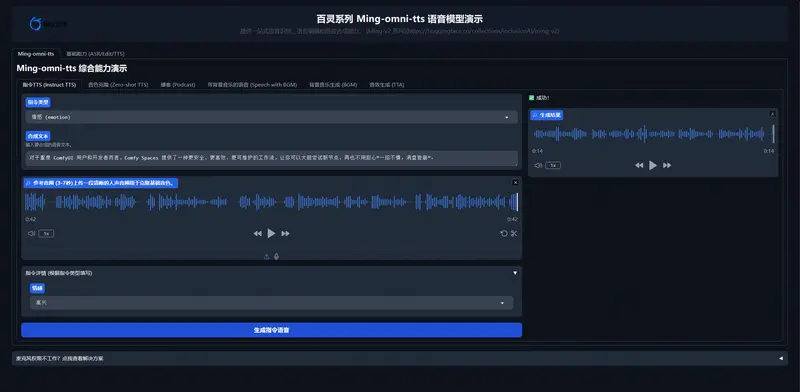
蚂蚁集团 inclusionAI 团队发布统一生成模型Ming-omni-tts:统一语音、音乐与声音生成,实现高精度细粒度可控音频合成蚂蚁集团 inclusionAI 团队近期正式发布了 Ming-omni-tts,这是一款设计简洁、运行高效的统一音频生成模型。它不仅可以在单一框架内合成高质量的语音,还能同时生成音乐与各类环境声音...语音模型# Ming-omni-tts# 统一生成模型1个月前0420
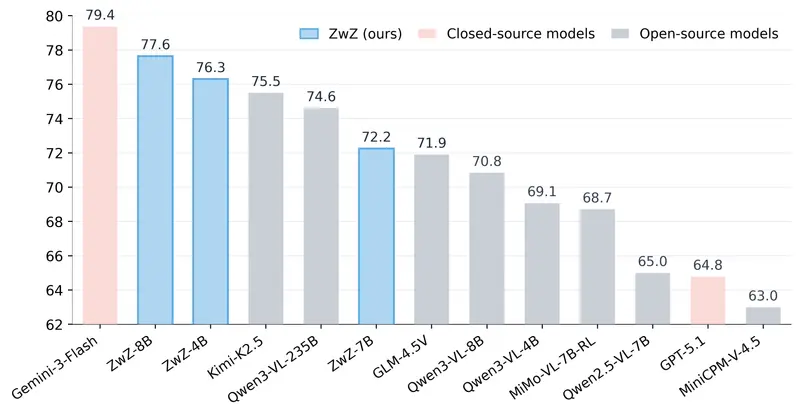
蚂蚁集团开源 ZwZ 模型:无需迭代缩放,单次 glance 实现细粒度多模态感知SOTA当前主流的“图像思考”方法,虽能通过迭代放大感兴趣区域提升细粒度感知能力,却存在致命短板——重复的工具调用与视觉重新编码,导致推理延迟居高不下,难以适配实际应用场景。 针对这一痛点,蚂蚁集团 incl...多模态模型# ZwZ# 蚂蚁集团1个月前0210
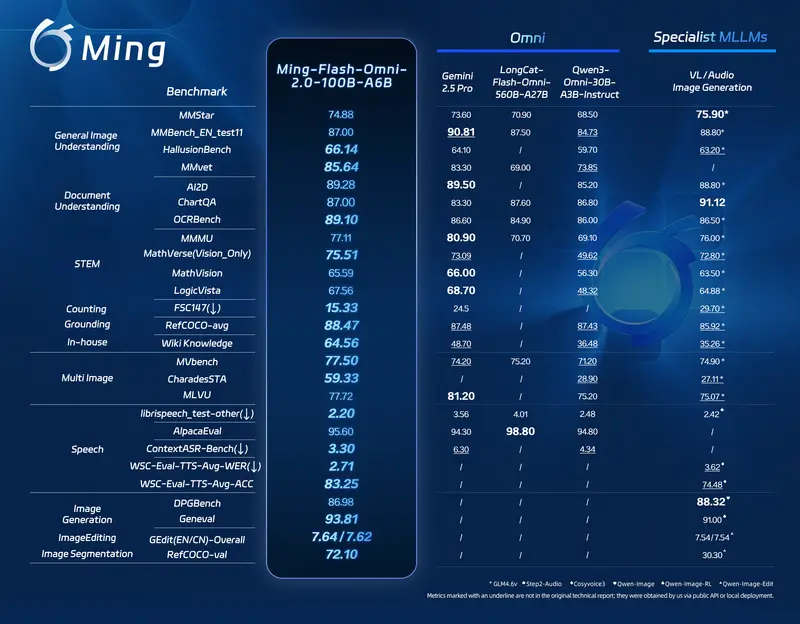
蚂蚁集团发布Ming-flash-omni 2.0 :100B MoE 多模态全能模型,支持视觉百科、沉浸式语音、高动态图像生成与编辑蚂蚁集团 inclusionAI 团队正式推出 Ming-flash-omni 2.0,搭载全新 Ling-2.0 混合专家(MoE)架构,以总参数 100B、激活参数 6B 的高效配置,在开源全能型...多模态模型# Ming-flash-omni 2.01个月前0110
