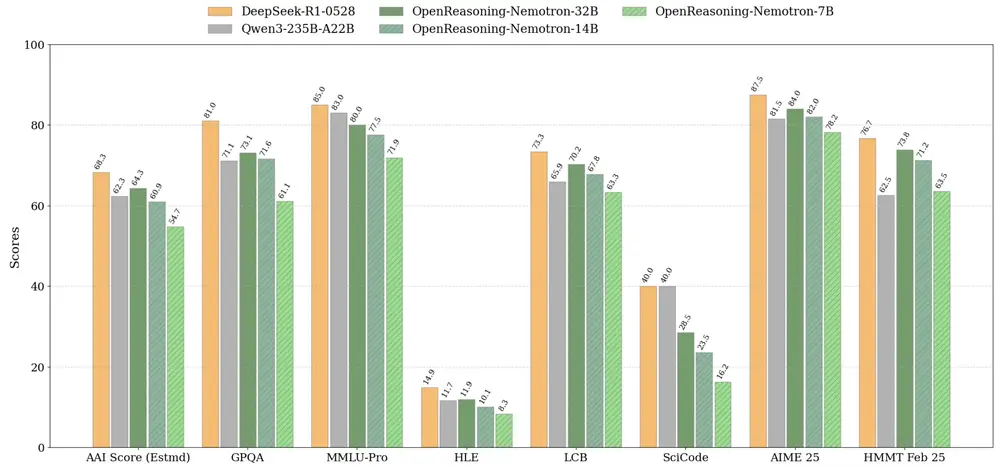
英伟达发布OpenReasoning-Nemotron:多规模推理模型,覆盖数学、科学与编程英伟达近日发布了 OpenReasoning-Nemotron 模型家族,这是一组专为数学、科学和编程推理任务优化的大语言模型。 模型:https://huggingface.co/collectio...大语言模型# OpenReasoning-Nemotron# 英伟达9个月前03480
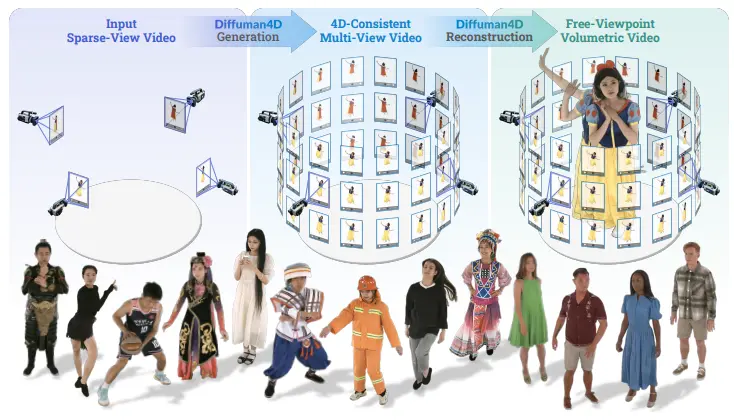
新型扩散模型 Diffuman4D :从稀疏视角视频中生成高质量、4D 一致的人体自由视角视频浙江大学和蚂蚁研究的研究人员推出新型扩散模型 Diffuman4D ,从稀疏视角视频中生成高质量、4D 一致的人体自由视角视频。该模型通过引入滑动迭代去噪过程和基于人体骨骼的姿态条件机制,显著提升了生...视频模型# Diffuman4D# 人体自由视角视频9个月前03890
