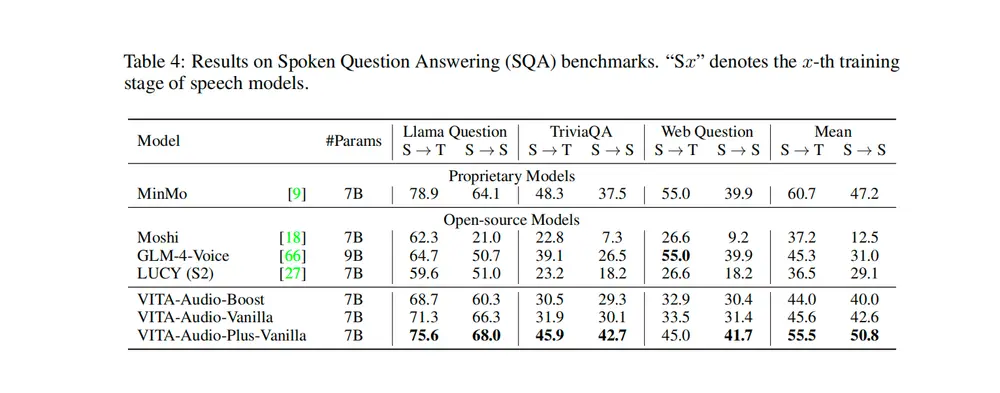
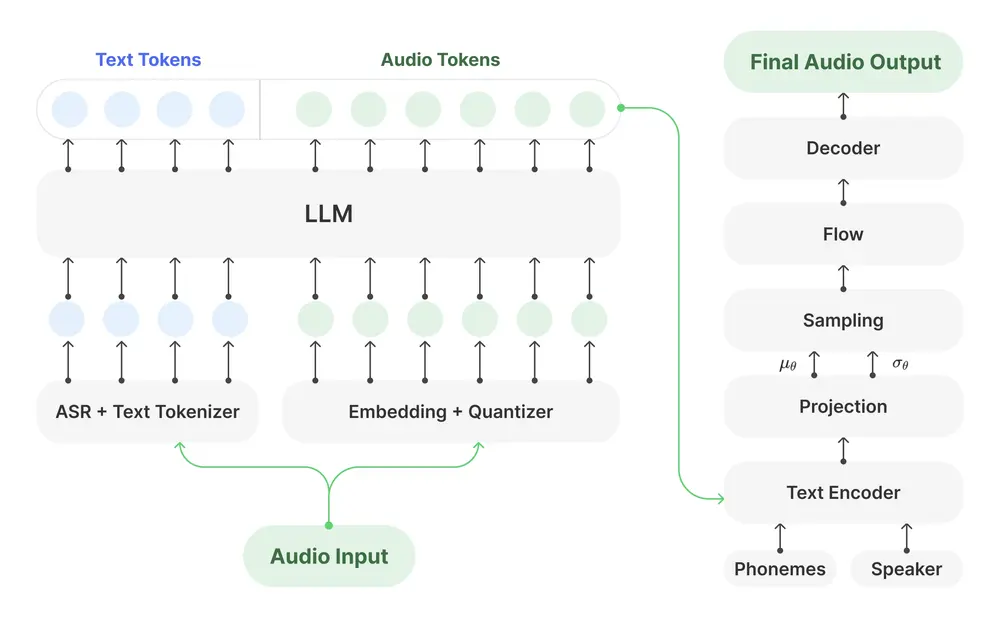
多模态语音交互的端到端大型语音模型 VITA-Audio腾讯优图实验室、南京大学和厦门大学的研究人员推出用于高效多模态语音交互的端到端大型语音模型 VITA-Audio,VITA-Audio 的目标是通过快速生成音频和文本令牌,显著降低流式语音交互中的延迟...语音模型# VITA-Audio# 语音模型11个月前02410
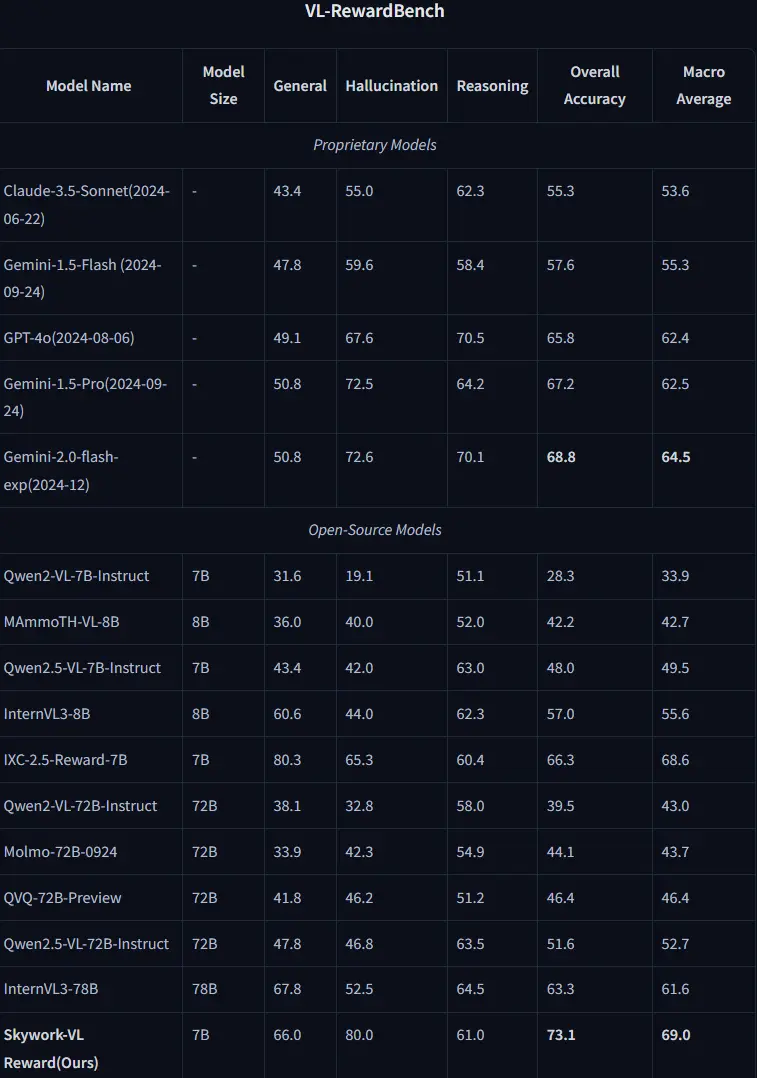
天工AI推出用于多模态理解和推理任务的多模态奖励模型Skywork-VL Reward天工AI(Skywork AI)推出一个用于多模态理解和推理任务的多模态奖励模型Skywork-VL Reward,此模型是基于Qwen2.5-VL-7B-Instruct训练,Skywork-VL ...多模态模型# Skywork-VL Reward# 多模态奖励模型# 天工AI11个月前03820
基于 Qwen3 的混合专家(MoE)模型Arcana Qwen3 2.4B A0.6BArcana Qwen3 2.4B A0.6B 是一个基于 Qwen3 的混合专家(MoE)模型,总参数量为 24 亿,每个专家模型拥有 6 亿参数。该模型旨在提供更高的准确性、更高的效率和更低的内存...大语言模型# Arcana Qwen3 2.4B A0.6B# MoE模型# Qwen311个月前02670
阶跃星辰推出用于生成高保真度和可控制的纹理化3D资产的开放框架Step1X-3D阶跃星辰推出一个用于生成高保真度和可控制的纹理化3D资产的开放框架Step1X-3D,该框架旨在解决3D生成领域面临的挑战,包括数据稀缺性、算法限制和生态系统碎片化。Step1X-3D通过以下三个主要...3D模型# 3D资产# Step1X-3D# 阶跃星辰11个月前02130
