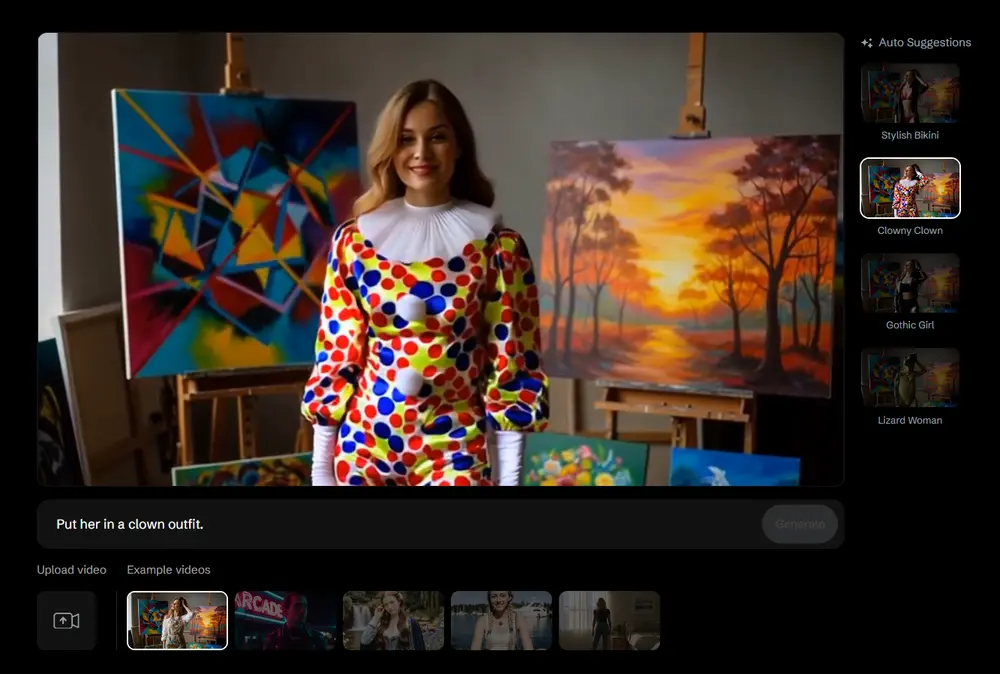
DecartAI推出 Lucy Edit Dev:全球首个开源、支持自由文本提示的指令引导视频编辑模型DecartAI推出 Lucy Edit Dev ——全球首个开源、支持自由文本提示的指令引导视频编辑模型。它允许用户仅通过自然语言描述,即可完成复杂的视频修改任务,如更换服装、替换角色、插入物体或更...视频模型# Lucy Edit Dev# 视频编辑模型7个月前04080
Moondream 团队推出 Moondream 3 预览版本:轻量架构下的高性能视觉推理模型Moondream 团队正式推出 Moondream 3 的预览版本——一款基于 9B 参数稀疏混合专家(MoE)架构的新模型,实际激活参数仅为 2B。它在保持极快推理速度和低运行成本的同时,实现了接...多模态模型# Moondream 3# 视觉推理模型7个月前06510
Wan-Animate:阿里通义实验室推出的统一人物动画与替换框架阿里巴巴通义实验室 HumanAIGC 团队近日将推出 Wan-Animate —— 一个基于 Wan 系列模型构建的统一人物动画与角色替换框架。 项目主页:https://humanaigc.git...视频模型# Wan-Animate# 阿里通义实验室7个月前02550
IBM 推出 Granite Docling:专为文档转换优化的轻量级多模态模型IBM Research 正式发布 Granite Docling-258M,一款基于 IDEFICS3 架构构建的新型多模态图像-文本到文本模型,专为高效、准确的文档理解与结构化转换而设计。 Git...多模态模型# Granite Docling-258M# 多模态模型# 文档转换7个月前01090
