文本转语音模型Kokoro-82M:8200万参数,支持多语言和多声音选项Kokoro是一款先进的文本转语音(TTS)模型,以其精简的参数量和卓越的性能在众多竞争对手中脱颖而出。拥有8200万参数的Kokoro,其模型大小不超过300M,却能生成高质量的音频输出。特别值得一...语音模型# Kokoro-82M# TTS12个月前03,5040
Nari Labs开源TTS模型Dia-1.6B:生成自然对话与非语言表达,支持声音克隆Nari Labs在今天开源了一个拥有16亿参数的文本转语音模型Dia-1.6B。这个模型的最大亮点在于它能够生成高度逼真的对话,并且加入了自然人声元素,比如笑声、咳嗽、清喉咙等,让语音合成更加生动自...语音模型# Dia-1.6B# Nari Labs# TTS模型9个月前02,2170
Rev推出开源自动语音识别模型Reverb和话者分离模型Rev 最近宣布开源其尖端的 Reverb 自动语音识别 (ASR) 和话者分离模型。经过 200,000 小时高质量人工转录的英语语音训练,Reverb 在长篇语音识别领域中表现出色,超越了所有现有...语音模型# Reverb# 话者分离模型# 语音识别模型12个月前07520
阿里发布Qwen3-LiveTranslate-Flash :全球首个视、听、说全模态实时同传大模型阿里通义实验室今日推出 Qwen3-LiveTranslate-Flash——一款基于 Qwen3-Omni 基座模型打造的多语言实时音视频同声传译大模型。 Demo:https://huggingf...语音模型# Qwen3-LiveTranslate-Flash# 实时同传大模型4个月前06810
OpenAI 推出更快的语音转录模型Whisper large-v3-turbo,不牺牲质量、速度提升8 倍在10月1日的DevDay活动中,OpenAI宣布了一项重大更新:推出了Whisper large-v3-turbo语音转录模型。这款新模型在保持质量几乎不变的前提下,处理速度比之前的large-v3...语音模型# OpenAI# Whisper large-v3-turbo# 语音转录模型12个月前06800
Fish Audio 发布 OpenAudio S1-mini:支持 14 种语言、50+ 情感语气的开源 TTS 模型文本转语音(TTS)领域迎来一位重量级开源选手 —— OpenAudio S1-mini。 这是由 Fish Audio 团队 推出的 S1 模型的轻量化版本,参数规模为 5亿(0.5B),基于超过 ...语音模型# Fish Audio# OpenAudio S1-mini# TTS 模型8个月前06710
