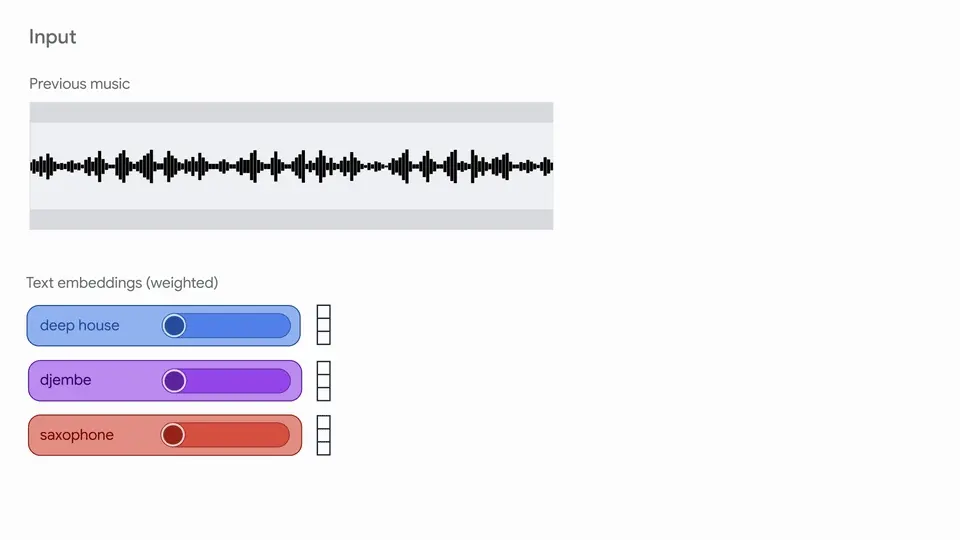
谷歌开源实时音乐生成模型 Magenta RealTime:8亿参数,支持文本/音频操控今天,Google DeepMind 宣布开源一款名为 Magenta RealTime 的实时音乐生成模型。该模型基于 Apache 2.0 许可证发布,具备实时交互能力,能够根据文本提示或音频示例...语音模型# Magenta RealTime# 音乐生成模型7个月前03010
SparkAudio推出Spark-TTS:基于大语言模型的高效文本到语音系统香港科技大学、SparkAudio开源社区、上海出门问问信息技术有限公司、上海交通大学、南洋理工大学、西北工业大学和网易伏羲人工智能实验室的研究人员推出Spark-TTS,这是一个基于大语言模型(LL...语音模型# Spark-TTS# SparkAudio# 文本到语音11个月前02980
ElevenLabs 推出语音转文本模型 Scribe,多语言支持与高精度ElevenLabs 是一家专注于人工智能音频生成的初创公司,最近筹集了 1.8 亿美元的资金,估值达到 33 亿美元。以其高质量的声音合成技术而闻名,该公司现在正通过推出其首个独立的语音转文本模型 ...语音模型# ElevenLabs# Scribe# 语音识别11个月前02940