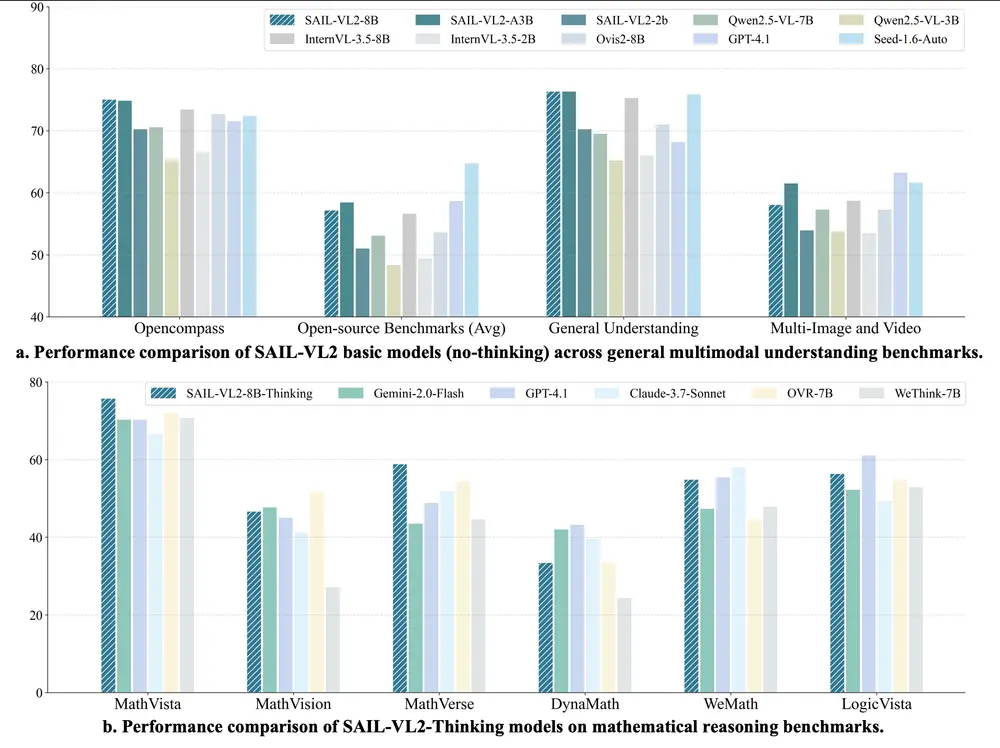
抖音推出SAIL-VL2:面向细粒度感知与复杂推理的新一代开源视觉语言模型由抖音 SAIL 团队与新加坡国立大学 LV-NUS 实验室联合研发,SAIL-VL2 是一款全新的开源视觉语言基础模型(Vision-Language Model, LVM),在 2B 和 8B 参...多模态模型# SAIL-VL2# 抖音# 视觉语言模型7个月前03330
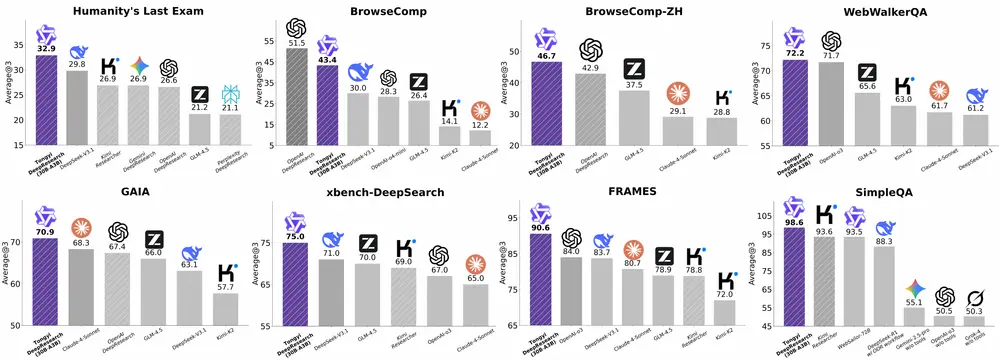
通义 DeepResearch:首个全开源 Web Agent,性能对标 OpenAI 深度研究模型阿里通义实验室正式发布 Tongyi DeepResearch —— 一个在性能上可与当前最先进闭源系统相媲美的全开源 Web Agent。 项目主页:https://tongyi-agent.git...大语言模型# Tongyi DeepResearch# 深度研究模型7个月前03760
FireRedTTS-2:面向长对话场景的流式多说话人语音合成系统在播客制作、智能客服和实时对话系统中,自然流畅的多说话人语音合成是一项关键能力。然而,当前主流的对话式TTS(Text-to-Speech)技术普遍存在几个核心问题: 需要预先提供完整对话文本,无法支...语音模型# FireRedTTS-2# 小红书7个月前02250
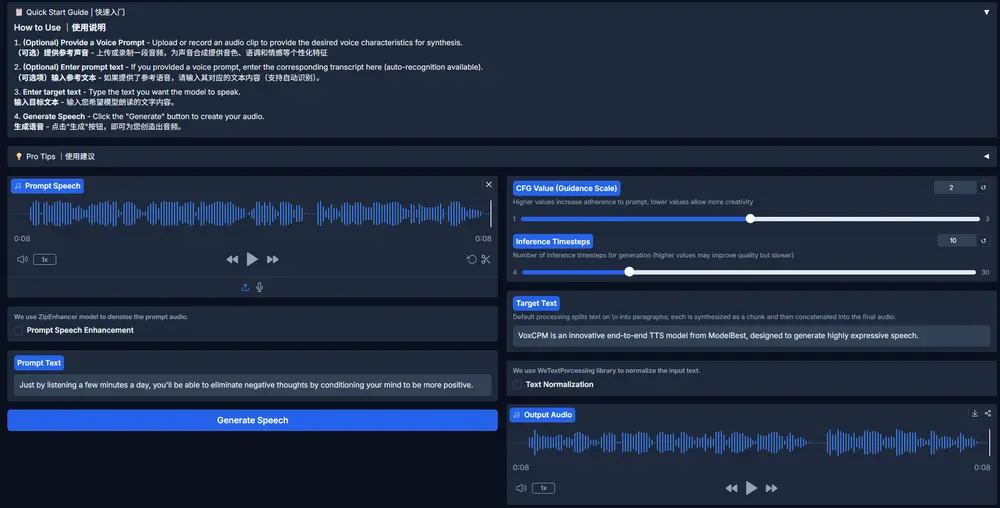
面壁智能发布VoxCPM:无需分词器的TTS,用于上下文感知的语音生成和真实感声音克隆在语音合成领域,大多数主流 TTS(Text-to-Speech)模型依赖于将语音信号离散化为“音素”或“语音标记”——这一过程虽然便于建模,但也带来了固有局限: 声音细节丢失、韵律不自然、跨说话人迁...语音模型# TTS# VoxCPM# 面壁智能7个月前05230