FantasyPortrait:基于DIT架构模型的多角色肖像动画生成框架由阿里巴巴与北京邮电大学联合提出,FantasyPortrait 是一个基于扩散变换器(Diffusion Transformer)的创新框架,用于从静态图像生成高保真、富有表现力的单角色与多角色面部...视频模型# FantasyPortrait# 多角色肖像动画生成9个月前01030
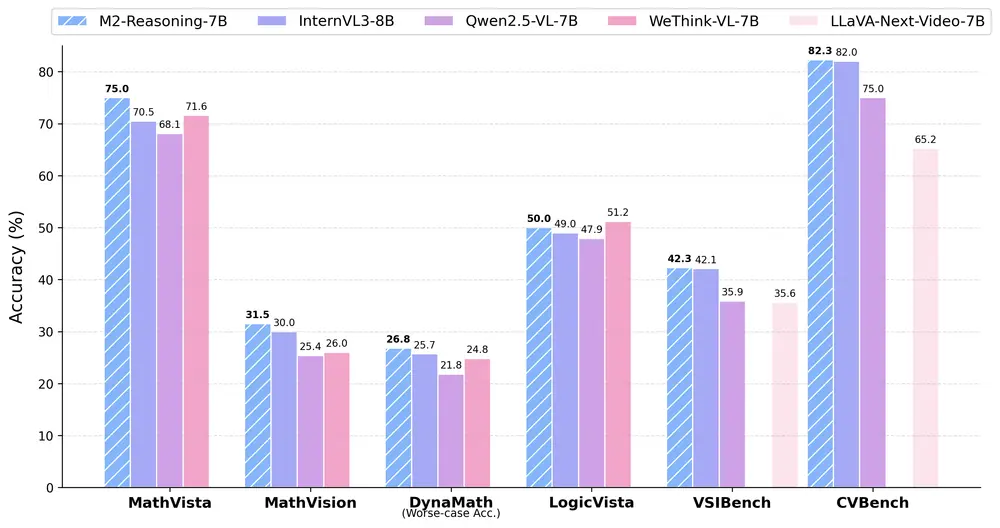
蚂蚁集团发布 M2-Reasoning-7B:通用与空间推理能力领先的多模态大模型蚂蚁集团 inclusionAI 项目组 正式发布 M2-Reasoning-7B,一个在通用推理与空间推理领域表现卓越的多模态大语言模型(MLLM)。该模型基于 70 亿参数架构,通过创新的数据生成...多模态模型# M2-Reasoning-7B# 多模态大模型# 蚂蚁集团9个月前02110
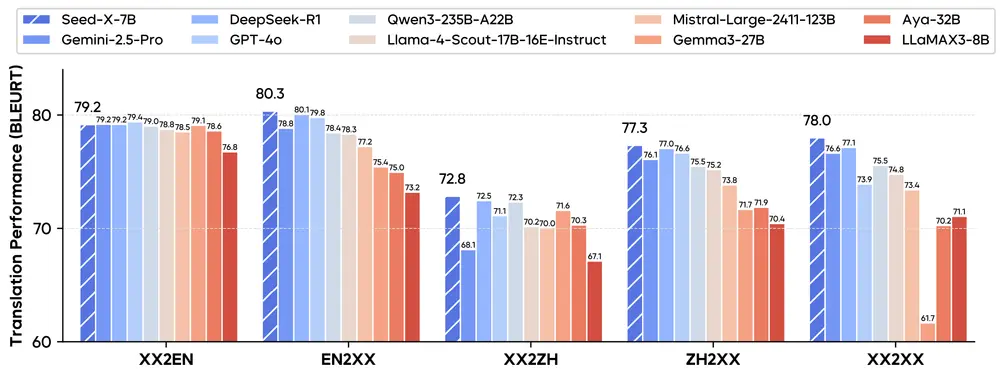
字节跳动开源 Seed-X:70亿参数的多语言翻译模型,性能媲美 GPT-4 和 Gemini字节跳动推出Seed-X,这是一个开源的多语言翻译模型系列,包括指令模型、强化学习模型和奖励模型,参数规模为 70亿(7B),却在翻译能力上展现出媲美甚至超越超大规模闭源模型(如 Gemini-2.5...大语言模型# SEED-X# 多语言翻译模型# 字节跳动9个月前01210