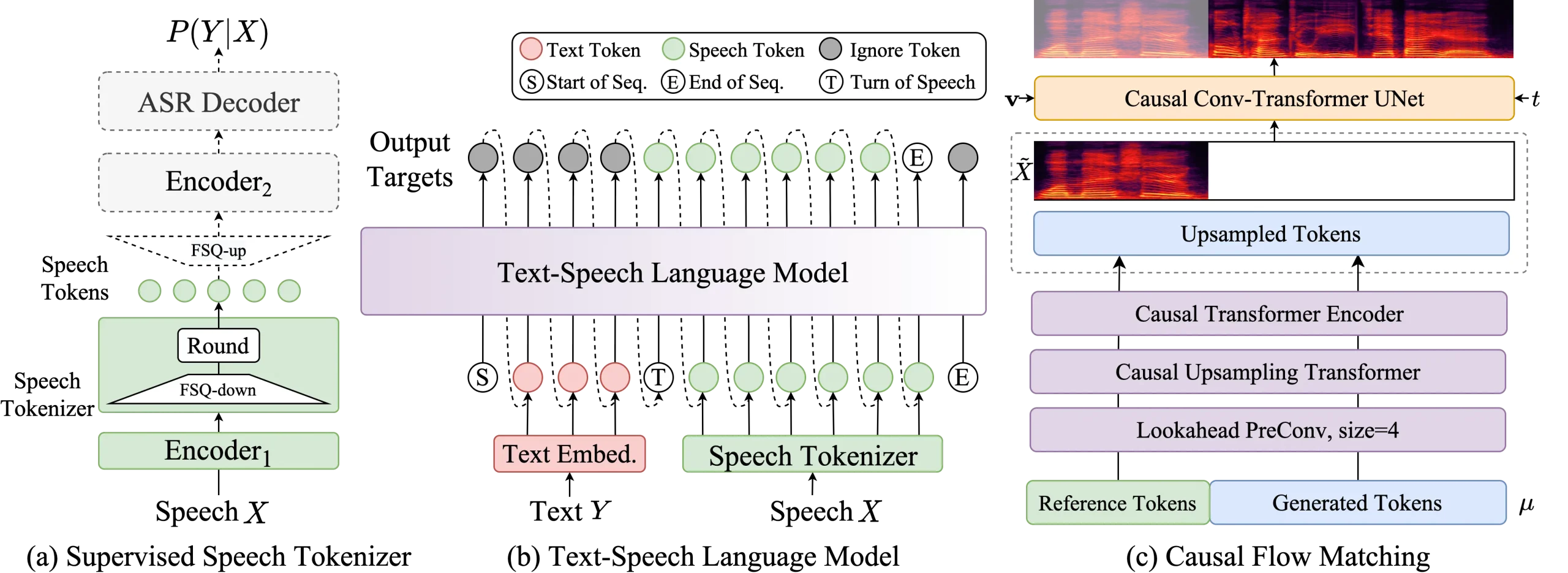
小红书开源 FireRedChat:一个完整、可控的全双工语音交互系统在智能助手和客户服务场景中,用户希望与AI的对话像人与人交流一样自然——可以随时插话、打断、继续,而系统能即时响应。要实现这种体验,需要真正的全双工语音交互能力。 然而,现有方案存在明显短板: 端到端...语音模型# FireRedChat# 小红书4个月前02870
通义语音团队推出语音生成模型CosyVoice 2:提升了多语言语音合成的质量、响应速度和实时性能阿里巴巴旗下通义实验室语音团队在之前提出的 CosyVoice 基础上,推出了全新的 CosyVoice 2。该模型通过一系列优化和创新,显著提升了多语言语音合成的质量、响应速度和实时性能。CosyV...语音模型# CosyVoice 2# 语音生成模型12个月前02860
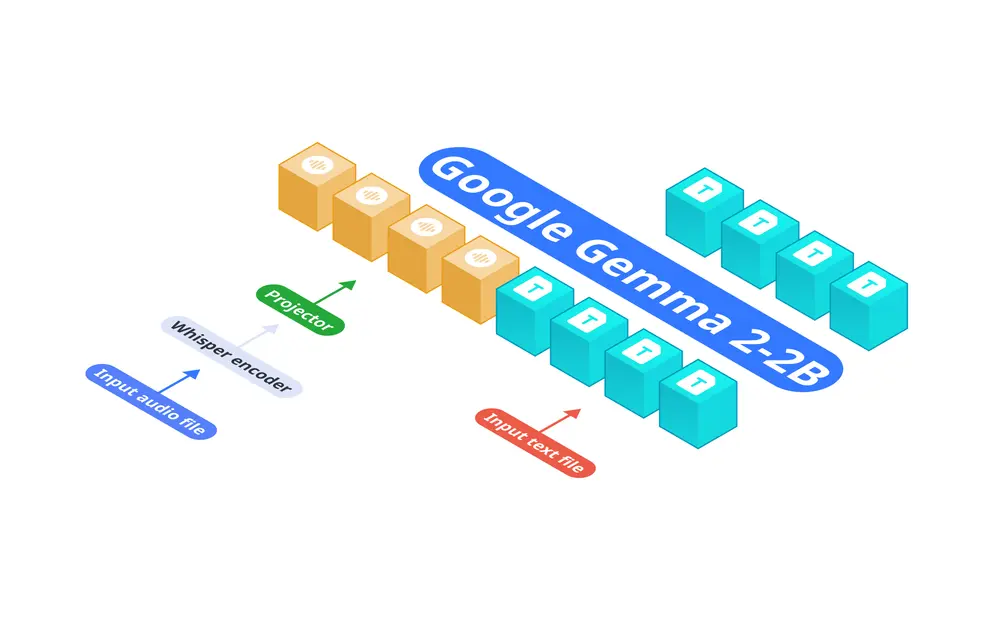
Nexa AI 推出一款专为边缘部署设计的音频语言模型 OmniAudio-2.6B音频语言模型(ALMs)在各种应用中发挥着关键作用,包括实时转录、翻译、语音控制系统和辅助技术。然而,许多现有解决方案面临高延迟、大量计算需求以及依赖云端处理等限制。这些问题对边缘部署提出了挑战,因为...语音模型# OmniAudio-2.6B12个月前02780
