
Nanbeige4.1-3B 基于 Nanbeige4-3B-Base 架构构建,是Nanbeige团队此前推出的推理专用模型 Nanbeige4-3B-Thinking-2511 的全面增强迭代版本。该模型通过进一步的监督微调(SFT)、强化学习后训练(RLHF)等多轮优化手段,实现了性能的全方位提升。作为一款在小参数规模(仅3B参数)下具备极强竞争力的开源模型。
Nanbeige4.1-3B 以实际性能打破了“小参数=弱性能”的固有认知,充分证明了紧凑型模型完全可以在保持轻量化部署优势的同时,同步达成强大的推理能力、稳健的偏好对齐效果以及高效可靠的智能体行为,为小模型生态的全能化发展提供了全新范式。
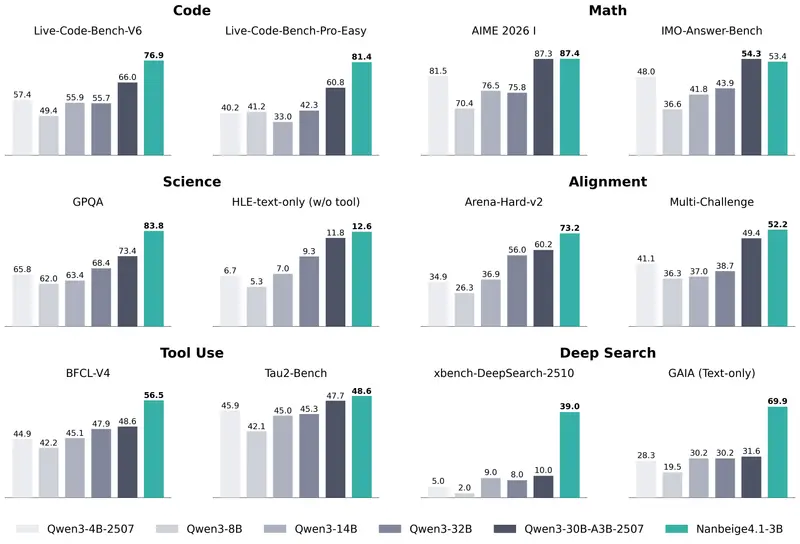
具体而言,Nanbeige4.1-3B 在三大核心能力维度展现出极具突破性的优势,每一项均针对小模型的传统短板进行了针对性优化,具体细节如下:
核心优势详解
一、强大推理能力:单次前向传播,搞定复杂多步骤问题
Nanbeige4.1-3B 最突出的提升的之一,是其具备的连贯且深度的推理能力——该模型能够在单次前向传播过程中,完成持续、逻辑严密的连贯推理,无需额外的多轮调用或外挂工具辅助,即可有效拆解并解决各类复杂的多步骤问题。这一特性使其在一系列高难度挑战性基准任务中表现亮眼,尤其是在 LiveCodeBench-Pro(编程推理)、IMO-Answer-Bench(数学竞赛)、AIME 2026 I(高阶数学推理)等对推理深度、逻辑连贯性要求极高的任务上,模型均能稳定、可靠地输出正确的最终答案,其推理稳定性与准确性可与参数规模远高于自身的模型相媲美,甚至实现超越。
二、稳健偏好对齐:越级表现,超越更大规模模型
偏好对齐是衡量模型实用性的核心指标之一,Nanbeige4.1-3B 在此维度实现了扎实且稳定的性能突破。通过优化的对齐训练策略,该模型能够精准捕捉人类的偏好需求,输出更贴合人类意图、更有用、更安全的回答。在 Arena-Hard-v2、Multi-Challenge 等两大权威偏好对齐基准上,Nanbeige4.1-3B 的表现尤为突出:不仅显著超越了同参数规模的主流模型(包括 Qwen3-4B-2507、Nanbeige4-3B-2511 等),同时也明显领先于包括 Qwen3-30B-A3B、Qwen3-32B 在内的更大参数规模模型,展现出极具竞争力的越级对齐能力,打破了“对齐性能依赖大参数”的传统认知。
三、高效智能体能力:填补空白,实现通用与智能体双优
Nanbeige4.1-3B 最具里程碑意义的突破,在于其实现了通用推理与智能体能力的统一,成为首个原生支持深度搜索任务,并能够可靠维持超过 500 轮工具调用以完成复杂问题求解的通用小参数模型。这一突破填补了小模型生态中长期存在的核心空白:在此之前,绝大多数小模型通常只能在“通用推理优化”和“智能体能力优化”之间二选一——要么专注于通用推理,缺乏工具调用与深度搜索能力;要么针对智能体场景专项优化,通用推理性能薄弱,极少有模型能够同时在两个方向上达到较高水准,而 Nanbeige4.1-3B 成功实现了两者的兼顾与双优,让轻量模型也能承担复杂的智能体任务。
性能表现:多维度权威基准评估
为全面验证 Nanbeige4.1-3B 的综合性能,我们在覆盖通用推理能力与深度搜索智能体能力两大核心维度的广泛、多样化权威基准上,对该模型进行了系统、严谨的评估。评估过程中,我们选取了同规模、更大规模的主流开源模型作为对照,确保评估结果的客观性与参考价值,具体评估数据如下:
一、通用推理任务评估
通用推理任务评估涵盖代码、数学、科学、偏好对齐、工具使用五大类核心任务,全面检验模型的综合推理能力。评估结果显示,Nanbeige4.1-3B 不仅在同参数规模模型中表现突出,其整体综合性能甚至优于包括 Qwen3-30B-A3B-2507、Qwen3-32B 在内的更大参数模型,具体数据对比详见下表:
| 基准 | Qwen3-4B-2507 | Qwen3-8B | Qwen3-14B | Qwen3-32B | Qwen3-30B-A3B-2507 | Nanbeige4-3B-2511 | Nanbeige4.1-3B |
|---|---|---|---|---|---|---|---|
| 代码 | |||||||
| Live-Code-Bench-V6 | 57.4 | 49.4 | 55.9 | 55.7 | 66.0 | 46.0 | 76.9 |
| Live-Code-Bench-Pro-Easy | 40.2 | 41.2 | 33.0 | 42.3 | 60.8 | 40.2 | 81.4 |
| Live-Code-Bench-Pro-Medium | 5.3 | 3.5 | 1.8 | 3.5 | 3.5 | 5.3 | 28.1 |
| 数学 | |||||||