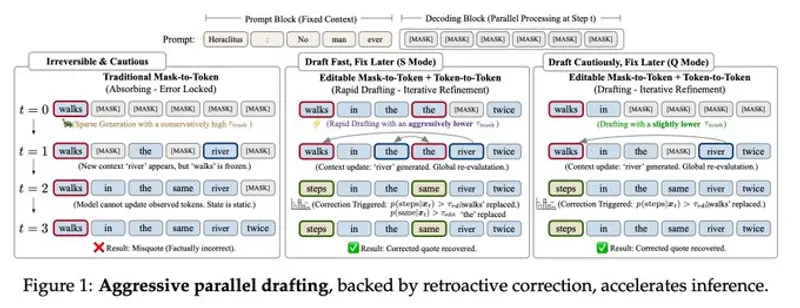
蚂蚁集团发布 LLaDA2.1:支持实时自我修正的开源扩散语言模型当大语言模型不再只能逐词生成,而是可以实时编辑自己已经生成的内容,会带来怎样的变革? 蚂蚁集团 inclusionAI 团队正式推出 LLaDA2.1——一款彻底打破自回归模型主导地位的文本扩散大模型...大语言模型# LLaDA2.1# 扩散语言模型1个月前0730
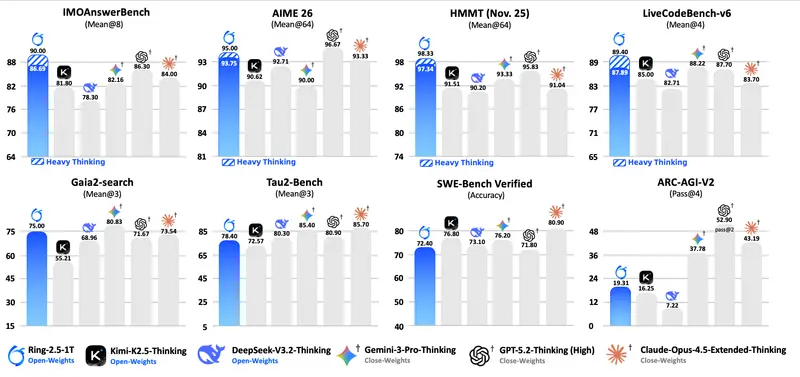
蚂蚁集团 inclusionAI 团队推出Ring-2.5-1T:全球首个万亿参数混合线性注意力思维模型蚂蚁集团 inclusionAI 团队正式推出 Ring-2.5-1T,这是全球首个基于混合线性注意力架构的开源万亿参数思维模型,标志着向通用人工智能体迈出关键一步。 Hugging Face :ht...大语言模型# Ring-2.5-1T# 蚂蚁集团1个月前01040
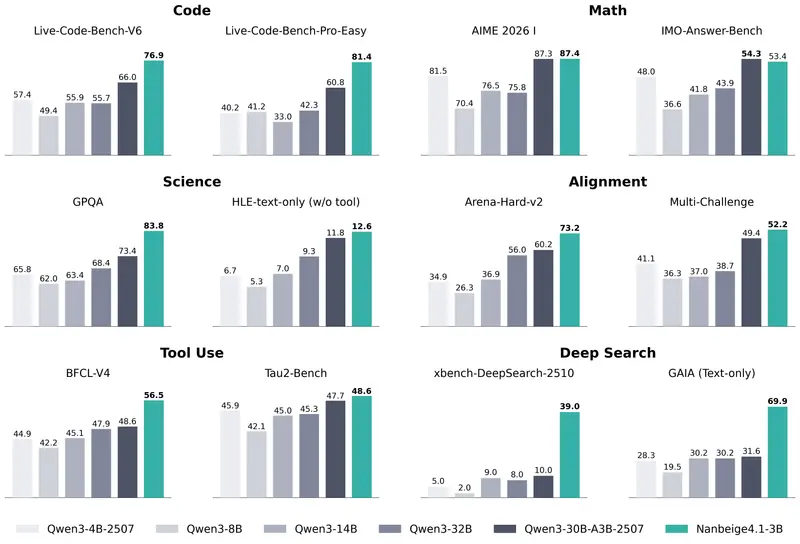
Nanbeige4.1-3B:在保持小参数规模的同时,实现强大推理、偏好对齐与高效智能体能力Nanbeige4.1-3B 基于 Nanbeige4-3B-Base 架构构建,是Nanbeige团队此前推出的推理专用模型 Nanbeige4-3B-Thinking-2511 的全面增强迭代版本...大语言模型# Nanbeige4.1-3B# 推理模型1个月前0420
