韩国科学技术院提出 ALG 方法:显著提升图生视频模型的动态性图像到视频(Image-to-Video, I2V)模型近年来取得了长足进展,能够根据一张静态图像和文本提示生成动态视频,实现更强的视觉控制。然而,研究发现,这类模型往往生成的视频过于静态,动态性远不...视频模型# ALG# 图生视频9个月前01690
英伟达发布 Audio Flamingo 3:全球首个支持 10 分钟音频理解的开源模型在视觉和文本领域大模型持续突破之后,音频理解也开始迎来新的里程碑。英伟达近日发布了 Audio Flamingo 3(AF3),这是目前最先进的开源大型音频语言模型(Large Audio Langu...语音模型# Audio Flamingo 3# 英伟达# 音频理解模型9个月前05540
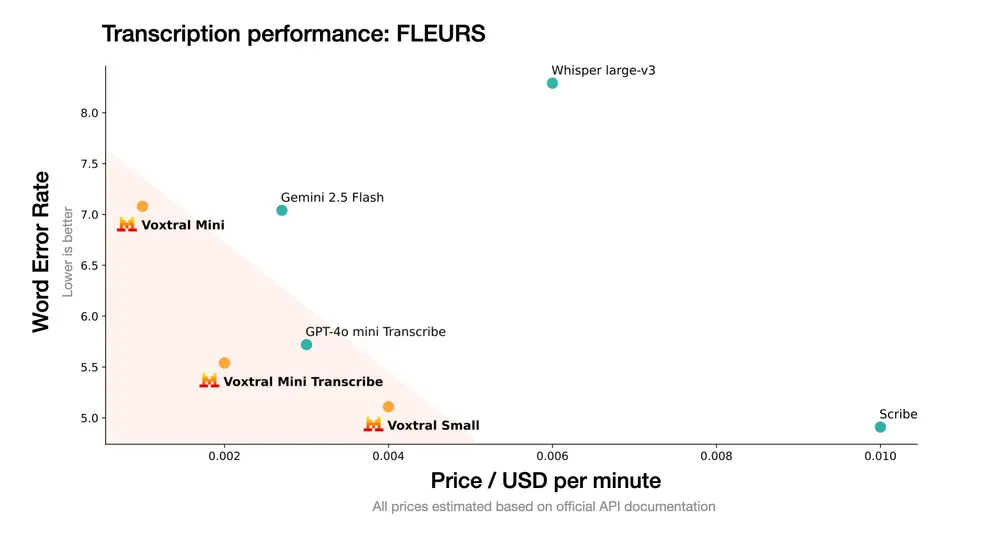
Mistral 推出首个面向企业的开源语音理解模型 Voxtral:具备高精度的语音转录能力,还支持对音频内容的深度语义理解,如问答、摘要、翻译和功能调用随着语音逐渐成为人机交互的核心方式,法国AI初创公司 Mistral 正式发布其首个开源音频模型 Voxtral,标志着其在语音智能领域的重大突破。 Voxtral 是一款面向企业的语音理解模型(Sp...语音模型# Mistral# Voxtral# 语音理解模型9个月前01850
PUSA V1.0:以500 美元成本超越 WAN-I2V-14B 的高效视频生成模型由香港城市大学、华为研究院、腾讯、岭南大学等机构联合提出,PUSA V1.0 是一个基于矢量化时间步适应(VTA) 的新型视频扩散模型,实现了极低资源消耗下的高质量视频生成能力。 项目主页:https...视频模型# PUSA V1.0# WAN-I2V-14B# 视频生成模型9个月前06440
