当大语言模型不再只能逐词生成,而是可以实时编辑自己已经生成的内容,会带来怎样的变革?
蚂蚁集团 inclusionAI 团队正式推出 LLaDA2.1——一款彻底打破自回归模型主导地位的文本扩散大模型。它不再是“一路写到黑”,而是先快速草拟全文,再通过词元到词元(Token-to-Token)实时编辑,即时修正错误、优化逻辑,从根源解决传统模型的缺陷。
- GitHub:https://github.com/inclusionAI/LLaDA2.X
- 模型:https://www.modelscope.cn/collections/inclusionAI/LLaDA21
这不是渐进式升级,而是一次生成范式的切换。并且,LLaDA2.1 今日正式开源。
核心突破:速度与质量同时登顶
LLaDA2.1 最具冲击力的表现,在于它在100B 参数量级上实现了极致高效:
- HumanEval+(编程任务):892 词元/秒
- BigCodeBench(代码基准):801 词元/秒
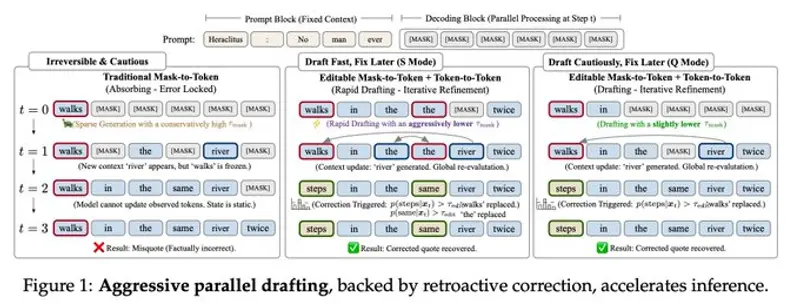
实现这一突破的关键,是其独创的 Token-to-Token 实时自修正能力:
模型先生成初稿,再像人类写作一样回头检查、编辑、改写,而不是只能一路向前、无法撤回。这让扩散模型第一次真正具备了纠错能力。
同时,LLaDA2.1 实现 SGLang Day 0 原生支持,工程化就绪,可直接投入生产环境使用。
核心技术:错误纠正可编辑引擎
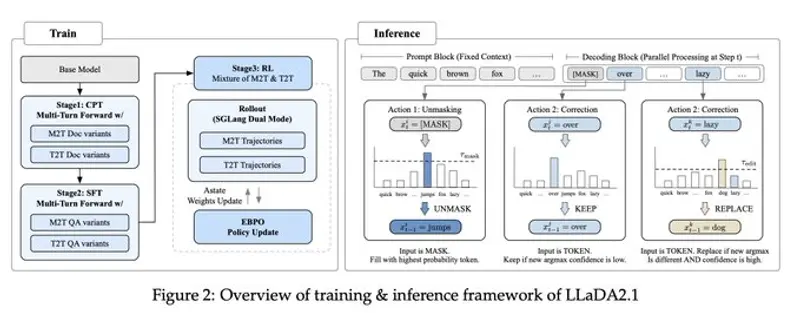
LLaDA2.1 的“魔法”,来自团队自研的 错误纠正可编辑引擎。
传统自回归模型与早期扩散模型,都面临一个致命问题:
暴露偏差(Exposure Bias)+ 错误累积
一旦前面生成错误,后面只能将错就错,无法回头修正。
而 LLaDA2.1 采用两阶段生成模式,彻底解决这一痛点:
- 快速草拟:先生成完整内容
- 智能编辑修正:逐词元检查、改写、优化
它不再只是“生成”,而是像人类专家一样写作 → 审阅 → 修改。
双模式设计:速度与质量自由切换
为兼顾研究与生产,LLaDA2.1 支持双模式灵活切换,用户可按需选择:
1. 快速模式
适合快速迭代、原型验证、批量生成
追求极致速度,牺牲少量精度
2. 高质量模式
适合生产环境、代码生成、专业内容创作
追求极致准确与逻辑严谨
从实验室到工业级落地,一套模型全覆盖。
行业首创:100B 扩散模型大规模强化学习框架
蚂蚁团队为 LLaDA2.1 构建了全球首个针对 100B 级文本扩散模型的大规模强化学习框架,并使用 EBPO(块级策略优化) 训练。
这让模型能够:
- 更精准理解复杂人类意图
- 更高保真度执行长指令
- 更强逻辑推理与结构化输出能力