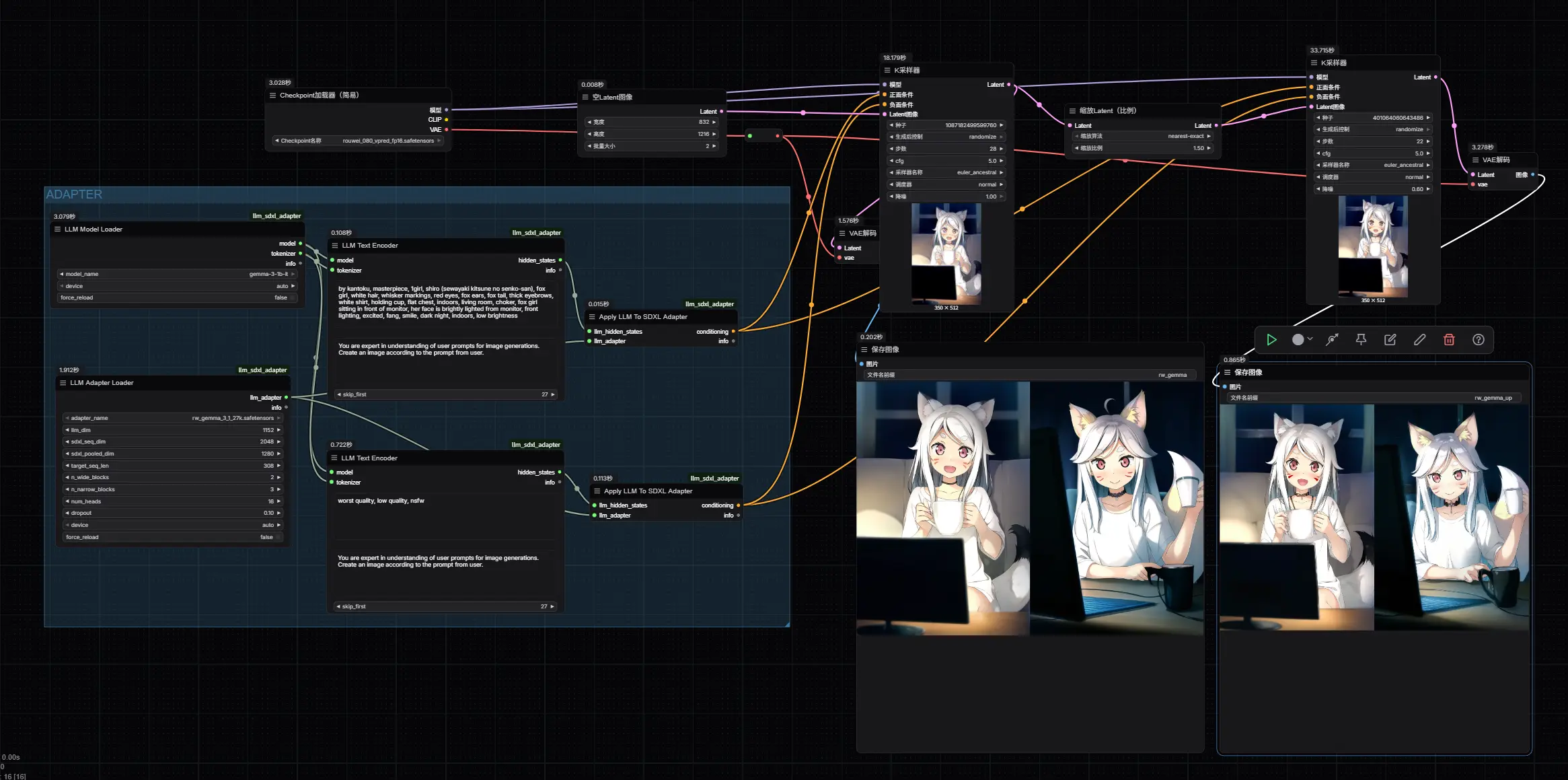
RouWei-Gemma:基于 Gemma-3-1b 的文本编码器适配器(用于 Rouwei 0.8)RouWei-Gemma是一个为 Rouwei 0.8 开发的文本编码器适配器,基于 Gemma-3-1b 构建,用于替换 SDXL 中的 CLIP 文本编码器。它利用大语言模型(LLM)的强大语义理...图像模型# Gemma-3-1b# Rouwei 0.8# RouWei-Gemma9个月前03280
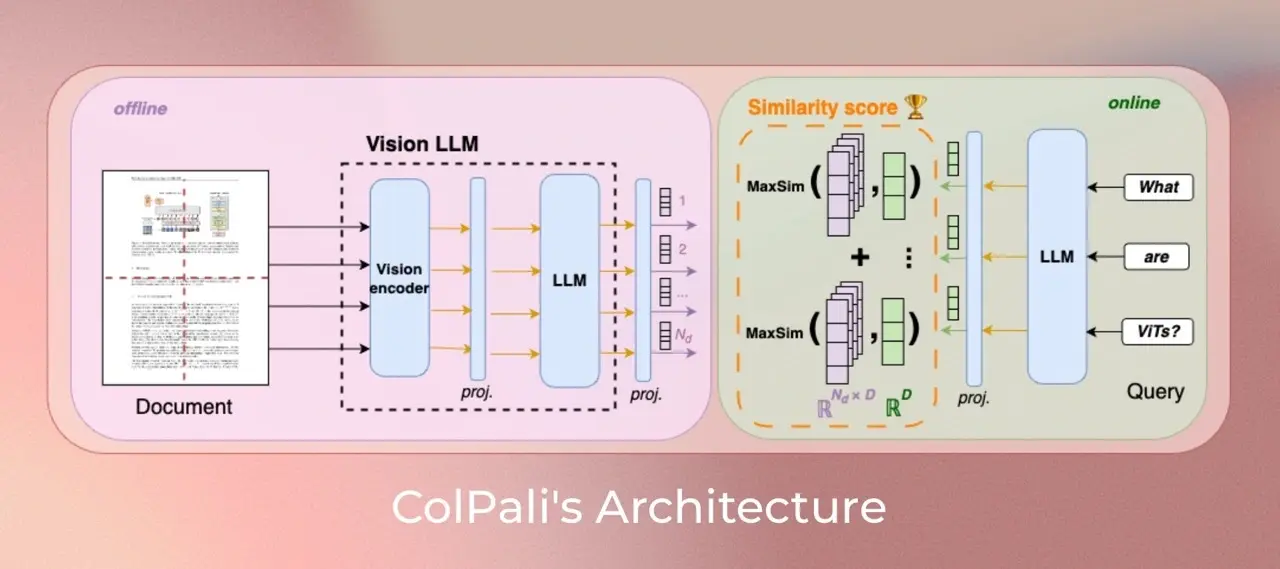
ColPali:基于视觉语言模型的新型高效文档检索系统由 Illuin科技、Equall.ai、巴黎-萨克雷大学和苏黎世联邦理工学院 联合提出,ColPali 是一种基于视觉语言模型(VLMs)的文档检索模型,能够直接从文档图像中提取信息,实现快速、准确...多模态模型# ColPali# 文档检索9个月前01480
