Mini-Omni-Reasoner:将推理能力引入大型语音模型,让语音模型“边说边思考”由南洋理工大学、新加坡国立大学、腾讯、北京工业大学与北京航空航天大学联合研发,Mini-Omni-Reasoner 正式推出——这是一次将推理能力引入大型语音模型(Large Speech Model...语音模型# Mini-Omni-Reasoner# 语音思考模型4个月前02500
Kyutai Labs推出新一代流式TTS模型Kyutai TTS:实时语音生成迈入新阶段近日,Kyutai Labs 正式开源了一款名为 Kyutai TTS 的文本转语音(TTS)模型,参数规模达到16亿,支持实时、流式处理,成为该领域的技术新标杆。这一模型不仅具备出色的语音生成能力...语音模型# Kyutai Labs# Kyutai TTS# TTS模型7个月前02500
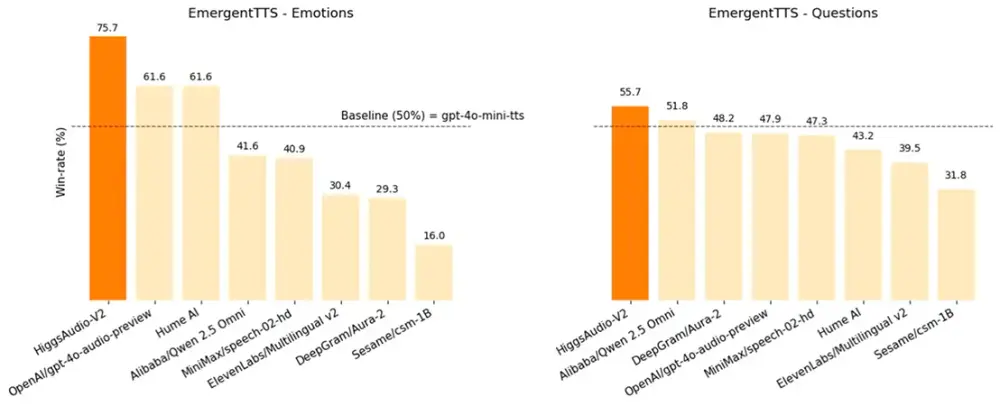
Boson AI 发布 Higgs Audio V2:首个开源的多说话者情感语音生成模型Boson AI 正式推出 Higgs Audio Generation 版本2(Higgs Audio V2),这是Boson AI在音频生成领域的一次重要突破。该模型具备强大的多说话者对话生成能力...语音模型# Boson AI# Higgs Audio V26个月前02450
Zyphra开源支持高保真语音克隆的实时文本转语音(TTS)模型 Zonos-v0.1 测试版Zyphra 最近发布了 Zonos-v0.1 测试版,这是一款支持高保真语音克隆的实时文本转语音(TTS)模型。作为开源项目的一部分,Zonos-v0.1 包含两个强大的 TTS 模型:一个 16 ...语音模型# TTS模型# Zonos-v0.112个月前02420
