腾讯混元联合高校提出 Direct-Align:用“一步恢复”实现扩散模型的高效偏好对齐在文生图模型日益成熟的今天,提升生成质量已不再是唯一目标——如何让图像真正符合人类的审美偏好,成为更高阶的挑战。 现有方法通常依赖强化学习或可微奖励机制,将模型输出与人类偏好对齐。但这些方法普遍存在两...图像模型# Direct-Align# flux.1-dev-SRPO# 腾讯混元7个月前02000
字节跳动开源UMO:统一多身份优化框架,让AI准确“认出”每个人在图像定制领域,个性化生成已逐渐从“一个人一个风格”迈向“多人协同场景”的复杂需求。然而,当一张图中需要同时呈现多个真实人物时,模型常常出现“张冠李戴”——面部特征混淆、身份错位,导致输出失真。这不仅...图像模型# UMO# 字节跳动7个月前04170
Stable Audio 2.5 发布:Stability AI 推出首款企业级音效制作专用音频模型Stability AI 正式推出 Stable Audio 2.5——这是业内首款专为企业级音效制作设计的音频生成模型。该模型聚焦企业在规模化定制高质量音频时的核心需求,通过技术升级与生态合作,助力...语音模型# Stability AI# Stable Audio 2.57个月前01950
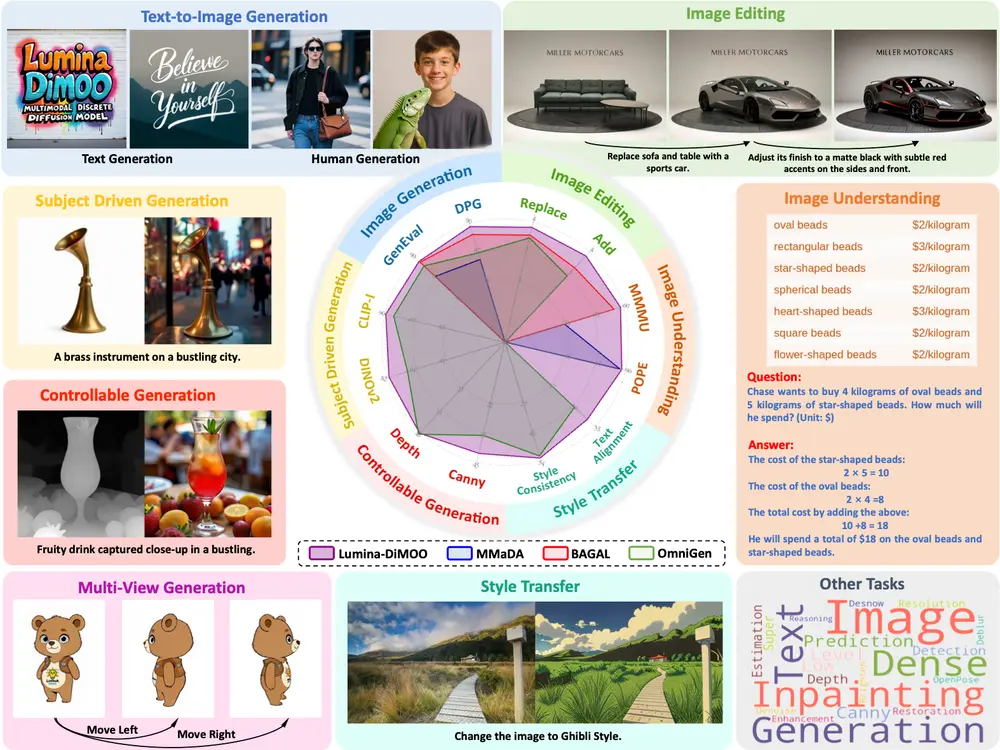
中国团队推出 Lumina-DiMOO:支持生成与理解的全能多模态模型由上海人工智能实验室牵头,联合上海创智学院、上海交通大学、悉尼大学、南京大学、香港中文大学和清华大学的研究团队,共同推出 Lumina-DiMOO ——一个面向多模态生成与理解一体化的新型基础模型。 ...图像模型# Lumina-DiMOO# 多模态模型7个月前02740