ColQwen2.5-Omni:首个支持视觉+音频检索的ColBERT风格模型ColQwen2.5-Omni 是基于 Qwen2.5-Omni-3B-Instruct 的新一代多模态检索模型。该模型采用 ColBERT 策略,支持从图像、音频等多模态内容中高效检索信息,是目前首...多模态模型# ColQwen2.5-Omni9个月前01890
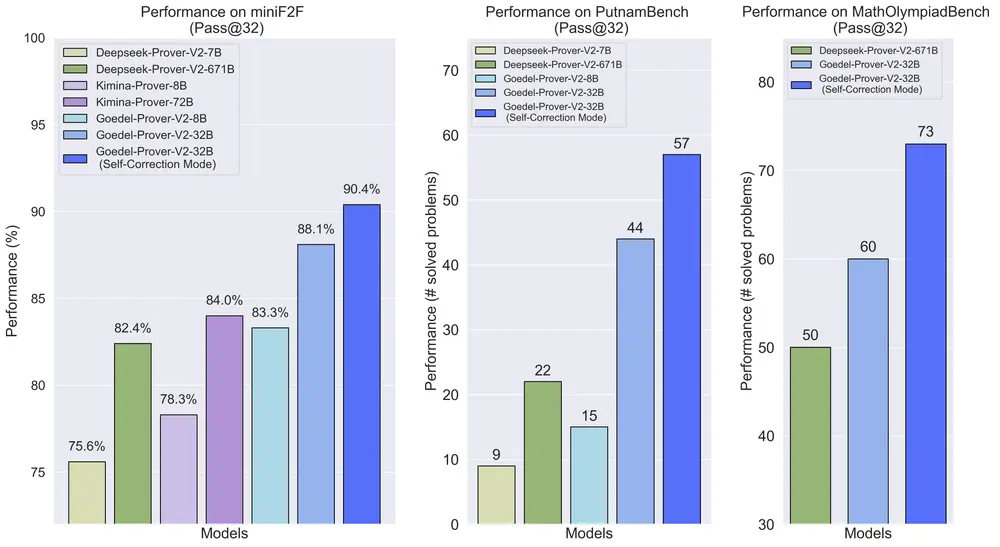
清华、普林斯顿等联合推出数学定理证明模型Goedel-Prover-V2:在自动形式化数学证明生成领域树立了新的技术标杆近日,由普林斯顿大学语言与智能实验室、清华大学、英伟达、斯坦福大学、Meta FAIR、亚马逊、上海交通大学和北京大学联合研发的 Goedel-Prover-V2 正式发布。这是一系列开源语言模型,在...大语言模型# Goedel-Prover-V2# 数学定理证明模型9个月前02670
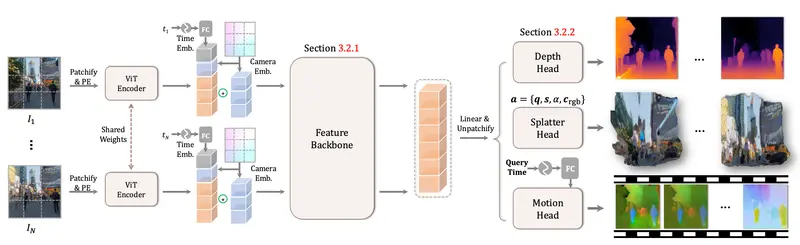