Orpheus TTS:基于 Llama-3b 构建的先进文本转语音(TTS)模型Canopy Labs推出基于 Llama-3b 骨干网络构建的开源文本转语音(TTS)模型Orpheus TTS ,这款模型展示了利用大语言模型(LLM)进行高质量语音合成的能力。 模型规模与特性 ...语音模型# Llama-3b# Orpheus TTS# TTS11个月前02410
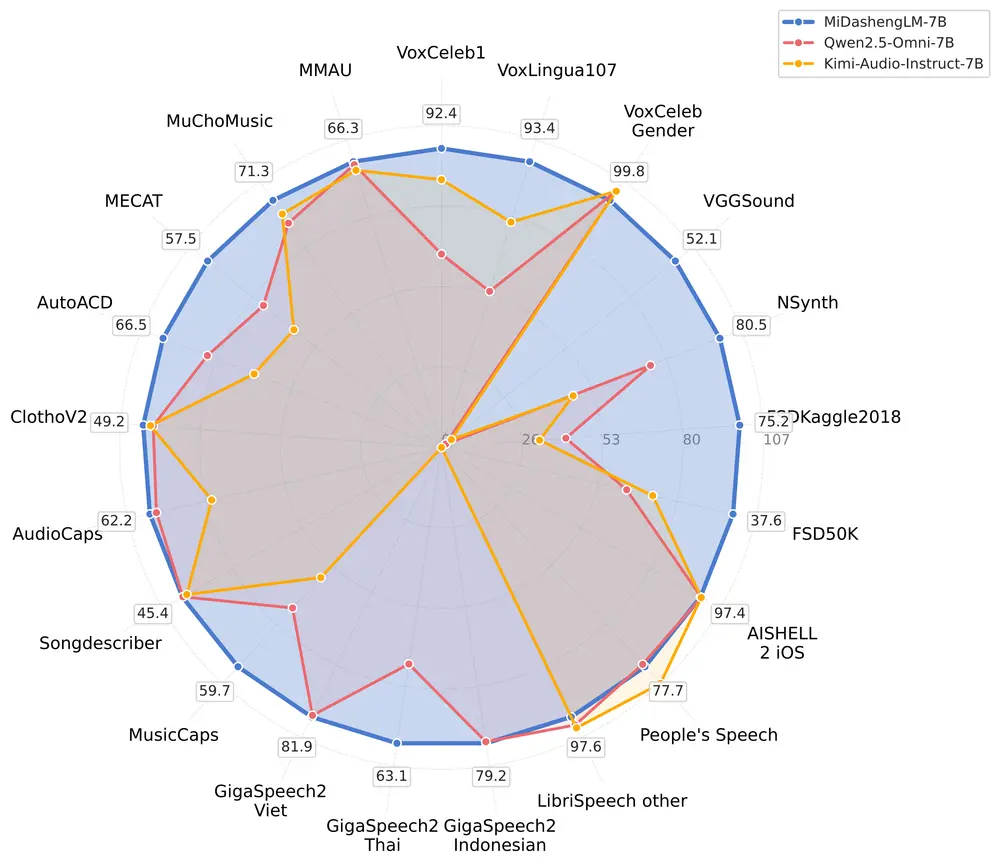
小米自研声音理解大模型 MiDashengLM-7B 正式开源小米正式发布并全量开源其自研声音理解大模型 —— MiDashengLM-7B。该模型在性能与效率上实现双重突破,标志着小米在多模态AI领域,尤其是声音理解方向的又一次重要进展。 GitHub 主页...语音模型# MiDashengLM-7B# 声音理解大模型# 小米6个月前02400
Qwen3-TTS-Flash 发布:支持多音色、多语言与多方言的语音合成模型通义实验室近日推出 Qwen3-TTS-Flash,一款面向多场景应用的高性能文本转语音(TTS)模型。该模型现已通过 Qwen API 开放访问,支持自然、流畅且富有表现力的语音生成。 API:ht...语音模型# Qwen3-TTS-Flash# 语音合成模型4个月前02340
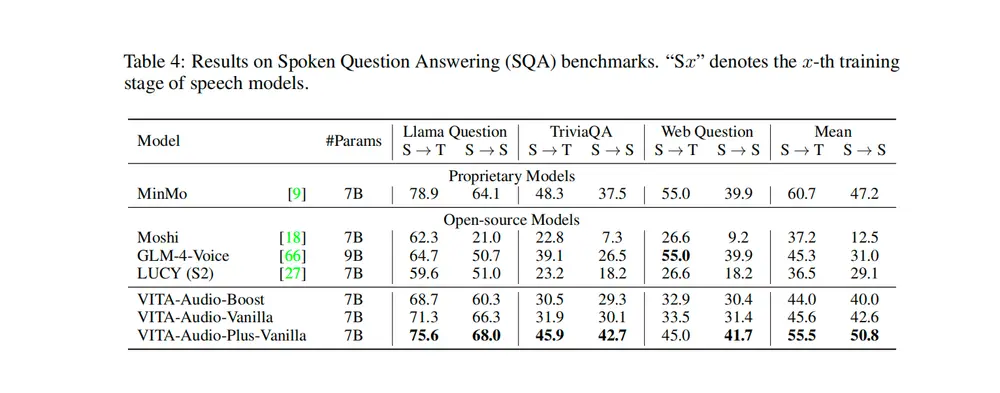
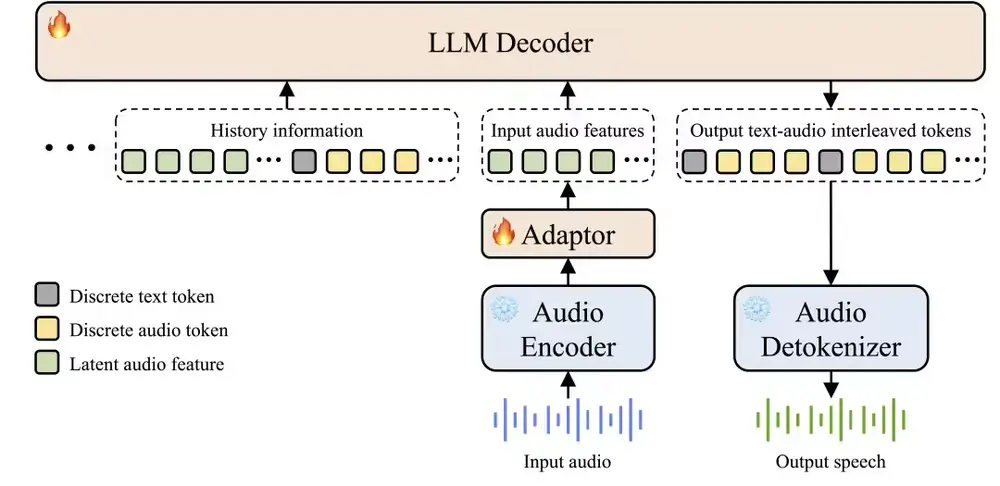
多模态语音交互的端到端大型语音模型 VITA-Audio腾讯优图实验室、南京大学和厦门大学的研究人员推出用于高效多模态语音交互的端到端大型语音模型 VITA-Audio,VITA-Audio 的目标是通过快速生成音频和文本令牌,显著降低流式语音交互中的延迟...语音模型# VITA-Audio# 语音模型9个月前02290