- 在代码、长文本、多步任务上显著超越传统模型
LLaDA2.1 不再只是“生成文本”,而是真正理解并解决问题。
基准结论:扩散模型正式挑战自回归霸权
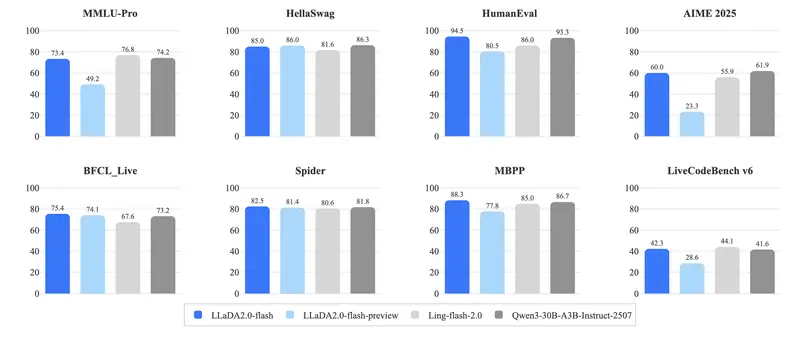
在 33 个权威基准测试 中,LLaDA2.1 系列全面验证:
扩散模型,已经可以正面挑战自回归模型的主流地位。
尤其在:
- 代码生成
- 长文本理解
- 复杂指令遵循
- 结构化输出
- 实时修正能力
LLaDA2.1 展现出与传统大模型完全不同的优势曲线。
版本与规格:两个版本,全栈开源
团队同步发布两个实用版本,均已开源:
LLaDA2.1-Mini(16B)
- 轻量高效
- 推理速度极快
- 适合个人/小规模部署
LLaDA2.1-Flash(100B)
- 最高性能
- 峰值 892 词元/秒
- 面向生产、高并发、复杂任务
两大版本均可用于:
- 软件开发
- 内容创作
- 智能助手
- 企业级生成服务
- 科研与二次创新
LLaDA2.X 系列完整时间线与能力
时间线
- 2026.02:发布 LLaDA2.1,基于 Token-to-Token 编辑加速文本扩散
- 2025.11:发布 LLaDA2.0,全球首个100B 参数级扩散大模型,带 MoE 架构
LLaDA2.0 核心里程碑
- 全球首个扩展到 100B 参数的扩散语言模型
- 推理加速 2.1 倍
- 最高 535 词元/秒(Flash-CAP 版本)
- 模型权重 + 训练代码 完全开源
完整模型列表
| 模型ID | 说明 |
|---|---|
| inclusionAI/LLaDA2.1-mini | 16B,指令微调 |
| inclusionAI/LLaDA2.1-flash | 100B,高性能 |
| inclusionAI/LLaDA2.0-mini | 16B,基础版 |
| inclusionAI/LLaDA2.0-flash | 100B,基础版 |
| inclusionAI/LLaDA2.0-mini-CAP | 支持置信度感知并行 |
| inclusionAI/LLaDA2.0-flash-CAP | 100B 高效推理版 |
所有模型均可在 Hugging Face 直接下载。
工程化就绪:可直接部署生产
为让 100B 模型真正可用,团队完成了深度工程优化:
- 基于 dInfer + SGLang 构建专用推理引擎
- 支持 KV 缓存复用
- 支持 块级并行解码
- 低延时、高吞吐、可横向扩展
LLaDA2 系列不只是学术成果,更是可直接上线的工业级生成系统。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











