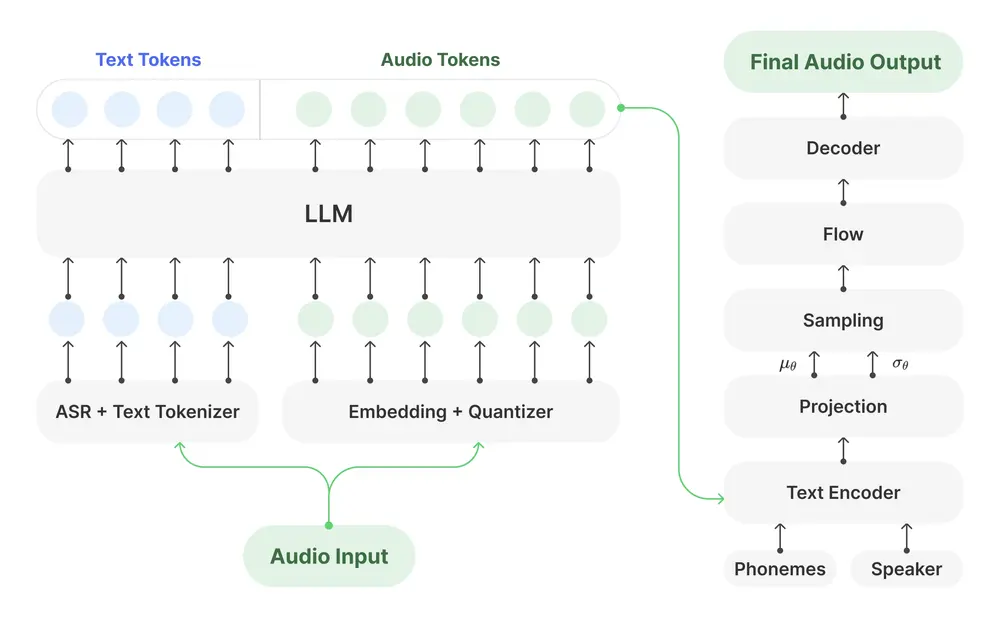
字节跳动发布 Seed LiveInterpret 2.0:首个中英同传延迟与准确率接近人类水平的端到端语音翻译系统在跨语言实时沟通的长期挑战中,机器能否真正替代人类同声传译?字节跳动 Seed 团队给出了迄今为止最接近“是”的答案。 今日,字节跳动正式发布 Seed LiveInterpret 2.0 —— 一款...语音模型# Seed LiveInterpret 2.0# 同声传译模型# 字节跳动6个月前03040
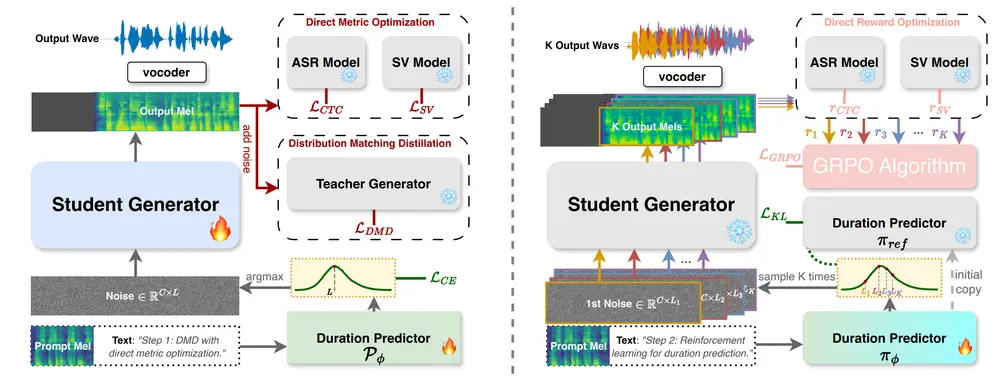