| AIME 2026 I | 81.46 | 70.42 | 76.46 | 75.83 | 87.30 | 84.1 | 87.40 |
| HMMT Nov | 68.33 | 48.33 | 56.67 | 57.08 | 71.25 | 66.67 | 77.92 |
| IMO-Answer-Bench | 48.00 | 36.56 | 41.81 | 43.94 | 54.34 | 38.25 | 53.38 |
| 科学 | |||||||
| GPQA | 65.8 | 62.0 | 63.38 | 68.4 | 73.4 | 82.2 | 83.8 |
| HLE (纯文本) | 6.72 | 5.28 | 7.00 | 9.31 | 11.77 | 10.98 | 12.60 |
| 对齐 | |||||||
| Arena-Hard-v2 | 34.9 | 26.3 | 36.9 | 56.0 | 60.2 | 60.0 | 73.2 |
| Multi-Challenge | 41.14 | 36.30 | 36.97 | 38.72 | 49.40 | 41.20 | 52.21 |
| 工具使用 | |||||||
| BFCL-V4 | 44.87 | 42.20 | 45.14 | 47.90 | 48.6 | 53.8 | 56.50 |
| Tau2-Bench | 45.9 | 42.06 | 44.96 | 45.26 | 47.70 | 41.77 | 48.57 |
二、深度搜索任务评估
作为一款通用小参数模型,Nanbeige4.1-3B 在深度搜索与智能体任务上的表现实现了质的飞跃——其深度搜索性能可与 100 亿参数以下的专用智能体模型相媲美,而相较于现有绝大多数小规模通用模型(普遍几乎不具备深度搜索能力),Nanbeige4.1-3B 彻底打破了小模型在该领域的性能瓶颈,实现了相对于传统小规模通用模型的跨越式提升。具体评估数据(深度搜索与智能体基准)详见下表:
| 模型 | xBench-DeepSearch-2505 | xBench-DeepSearch-2510 | Browse-Comp | Browse-Comp-ZH | GAIA (纯文本) | HLE | SEAL-0 |
|---|---|---|---|---|---|---|---|
| 搜索专用小智能体 | |||||||
| MiroThinker-v1.0-8B | 61 | – | 31.1 | 40.2 | 66.4 | 21.5 | 40.4 |
| AgentCPM-Explore-4B | 70 | – | 25.0 | 29.0 | 63.9 | 19.1 | 40.0 |
| 大型基座模型(带工具) | |||||||
| GLM-4.6-357B | 70 | – | 45.1 | 49.5 | 71.9 | 30.4 | – |
| Minimax-M2-230B | 72 | – | 44.0 | 48.5 | 75.7 | 31.8 | – |
| DeepSeek-V3.2-671B | 71 | – | 67.6 | 65.0 | 63.5 | 40.8 | 38.5 |
| 小型基座模型(带工具) | |||||||
| Qwen3-4B-2507 | 34 | 5 | 1.57 | 7.92 | 28.33 | 11.13 | 15.74 |
| Qwen3-8B | 31 | 2 | 0.79 | 5.15 | 19.53 | 10.24 | 6.34 |
| Qwen3-14B | 34 | 9 | 2.36 | 7.11 | 30.23 | 10.17 | 12.64 |
| Qwen3-32B | 39 | 8 | 3.15 | 7.34 | 30.17 | 9.26 | 8.15 |
| Qwen3-30B-A3B-2507 | 25 | 10 | 1.57 | 4.12 | 31.63 | 14.81 | 9.24 |
| 我们的模型(带工具) | |||||||
| Nanbeige4-3B-2511 | 33 | 11 | 0.79 | 3.09 | 19.42 | 13.89 | 12.61 |
| Nanbeige4.1-3B | 75 | 39 | 19.12 | 31.83 | 69.90 | 22.29 | 41.44 |
从上述评估数据可以清晰看出,Nanbeige4.1-3B 在深度搜索与智能体任务上的表现,不仅远超同规模的 Qwen3 系列模型,甚至超过了部分搜索专用的小智能体模型(如 MiroThinker-v1.0-8B、AgentCPM-Explore-4B),充分验证了其在智能体能力上的突破性与可靠性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