Useful开源自动语音识别 (ASR) 模型Moonshine:专门针对实时转录和语音命令处理进行了优化Useful开源了一款名为 Moonshine 的全新语音转文本模型。这款模型不仅在速度和效率上超越了目前最领先的 OpenAI 的 Whisper 模型,而且在准确率方面也达到了同等水平甚至更优。M...语音模型# Moonshine# 语音识别模型12个月前06650
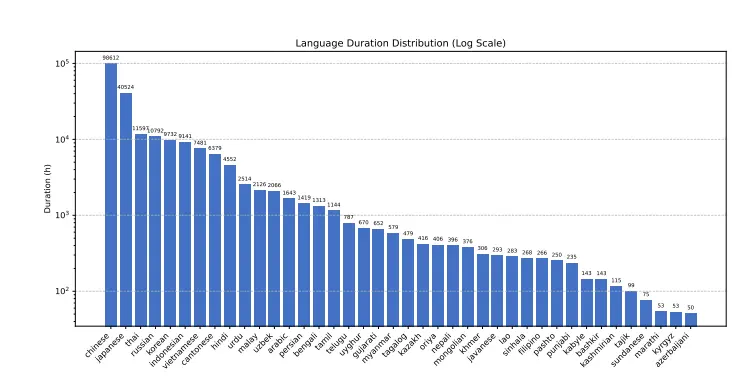
多语言、多任务 ASR 模型Dolphin:支持东亚、南亚、东南亚和中东地区的 40 种东方语言,同时也支持 22 种中国方言近年来,自动语音识别(ASR)技术取得了显著进展,这主要得益于模型架构的改进和大规模数据集的可用性。然而,现有的多语言 ASR 模型(如 Whisper)在处理东方语言时表现不佳,且存在可重复性问题 ...语音模型# ASR 模型# Dolphin# 语音识别10个月前06500
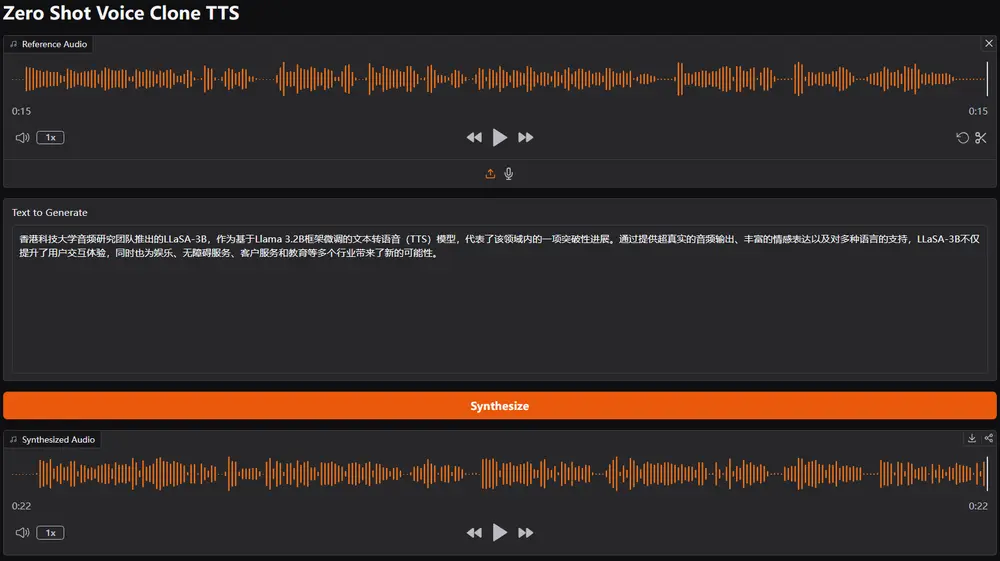
Llasa:基于LLaMA语言模型的先进文本转语音(TTS)系统文本转语音(TTS)技术正成为人机交互领域的重要工具。随着娱乐、无障碍服务、客户服务和教育等行业对语音合成的需求不断增加,市场对逼真、情感丰富且支持多种语言的语音合成技术的需求也在迅速增长。然而,传统...语音模型# Llasa# TTS12个月前06420
KittenML推出一个仅 25MB 的开源文本转语音模型Kitten TTSKittenML推出一款名为 Kitten TTS 的新型文本转语音(TTS)模型,它以极小体积、无需 GPU 和高质量语音合成能力为特点,专为边缘设备和轻量级部署场景设计。 GitHub:https...语音模型# Kitten TTS# 文本转语音模型6个月前05760
对话也能生成语音?复旦大学开源 MOSS-TTSD 实现高质量对话语音合成复旦大学 OpenMOSS 团队正式发布了全新语音生成模型 MOSS-TTSD(Text to Spoken Dialogue),这是目前首个能够直接从对话文本生成自然、富有表现力对话语音的大规模模型...语音模型# MOSS-TTSD# 复旦大学7个月前05750
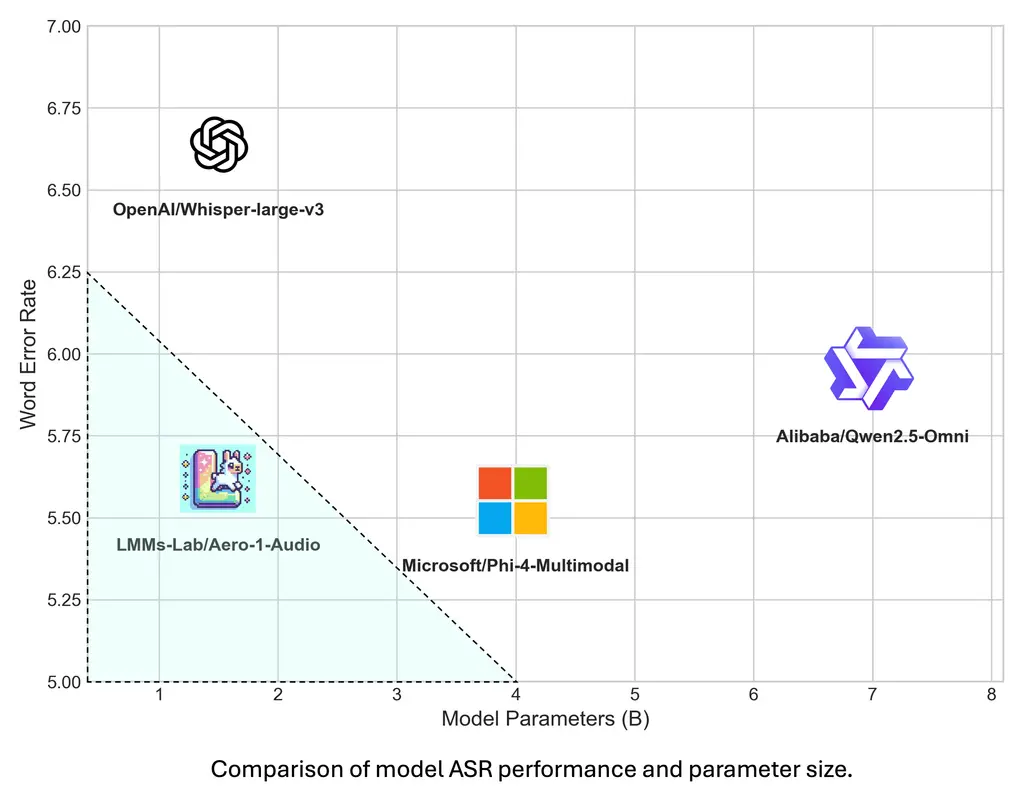
LMMs-Lab发布轻量高效音频模型Aero-1-Audio:擅长长语音ASR与多模态任务LMMs-Lab 推出了一款紧凑型音频模型 Aero-1-Audio,专为多种音频任务设计,包括语音识别(ASR)、音频理解和音频指令跟随。作为 Aero-1 系列的第一代产品,Aero-1-Audi...语音模型# Aero-1-Audio# LMMs-Lab# 语音识别9个月前05700