中科院团队推出多模态新模型 Stream-Omni,语音+视觉交互更高效由中国科学院计算技术研究所智能信息处理重点实验室、中国科学院人工智能安全重点实验室以及中国科学院大学联合提出,Stream-Omni 是一种新型的语言-视觉-语音多模态模型。该模型通过高效的模态对齐机...语音模型# Stream-Omni# 语言-视觉-语音多模态模型8个月前02690
Hume AI推出了首个理解其所说内容的文本转语音系统OctaveHume 推出了 Octave(全能文本和语音引擎),这是首个专为文本转语音设计的大语言模型(LLM)。与传统文本转语音(TTS)系统不同,Octave 不仅能够“朗读”文字,还能真正理解单词在上下文...语音模型# Hume AI# Octave# TTS11个月前02670
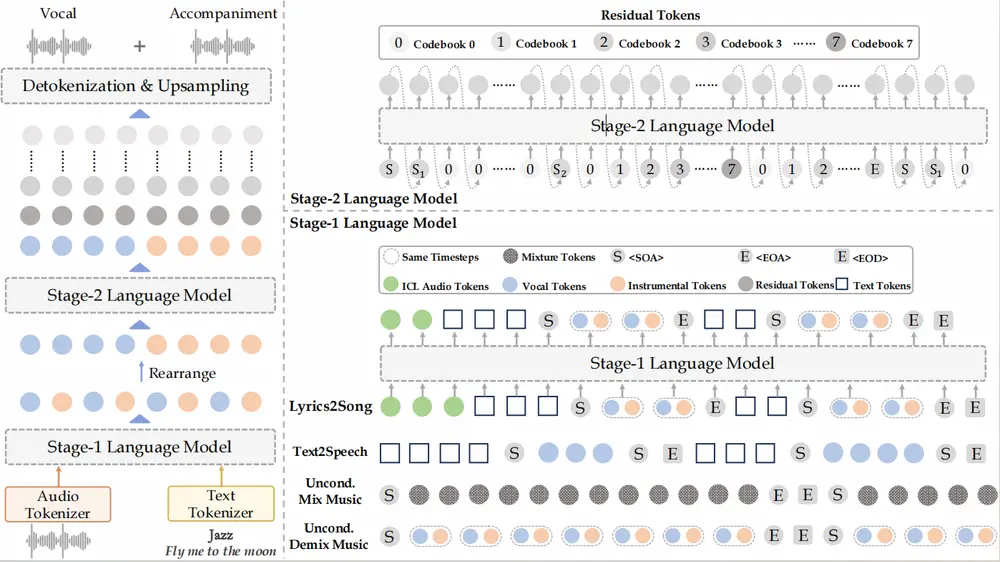
香港科技大学推出歌词生成音乐模型YuE香港科技大学的研究团队近期在探索从给定歌词生成完整歌曲音频的领域取得了重要进展,这一过程被称为“歌词到歌曲”(lyrics2song)。尽管基于文本条件的音乐生成模型在创作非人声音乐短片段方面已经展现...语音模型# AI音乐# YuE12个月前02670