Stability AI发布可在智能手机运行的音频生成模型Stable Audio Open SmallAI 初创公司 Stability AI 发布了 Stable Audio Open Small,这是一款专为移动设备设计的音频生成模型。据公司宣称,这是目前市场上最快的音频生成模型,并且效率高到可以...语音模型# Stability AI# Stable Audio Open Small9个月前02150
阶跃星辰发布开源语音大模型Step-Audio 2 mini:多任务性能登顶SOTA,攻克语音AI“智商情商”痛点今日,阶跃星辰正式发布开源端到端语音大模型Step-Audio 2 mini,该模型在音频理解、语音识别、翻译及对话等多个国际基准测试集中均斩获SOTA(state-of-the-art,当前最优)成...语音模型# Step-Audio 2 mini# 阶跃星辰5个月前02140
小米发布 MiMo-Audio:基于亿级小时预训练的开源音频语言模型小米近日正式推出 MiMo-Audio ——一个统一的生成式音频-语言模型,支持跨模态语音理解与生成任务。该模型通过超过一亿小时的大规模预训练,实现了强大的少样本学习能力,能够在无需微调的情况下,仅凭...语音模型# MiMo-Audio# 小米# 音频语言模型4个月前02080
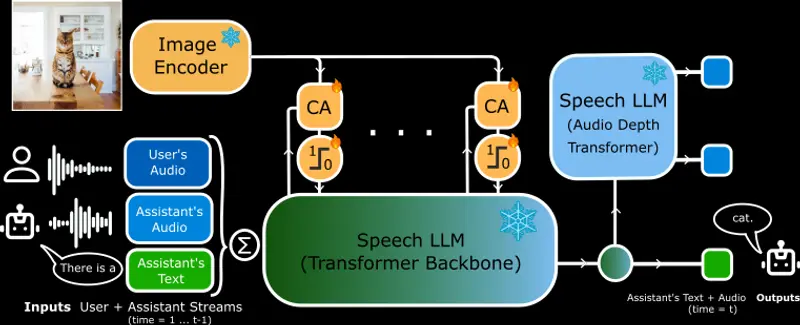
Kyutai发布首个开源实时语音模型MoshiVis,开启视觉与语音交互新时代在AI领域,将实时语音交互与视觉内容相结合一直是一个极具挑战性的课题。传统系统通常依赖于多个独立组件来实现语音活动检测、语音识别、文本对话和文本转语音合成,这种分段式的方法不仅容易引入延迟,还难以捕捉...语音模型# MoshiVis# 语音模型10个月前02030