UFC:韩国科学技术院推出的通用少样本图像控制适配器在文本到图像生成领域,如何让预训练模型快速适应新的空间控制条件(如边缘图、深度图、人体姿态等),一直是一个挑战。传统方法通常需要大量标注数据和高昂的训练成本,限制了其灵活性与实用性。 GitHub:h...图像模型# UFC# 图像控制适配器7个月前01410
RecA:一种高效提升统一多模态模型图像生成能力的后训练方法近年来,统一多模态模型(Unified Multimodal Models, UMMs)因其在视觉理解与生成任务中的双重能力而受到广泛关注。这类模型旨在通过单一架构实现对图像和文本的联合建模,既能“看...图像模型# RecA# 统一多模态模型7个月前02700
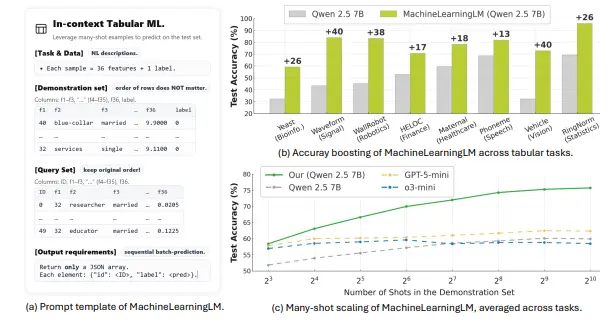
MACHINELEARNINGLM:过持续预训练提升大语言模型在多示例上下文学习能力中科院大学、华南理工大学、斯坦福大学的研究人员推出一种名为 MACHINELEARNINGLM 的新型框架,旨在通过持续预训练(continued pretraining)提升大语言模型(LLMs)在...大语言模型# MACHINELEARNINGLM7个月前01370
FLUX-Reason-6M & PRISM-Bench:600 万级 T2I 推理数据集 + 七轨道基准,开源模型研发新助力在文本到图像(Text-to-Image, T2I)生成领域,一个长期存在的困境是:开源模型越做越像,却始终难以真正“理解”复杂指令。 问题不在架构,而在数据与评估 —— 缺乏大规模、注重语义推理的训...图像模型# FLUX-Reason-6M# PRISM-Bench7个月前01300
