
由香港城市大学、华为研究院、腾讯、岭南大学等机构联合提出,PUSA V1.0 是一个基于矢量化时间步适应(VTA) 的新型视频扩散模型,实现了极低资源消耗下的高质量视频生成能力。
- 项目主页:https://yaofang-liu.github.io/Pusa_Web
- GitHub:https://github.com/Yaofang-Liu/Pusa-VidGen
- 模型:https://huggingface.co/RaphaelLiu/PusaV1
它不仅在图像到视频(I2V)任务上超越了当前最先进的 Wan-I2V-14B 模型,还支持多种零样本多任务能力,如起止帧生成、视频扩展、视频过渡等。
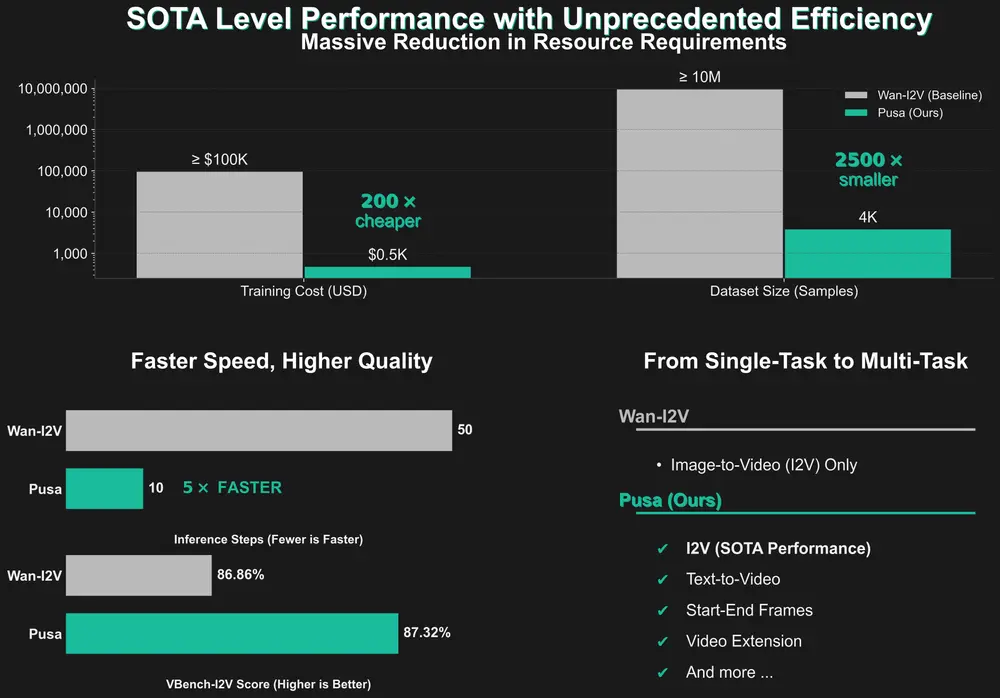
核心优势一览
| 项目 | PUSA V1.0 | Wan-I2V-14B |
|---|---|---|
| VBench-I2V 得分 | 87.32% | 86.86% |
| 训练成本 | $500 | ≥ $100,000 |
| 训练数据量 | 4K 样本 | ≥ 10M 样本 |
| 推理步数 | 仅需 10 步 | 更多 |
| 任务支持 | 多任务(I2V、起止帧、扩展、T2V 等) | 仅 I2V |
技术创新:矢量化时间步适应(VTA)
传统视频扩散模型依赖标量时间步控制帧演变,导致帧之间同步性过强,难以灵活建模复杂时间关系。
PUSA 提出了一种全新的解决方案——矢量化时间步适应(Vectorized Timestep Adaptation, VTA):
- 将单一时间步扩展为一个时间步向量序列,每个元素对应一帧
- 实现帧级别的噪声控制与演变节奏调节
- 支持多样化的视频生成任务,如起止帧、视频扩展、过渡等
- 非破坏性适配:完全保留基础模型能力,无需重构模型结构
这种设计不仅提升了时间建模的灵活性,也显著降低了训练成本。
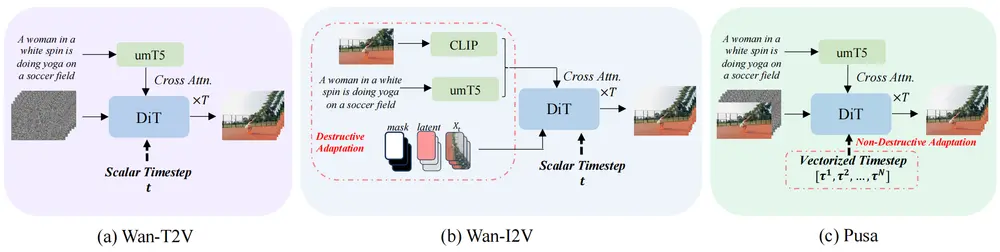
多任务零样本能力
得益于 VTA 的灵活性,PUSA 能够在不进行特定任务微调的前提下,完成多种视频生成任务:
| 任务 | 描述 |
|---|---|
| 图像到视频(I2V) | 输入单张图像,生成连续视频内容 |
| 起止帧生成 | 给定首帧与尾帧,生成中间过渡帧 |
| 视频扩展 | 基于前若干帧预测后续帧 |
| 视频补全 / 过渡 | 衔接两个片段,生成自然过渡 |
| 文本到视频(T2V) | 基于文本描述生成视频内容 |
这些能力使得 PUSA 成为当前最通用的视频生成模型之一。
模型架构与训练细节
✅ 架构特点
- 基于 Wan-T2V-14B 主干模型
- 使用 LoRA 微调模块 实现轻量级适配 VTA
- 兼容全微调模式(如 Pusa V0.5)
- 使用 DeepSpeed Zero2 进行高效训练
- 硬件配置:8x 80GB GPU
更新日志
✅ v1.0(2025年7月15日)
- 发布基于 Wan-Video 模型的 Pusa V1.0
- 提供技术报告、模型权重与训练数据集
- 集成至
/PusaV1,新增训练脚本与文档
✅ v0.5(2025年6月3日)
- 发布起止帧生成、多帧生成、视频过渡和视频扩展的推理脚本
✅ v0.5(2025年4月10日)
- 发布训练代码与细节
- 支持 Pusa 和 Mochi 的多节点/单节点全微调
- 发布训练数据集
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