英伟达开源ViPE工具:从普通视频中精准提取3D信息,还附赠9600万帧标注数据集在空间AI领域,“3D几何感知”是许多技术落地的基础——无论是AR场景构建、自动驾驶环境感知,还是视频内容的3D重构,都需要精准的相机姿态、内参和深度信息。但长期以来,从野外随机拍摄的视频(如自拍、行...3D模型# ViPE# 英伟达7个月前03970
字节跳动发布OneReward 框架:用单一奖励模型革新多任务图像编辑在图像生成领域,AI 已经能完成许多复杂操作:补全残缺画面、扩展图像边界、移除干扰物体,甚至在图中添加可读文本。但这些任务通常由不同模型分别处理——每个任务有自己的训练流程、评估标准和奖励机制。 这带...图像模型# FLUX.1-Fill-dev-OneReward# OneReward# 字节跳动7个月前03580
浙大 × 通义实验室提出 UI-S1:用“半在线”训练让 MLLM 更懂图形界面在手机上完成一连串操作——比如从微信复制一段文字,粘贴到备忘录,再分享给钉钉好友——对人类来说是日常小事。但对 AI 来说,这是一次复杂的多步决策挑战。 近年来,基于多模态大语言模型(MLLM)的 G...多模态模型# UI-S1# 多模态大语言模型7个月前03450
宇树科技开源 UnifoLM-WMA-0:面向通用机器人的世界模型–动作架构宇树科技(Unitree)近日宣布开源其全新的机器人学习框架 —— UnifoLM-WMA-0,一个专为通用机器人学习设计的世界模型–动作(World Model–Action)架构。该模型跨越多种机...多模态模型# UnifoLM-WMA-0# 宇树科技7个月前01620