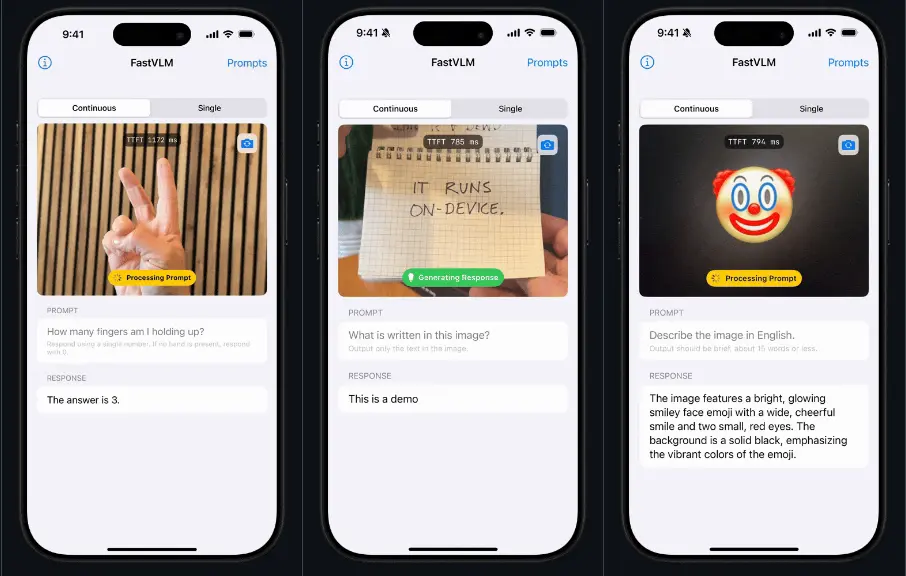
苹果推出高效视觉语言模型FastVLM:通过优化视觉编码器来提高模型在处理高分辨率图像任务时的效率和性能苹果推出一种高效视觉语言模型FastVLM,旨在通过优化视觉编码器(Vision Encoder)来提高模型在处理高分辨率图像任务时的效率和性能。FastVLM的核心是其创新的视觉编码器 FastVi...多模态模型# FastVLM# 苹果# 视觉语言模型11个月前02900
字节跳动推出专注于提升多模态理解与推理能力的视觉-语言基础模型Seed1.5-VL字节跳动正式推出 Seed1.5-VL,这是一款专注于提升多模态理解与推理能力的视觉-语言基础模型。Seed1.5-VL 不仅在视觉和视频理解任务中表现出色,还在智能体相关任务及复杂推理挑战中展现了卓...多模态模型# Seed1.5-VL# 字节跳动# 视觉-语言基础模型11个月前05450
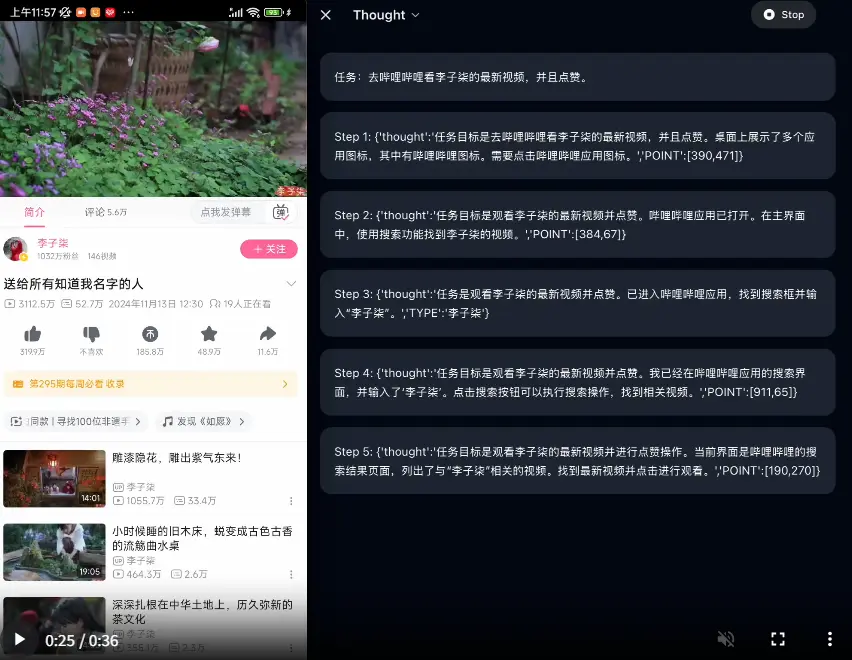
基于MiniCPM-V构建的开源端侧智能体大模型AgentCPM-GUI:,接受手机屏幕图像作为输入,自动执行用户提出的任务AgentCPM-GUI是由清华大学THUNLP实验室与面壁智能团队联合开发的开源端侧智能体大模型,基于MiniCPM-V构建,总参数量8B,接受手机屏幕图像作为输入,自动执行用户提出的任务。 Git...多模态模型# AgentCPM-GUI# MiniCPM-V# 智能体大模型11个月前03720
新型图像训练自由方法 IP-Composer:从多个视觉概念中合成图像特拉维夫大学和英伟达的研究人员介绍了一种名为 IP-Composer 的新型训练自由(training-free)方法,用于从多个视觉概念中合成图像。该方法通过自然语言描述从输入图像中提取特定概念,并...图像模型# IP-Composer11个月前05710