图像编辑模型FireRed-Image-Edit:小红书团队出品,让图片编辑像说话一样简单小红书智能创作基础技术团队正式推出 FireRed-Image-Edit——一款通用图像编辑模型,凭借原生编辑架构、精准指令遵循能力,在广泛场景下实现高保真、视觉一致的编辑效果,既打破了专业修图的门槛...图像模型# FireRed-Image-Edit# 图像编辑模型# 小红书1个月前01860
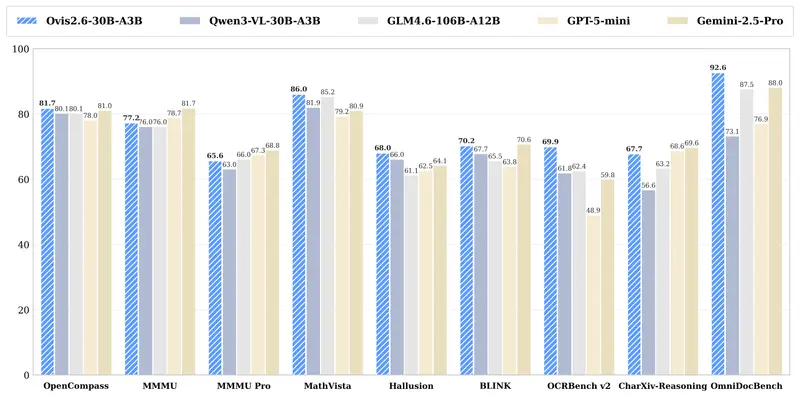
阿里国际发布 Ovis2.6-30B-A3B:MoE 架构多模态大模型,低成本实现高性能视觉理解阿里国际正式推出 Ovis2.6-30B-A3B 多模态大语言模型,作为 Ovis 系列的最新迭代版本,它在 Ovis2.5 基础上全面升级主干架构与多模态能力,以更低推理成本实现更强的长上下文、高分...多模态模型# Ovis2.6-30B-A3B# 多模态大模型1个月前0140
复杂运动、多模态参考、双声道音频!字节跳动正式发布Seedance 2.0:统一多模态架构, 支持导演级编辑的工业级音视频生成字节跳动正式推出新一代视频创作模型 Seedance 2.0。作为迭代升级后的重磅版本,它采用全新统一的多模态音视频联合生成架构,全面支持文本、图片、音频、视频四种模态输入,集成了当前行业内覆盖面最广...早报视频模型# Seedance 2.0# 字节跳动1个月前0160