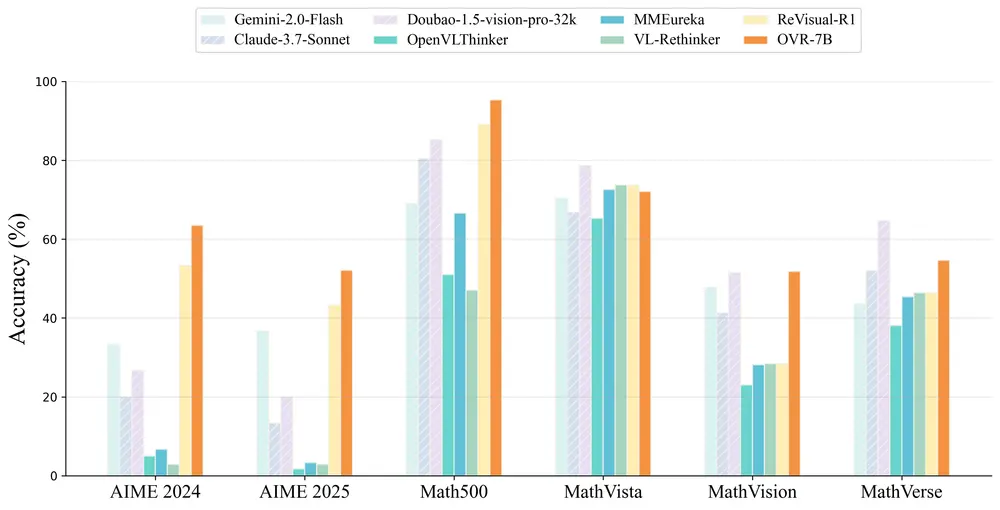
Open-Vision-Reasoner(OVR):基于语言认知迁移的多模态视觉推理新范式大语言模型(LLMs)之所以具备强大的推理能力,关键在于其通过可验证奖励机制的强化学习所涌现的认知行为。那么,是否可以将这一原则迁移至多模态大语言模型(MLLMs),从而解锁其高级视觉推理能力? 本研...多模态模型# Open-Vision-Reasoner# 多模态大语言模型9个月前03420
Gemini Embedding 正式上线:支持多语言、灵活维度,现已全面可用谷歌首个正式版 Gemini Embedding 文本嵌入模型(gemini-embedding-001) 现已在 Gemini API 和 Vertex AI 平台对开发者全面开放使用。 自今年三月...大语言模型# Gemini Embedding# 文本嵌入模型# 谷歌9个月前02270
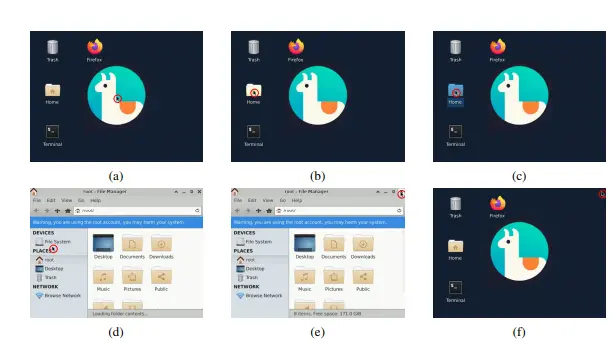
NeuralOS:用神经生成模型模拟操作系统图形界面滑铁卢大学与加拿大国家研究院的研究团队提出了一项极具前瞻性的项目:NeuralOS —— 一个通过神经生成模型模拟操作系统图形用户界面(GUI)的框架。 项目主页:https://neural-os...多模态模型# NeuralOS# 操作系统9个月前0880
PyVision:基于动态工具生成的多模态智能视觉推理框架随着大语言模型(LLMs)的发展,我们正进入一个代理式人工智能(Agent AI)时代。这些模型不仅能够生成文本,还能进行任务规划、逻辑推理,并调用外部工具来扩展能力边界。 但真正的前沿在于:不是仅仅...多模态模型# PyVision# 多模态智能视觉推理9个月前02250