北大、字节跳动与卡内基梅隆大学联合推出MoVieS:一秒钟完成4D动态视角合成的革命性模型你有没有想象过,仅凭一段普通的手机视频,就能“穿越”到画面中,从任意角度和时间点重新观察整个动态场景?比如在一场足球比赛中,你可以自由“飞行”在球场上空,从不同角度观看球员跑动、球的轨迹,甚至追踪每一...3D模型# MoVieS# 前馈模型9个月前02020
LightX2V:轻量级视频生成推理框架,统一支持多种模态输入随着多模态生成模型的发展,文本到视频(T2V)、图像到视频(I2V)等任务逐渐成为研究热点。然而,不同模型往往使用不同的推理流程,导致部署与调用复杂、资源占用高。 为此,研究人员推出了一个全新的轻量级...视频模型# LightX2V# 视频生成9个月前02840
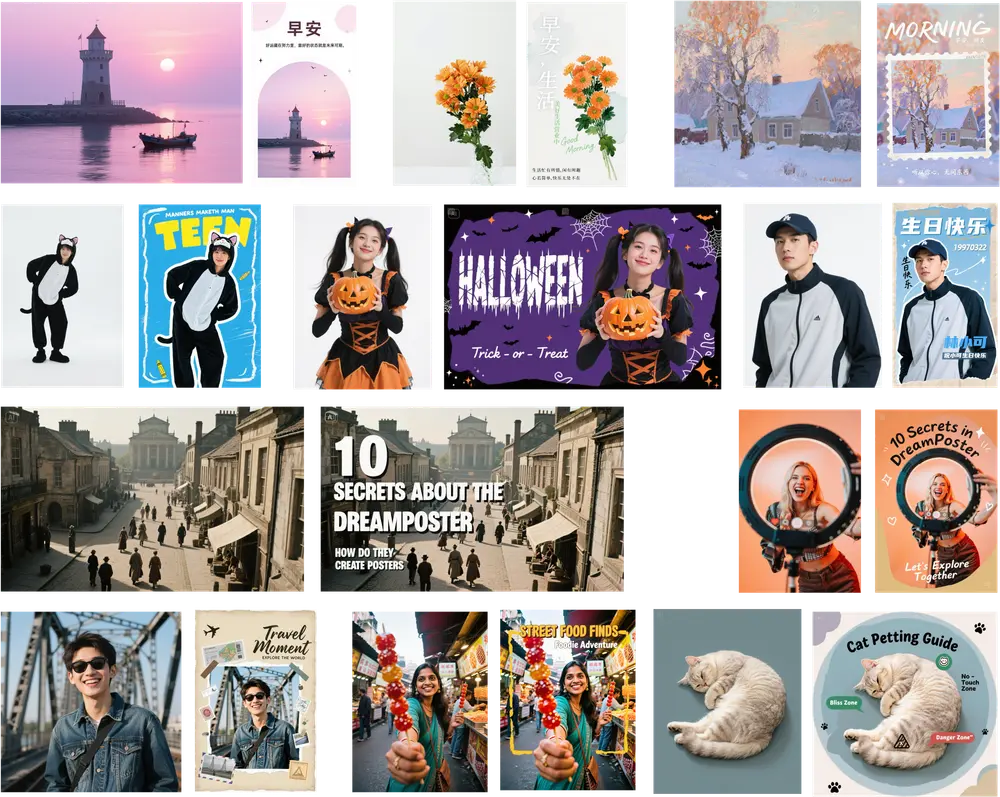
字节跳动 & 复旦大学联合提出智能海报生成新框架 DreamPoster在 AI 生成图像(AIGC)领域,海报设计一直是极具挑战性的任务之一。它不仅要求模型理解文本描述,还需要兼顾视觉美感、排版逻辑和品牌一致性。近日,字节跳动与复旦大学的研究团队联合提出了一种新的文本...图像模型# DreamPoster# 字节跳动# 海报设计9个月前04600