MiniMax正式发布MiniMax M2.5 :更快、更强、更智能,专为现实生产力打造今天,MiniMax 正式推出全新一代大模型——MiniMax M2.5。这款模型依托在数十万个复杂真实世界环境中开展的大规模强化学习训练,实现了能力的全面升级。 在编程开发、智能体工具使用与信息搜索...大语言模型早报# MiniMax# MiniMax M2.51个月前02860
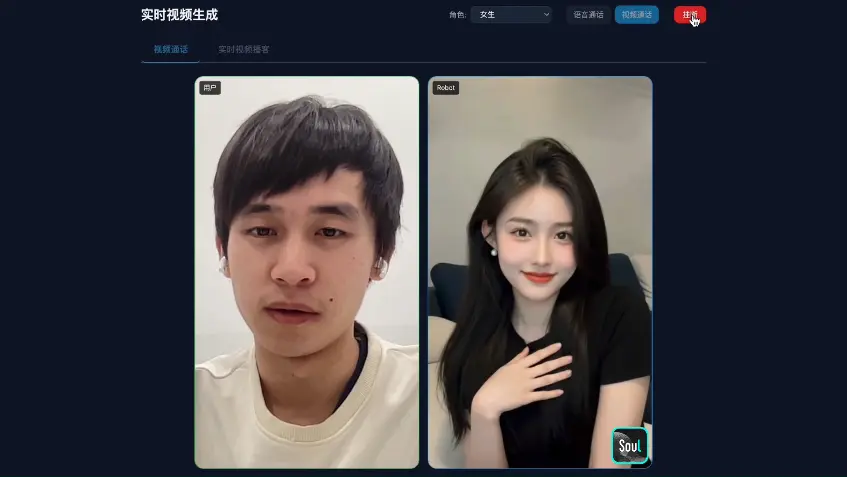
Soul AI Lab推出SoulX-FlashTalk :140 亿参数模型实现 0.87 秒启动、32 FPS 实时数字人直播当前 AI 数字人技术面临一个根本矛盾:高保真生成与实时性难以兼得。顶尖模型虽能生成逼真口型与表情,但因依赖多步迭代去噪,生成一秒钟视频常需数秒甚至更久,无法用于视频通话、直播带货等实时交互场景。更严...视频模型# Soul AI Lab# SoulX-FlashTalk# 数字人1个月前0310
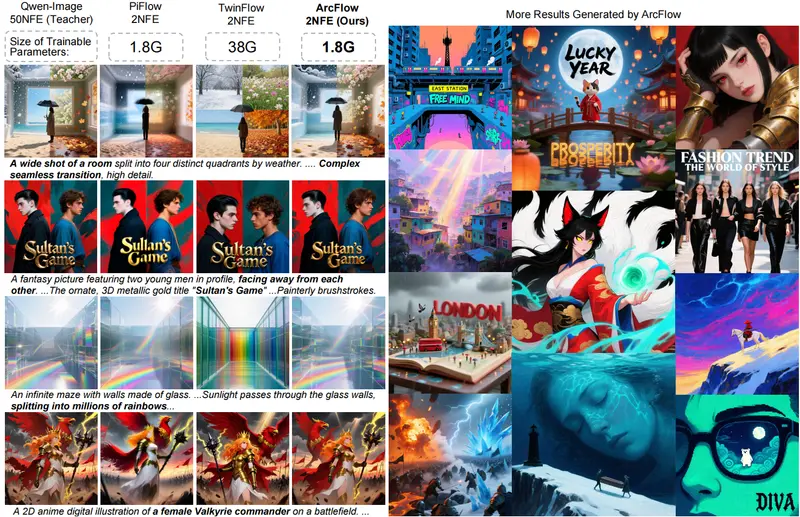
复旦与微软提出 ArcFlow:基于动量建模的非线性蒸馏框架,2 步生成高质量图像,加速 40 倍扩散模型凭借卓越的生成质量成为图像生成领域的核心技术,但40-100步的迭代去噪过程导致推理速度极慢,难以落地到实时应用场景。复旦大学与微软亚洲研究院联合提出的ArcFlow框架,通过非线性轨迹蒸馏的...图像模型# ArcFlow# 推理加速1个月前0360