昆仑万维推出 SkyReels-Audio:多模态驱动、无限长度的高质量会说话肖像视频生成框架昆仑万维旗下 SkyReels 团队 发布了全新音视频生成模型——SkyReals-Audio,一个用于合成高保真、时间一致的“会说话”肖像视频的统一框架。 项目主页:https://skyworka...语音模型# SkyReels-Audio# 昆仑万维8个月前02580
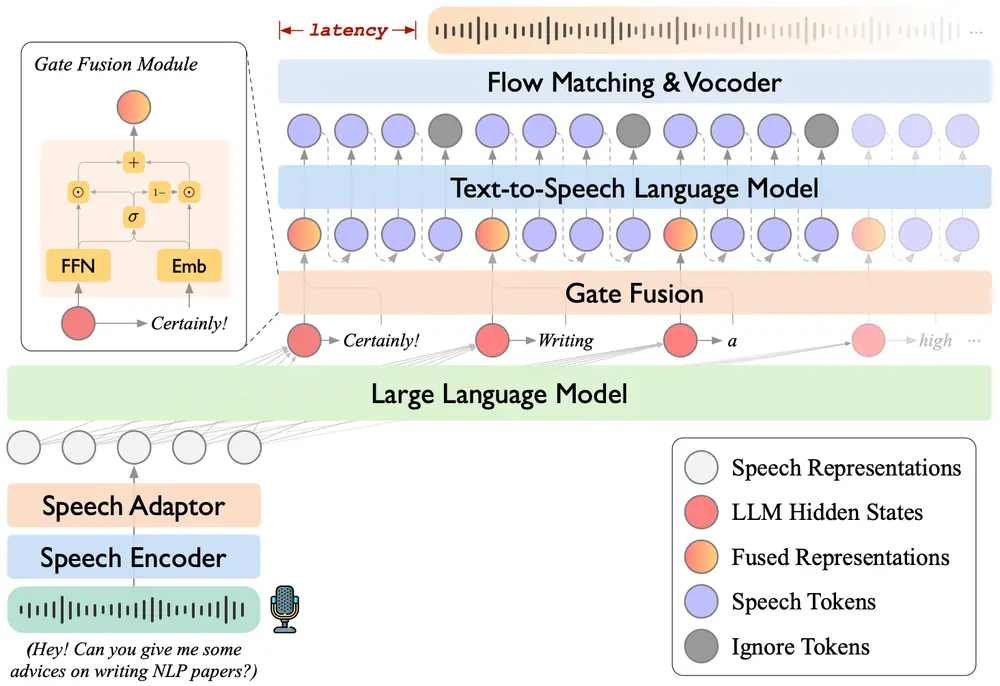
新型语音语言模型 LLaMA-Omni 2:实现高质量的实时语音交互中国科学院计算技术研究所、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出新型语音语言模型 LLaMA-Omni 2 ,旨在实现高质量的实时语音交互。LLaMA-Omni 2 基于 Qw...语音模型# LLaMA-Omni 2# 语音语言模型9个月前02530
清华、腾讯等联合推出基于语言模型的高质量歌曲生成框架 LeVo随着大语言模型(LLMs)和音频语言模型的快速发展,AI 在音乐生成领域的能力显著提升,特别是在 歌词到歌曲生成 的方向上取得了突破性进展。 然而,现有方法仍面临两大核心挑战: 歌曲结构复杂,难以同时...语音模型# LeVo# SongGeneration# 音乐生成8个月前02510