DMOSpeech 2:用强化学习优化语音合成的时长预测在零样本文本到语音(TTS)领域,基于扩散模型的系统近年来取得了显著进展。然而,大多数方法仍难以实现对整个生成流程的端到端感知质量优化——尤其是时长预测这一关键组件,长期依赖自监督训练,未能与语音生成...语音模型# DMOSpeech 2# TTS 框架6个月前03030
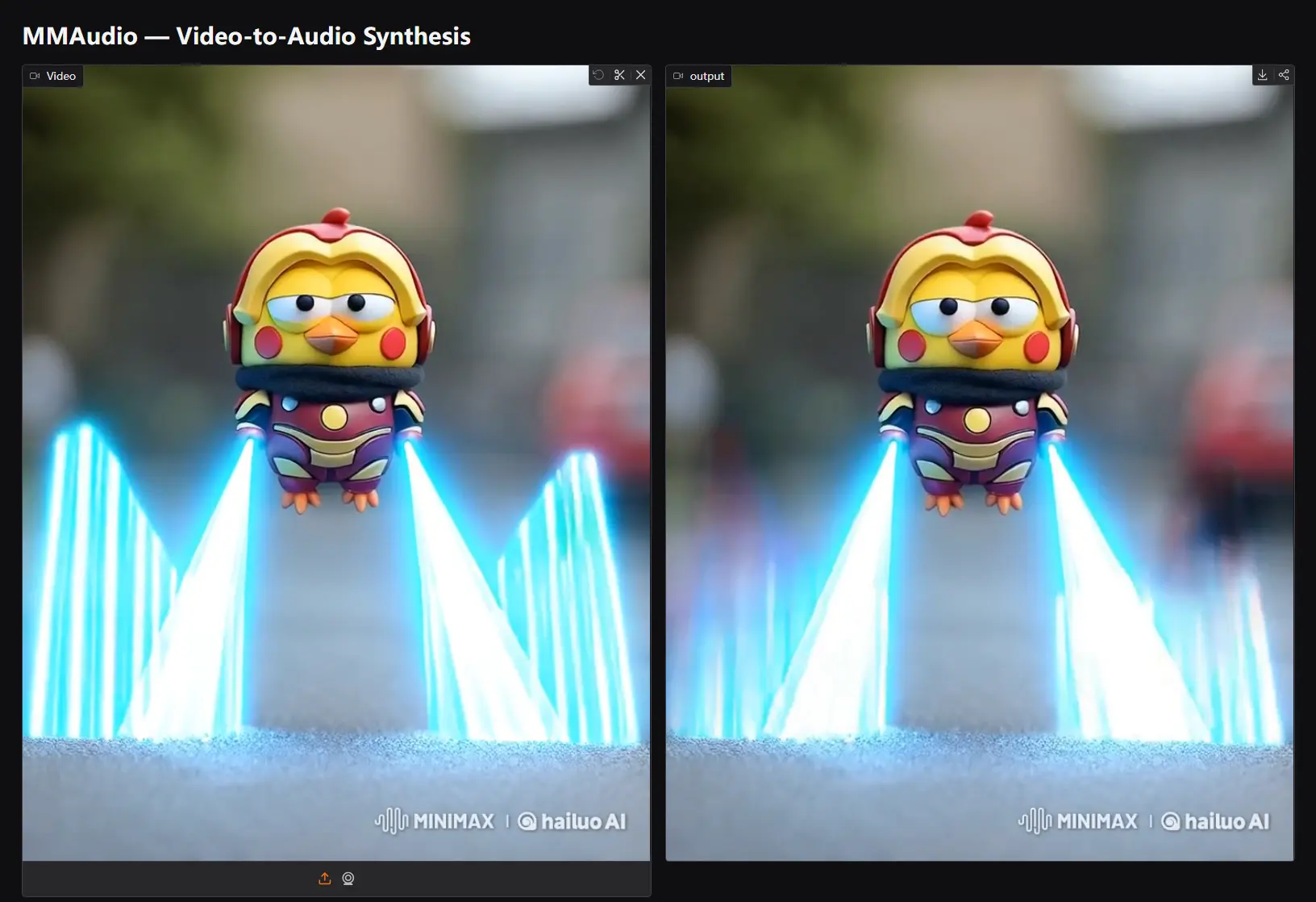
MMAudio:基于多模态联合训练的同步音频生成系统近年来,多模态生成模型在图像、视频和文本等领域取得了显著进展,但将视觉和文本信息与音频生成结合的任务仍然具有挑战性。传统的音频生成方法通常依赖于单一模态(如仅基于文本或仅基于视频),难以实现高质量的音...语音模型# MMAudio# 音频生成12个月前03020