字节跳动 & 港大推出 Mini-o3:可扩展多轮推理的开源视觉智能体字节跳动与香港大学联合发布 Mini-o3 ——一个具备强大图像理解与长程多轮交互能力的开源多模态模型。该模型能够生成类似 OpenAI o3 风格的代理行为轨迹,在复杂视觉搜索任务中实现数十轮持续推...多模态模型# Mini-o3# 视觉智能体7个月前02130
字节跳动发布 Seedream 4.0:首次支持多模态生图,同一模型实现 文生图、图像编辑、组图生成字节跳动正式推出 Seedream 4.0(即梦图片4.0),新一代图像创作模型。该模型在前代 Seedream 3.0 和 SeedEdit 3.0 的基础上,全面增强逻辑理解与多模态推理能力,首次...图像模型# Seedream 4.0# 即梦图片4.0# 字节跳动7个月前04180
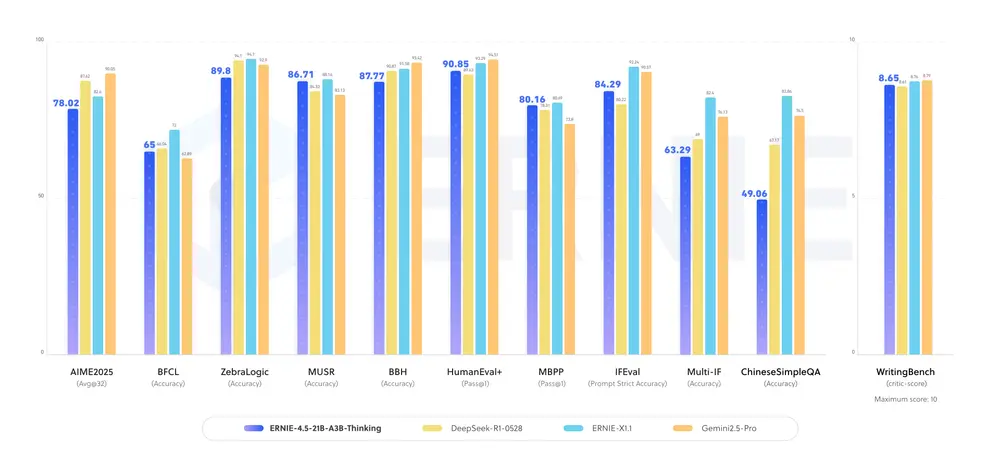
百度推出轻量级推理模型ERNIE-4.5-21B-A3B-Thinking:原生支持函数调用,可联网查天气、调数据库百度推出ERNIE-4.5-21B-A3B-Thinking,一款专为复杂推理任务优化的轻量级 MoE(Mixture of Experts)大模型。该模型在原有 ERNIE-4.5 基础上显著提升了...大语言模型# ERNIE-4.5-21B-A3B-Thinking# 百度7个月前01570
腾讯混元开源 HunyuanImage 2.1:支持 2K 分辨率的高效文生图模型腾讯混元项目组正式开源HunyuanImage 2.1,一款支持 2048×2048 超高分辨率(2K)生成的文生图模型。该模型在语义对齐、细节控制与推理效率方面实现显著提升,具备电影级构图能力,并原...图像模型# HunyuanImage 2.1# 文生图模型7个月前04770