北京沐言智语科技开源专为播客场景优化的可训练TTS模型 Muyan-TTS 北京沐言智语科技开源可训练文本到语音(TTS)模型 Muyan-TTS ,专为播客场景优化,并在5万美元的预算内开发。该模型通过在超过10万小时的播客音频数据上进行预训练,能够实现高质量的零样本文本到...语音模型# Muyan-TTS# TTS模型11个月前03970
INTELLECT-2 发布:首个通过全球分布式强化学习训练的 32B 参数模型Prime Intellect发布 INTELLECT-2,这是首个通过全球分布式强化学习训练的 32B 参数模型。与传统的集中式训练不同,INTELLECT-2 使用完全异步的强化学习(RL),在一...大语言模型# INTELLECT-2# 强化学习11个月前02910
多模态模型RoboBrain:让机器人从抽象指令到具体操作的多模态大脑近年来,多模态大语言模型(MLLMs)在多种场景中展现了卓越的能力,但在机器人领域,尤其是在长时段复杂操作任务中,其表现仍存在显著局限性。这些局限主要源于当前 MLLMs 缺乏三种关键能力:规划能力...多模态模型# RoboBrain# 多模态模型# 机器人11个月前02500
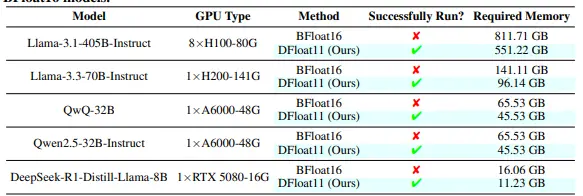
无损压缩框架DFloat11:可将大语言模型的规模缩小约 30%,同时保持与原始模型完全一致的逐位相同输出DFloat11 是一个无损压缩框架,可将大语言模型(LLM)的规模缩小约 30%,同时保持与原始模型完全一致的逐位相同输出。它支持在资源受限的硬件上进行高效的 GPU 推理,且不牺牲准确性。 Git...大语言模型# DFloat11# 无损压缩框架11个月前03430