华为开源盘古 Embedded-7B-V1.1:支持“快慢思考”的高效大模型华为正式开源新一代高效大语言模型 —— openPangu-Embedded-7B-V1.1。该模型是基于昇腾 NPU 从零训练的 7B 级别密集架构模型(不含词表 Embedding),在通用能力...大语言模型# openPangu-Embedded-7B-V1.1# 华为# 盘古7个月前03240
让语言模型“集体进化”:Gensyn推出去中心化强化学习新算法 SAPO在提升语言模型推理能力的道路上,传统方法往往依赖大量人工标注数据进行监督微调(SFT),或集中式强化学习系统完成后训练。然而,这类方式成本高昂、扩展困难,且对硬件资源要求严苛。 最近,AI初创公司 G...大语言模型# SAPO# 强化学习7个月前01140
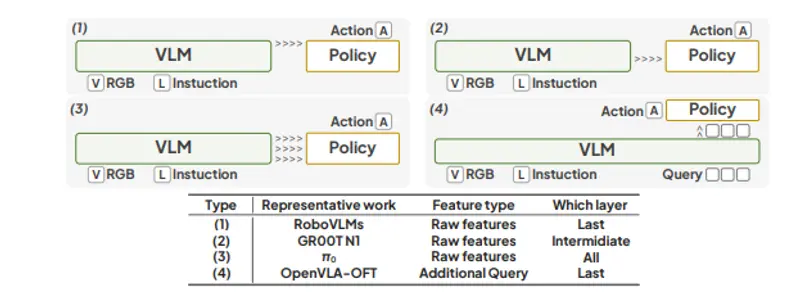
北邮、浙大等团队联合提出视觉-语言-动作模型 VLA-Adapter:用轻量桥接实现高效机器人控制在当前机器人智能领域,视觉-语言-动作(Vision-Language-Action, VLA)模型正成为连接感知与行为的核心技术。这类模型能让机器人“听懂指令”、“看懂场景”,并自主执行任务,例如...多模态模型# VLA-Adapter# 视觉-语言-动作模型7个月前04040
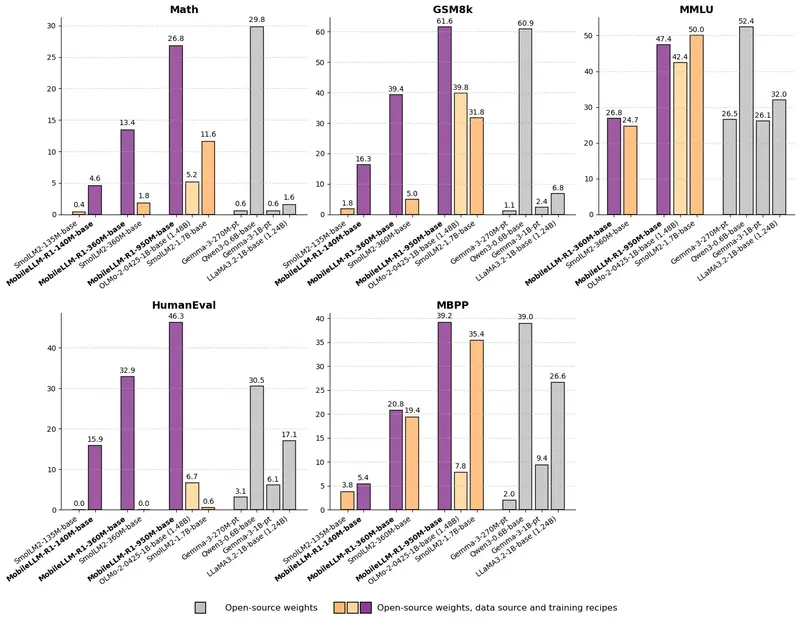
Meta 发布MobileLLM-R1 系列模型:专为数学、编程(Python/C++)和科学推理任务设计Meta 正式发布 MobileLLM-R1 系列模型,包含 140M、360M 和 950M 三款尺寸,专为数学、编程(Python/C++)和科学推理任务设计。它不是通用聊天模型,而是一个经过精细...大语言模型# Meta# MobileLLM-R17个月前02930