T-LoRA:基于时间步敏感机制的扩散模型个性化定制方法在图像生成任务中,扩散模型凭借强大的表达能力成为主流方案。然而,在仅有一张图像作为训练样本的情况下,模型容易出现过拟合现象,导致生成结果过度依赖原始图像背景或姿态,而无法很好地响应文本提示。 为此,研...图像模型# T-LoRA9个月前01200
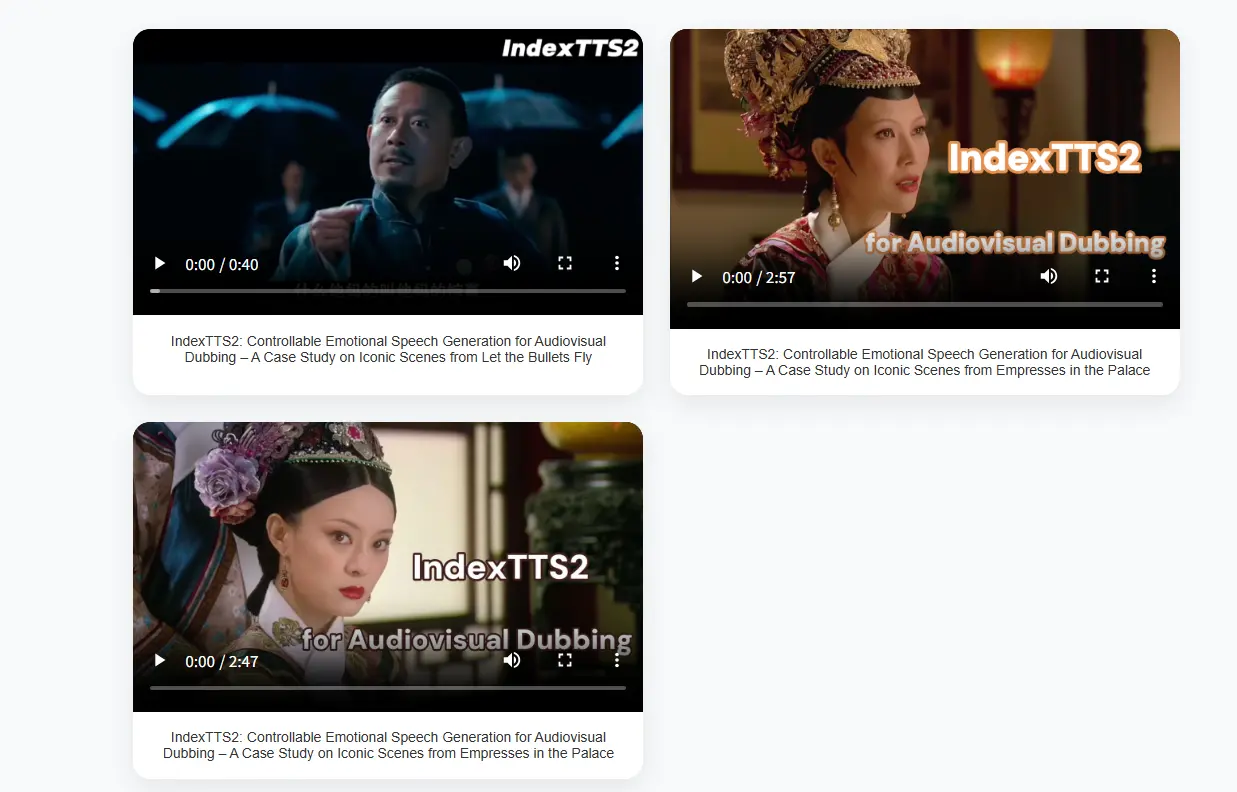
B站推出IndexTTS2:自回归 TTS 模型的持续时间控制与情感表达新突破在大规模文本转语音(TTS)模型的发展中,自回归与非自回归系统各有优劣。自回归模型虽然在语音自然度方面表现优异,但其逐标记生成机制难以实现对语音持续时间的精确控制。这一缺陷在视频配音等需要严格音画同步...语音模型# B站# IndexTTS27个月前05800
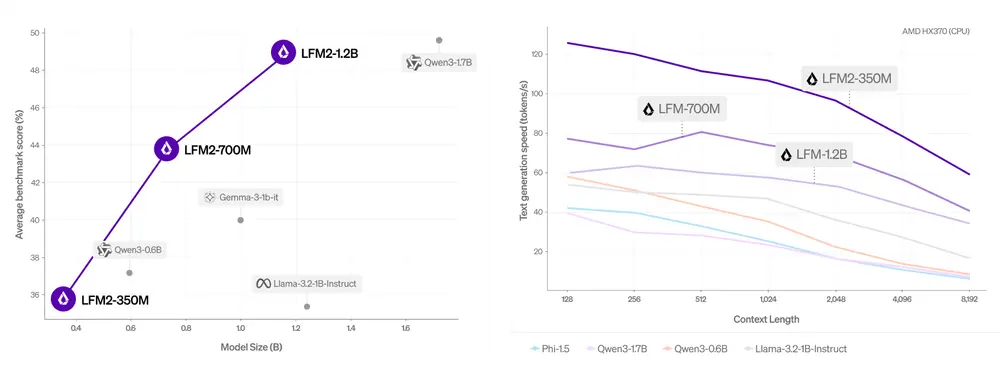
Liquid AI 发布 LFM2:设备端最快的生成式基础模型Liquid AI 正式发布新一代设备端基础模型 LFM2(Liquid Foundation Model 2),重新定义了边缘 AI 推理的速度、效率与部署灵活性。 模型:https://huggi...大语言模型# LFM2# Liquid AI9个月前02600
Mistral AI 推出 Devstral Medium 以及 Devstral Small 的升级版本Mistral AI 推出了 Devstral Medium 以及 Devstral Small 的升级版本。这些模型由 Mistral AI 与 All Hands AI 合作开发,重点在于对不同提...大语言模型# Devstral Medium# Devstral Small# Mistral AI9个月前02410