AnimaX:支持任意骨骼结构的高效 3D 动画生成框架由北京航空航天大学软件学院、清华大学、香港大学与 VAST 联合提出的新框架 AnimaX,为 3D 角色动画生成带来了一种高效且通用的解决方案。 项目主页:https://anima-x.githu...3D模型# 3D 动画生成# AnimaX7个月前01120
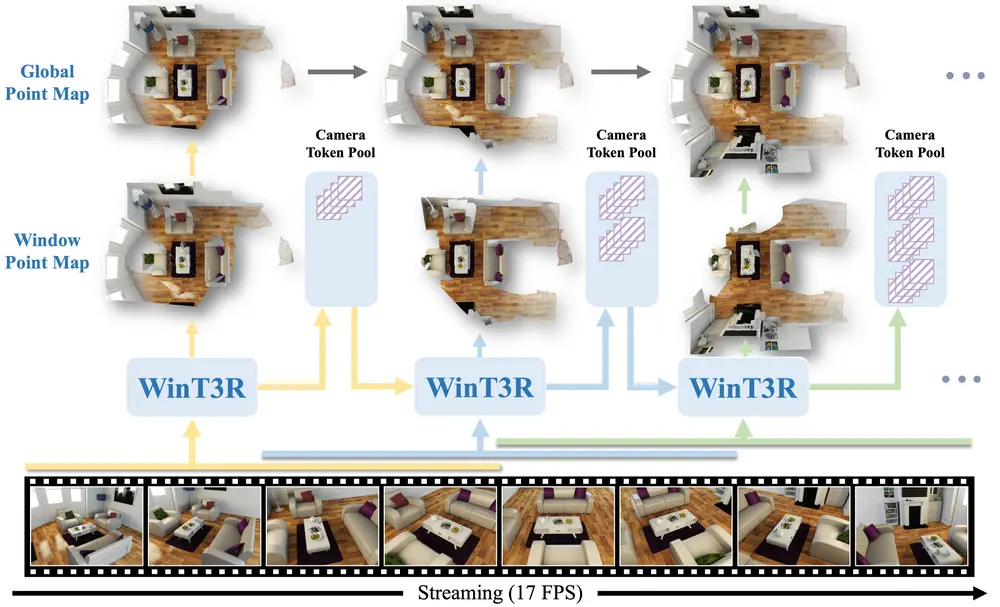
中科大等提出 WinT3R:一种兼顾高精度与实时性的在线 3D 重建新方法由中国科学技术大学、上海人工智能实验室、SII 与浙江大学联合提出的新模型 WinT3R(Window-based Streaming Reconstruction with Camera Token...3D模型# 3D 重建# WinT3R7个月前02290
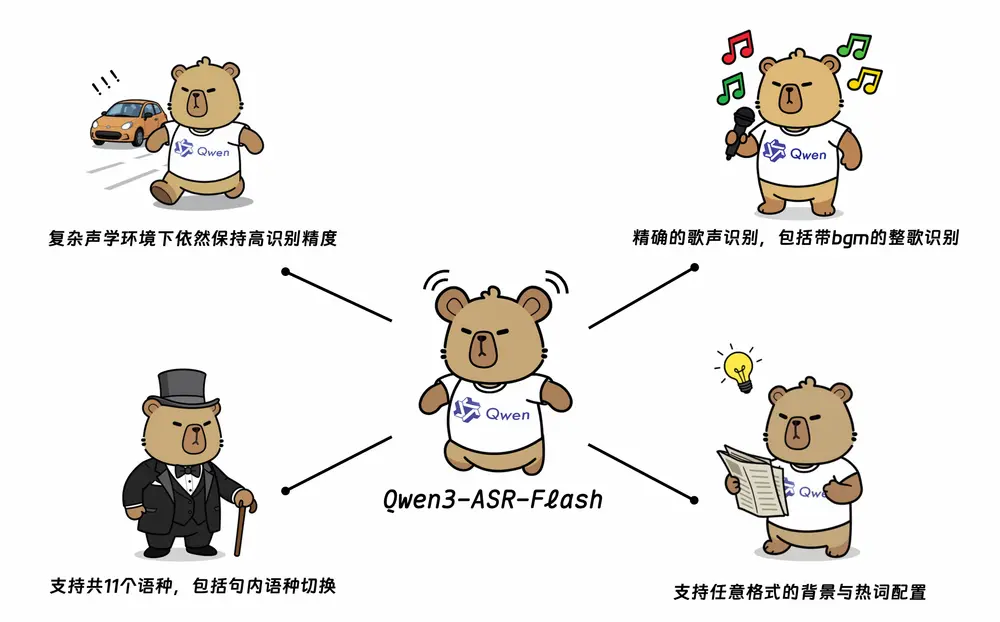
阿里通义实验室发布 Qwen3-ASR-Flash:支持多语种、歌声识别与上下文定制的新一代语音识别服务阿里通义实验室近日正式推出 Qwen3-ASR-Flash,一款基于 Qwen3 大模型基座 构建的高性能语音识别(ASR)服务。该服务融合千万小时级语音数据与海量多模态训练样本,致力于在准确率、鲁棒...语音模型# Qwen3-ASR-Flash7个月前01190
SGP-Gen :用强化学习提升大模型生成 SVG 图像的能力由香港中文大学、西湖大学、上海人工智能实验室与马克斯·普朗克智能系统研究所联合开展的研究团队,近日推出 SGP-Gen ——一项探索大语言模型(LLM)在符号图形编程(Symbolic Graphic...大语言模型# SGP-Gen# SVG 图像7个月前02960