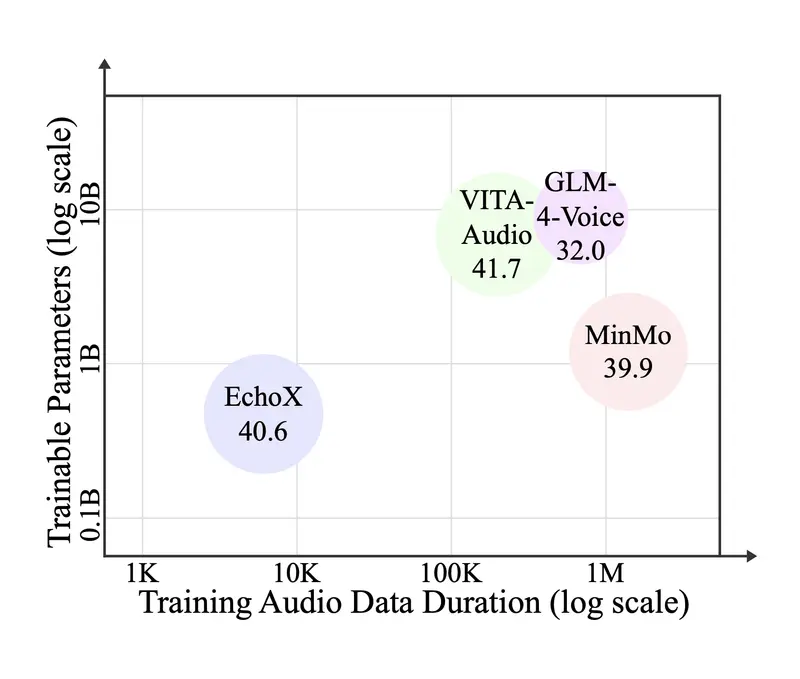
香港中文大学(深圳)提出语音到语音大语言模型EchoX:用“回声训练”弥合语音生成中的语义鸿沟近年来,语音到语音大语言模型(Speech-to-Speech LLMs, SLLMs)成为多模态 AI 的重要方向——用户说一句话,模型直接以语音回应,无需经过“语音→文本→语音”的中间转换。 但这...语音模型# EchoX# 语音到语音大语言模型7个月前01800
清华大学 & 字节跳动联合推出 HuMo:一个以人为中心的多模态视频生成框架一段文字描述 + 一张人物照片 + 一段语音音频,能否生成一个口型同步、动作自然、形象一致的高质量人物视频? 现在,可以了。 清华大学与字节跳动智能创作团队合作推出 HuMo(Human-Centri...视频模型# HuMo# 字节跳动7个月前0990
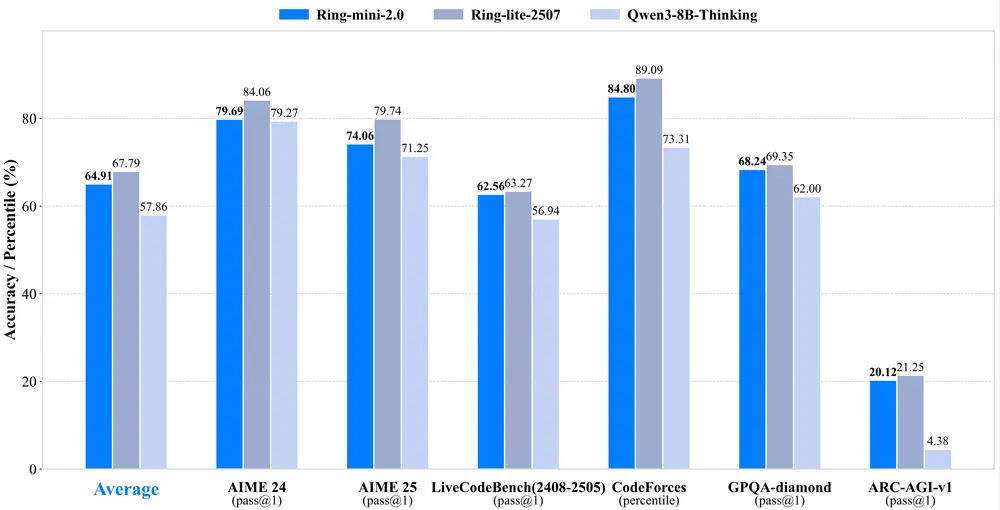
蚂蚁集团推出推理模型 Ring-mini-2.0蚂蚁集团推出了一款紧凑而强大的推理模型 Ring-mini-2.0。该模型总参数量为 16B,但每个输入 token 仅激活 14 亿个参数(非嵌入参数部分为 7.89 亿)。尽管 Ring-mini...大语言模型# Ring-mini-2.0# 推理模型# 蚂蚁集团7个月前01390
阿里Qwen团队发布Qwen3-Next-80B-A3B:用混合注意力 + 高稀疏MoE 实现极致性价比在大模型进入“长上下文”与“超大规模参数”竞争的新阶段,如何平衡性能、训练成本与推理效率,成为决定落地能力的关键。 为此,阿里通义千问(Qwen)项目组正式推出 Qwen3-Next ——一个全新设计...大语言模型# Qwen3-Next# Qwen3-Next-80B-A3B7个月前05440