突破 SD3.5/FLUX.1!TiM模型实现少步高效与多步高质无缝衔接来自香港中文大学MMLab、上海人工智能实验室和悉尼大学的研究团队,推出了一款名为Transition Models (TiM) 的新型生成模型。该模型通过重构生成学习的核心目标,成功破解了生成模型领...图像模型# Transition Models# 生成模型7个月前02690
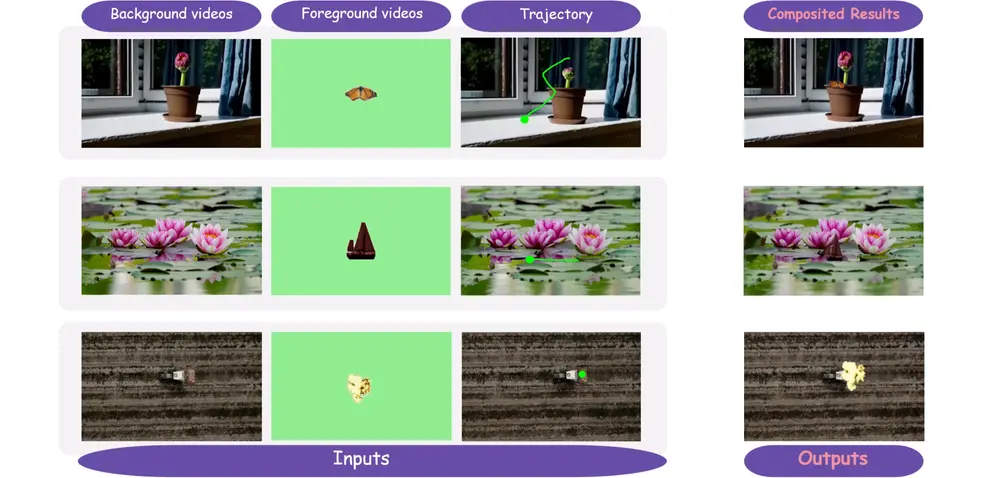
新型视频合成方法GenCompositor:实现轨迹可控的视频级前景融合由北京大学经济与管理学院、腾讯PCG ARC实验室、大湾区大学与香港中文大学联合提出的新型视频合成方法 GenCompositor,为视频创作中的“前景-背景融合”问题提供了一种自动化解决方案。该方法...视频模型# GenCompositor# 视频合成7个月前01110
Drawing2CAD:一键把二维工程图转成三维参数化 CAD 模型在工业设计、机械工程、产品开发领域,有一个长期存在的“效率瓶颈”: 设计师画好了二维工程图 → 工程师手动在 CAD 软件里重建三维模型 → 耗时、易错、难迭代。 现在,这个问题有了一个自动化解法 ...图像模型# CAD 模型# Drawing2CAD7个月前05730
POINTS-Reader:无需蒸馏、端到端的轻量级文档视觉语言模型腾讯、上海交通大学与清华大学联合推出 POINTS-Reader —— WePOINTS 家族最新成员,一款专为文档图像转文本设计的轻量级视觉-语言模型(VLM)。 GitHub:https://gi...多模态模型# POINTS-Reader# 文档视觉语言模型7个月前02330
阿里通义千问上线 Qwen-3-Max-Preview:当前系列最强语言模型阿里Qwen项目组近日在官网及 OpenRouter 平台正式推出 Qwen-3-Max-Preview,并将其定义为通义千问系列中当前最强大的语言模型。 该模型基于 Qwen3 架构进一步优化,在推...大语言模型# Qwen-3-Max-Preview# 阿里7个月前0980
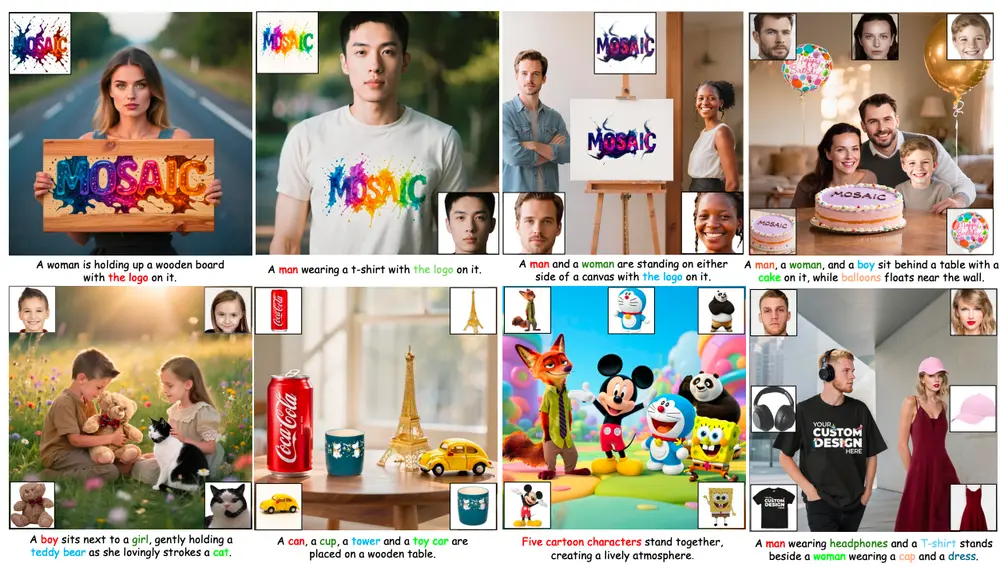
MOSAIC:通过语义对齐与特征解耦实现高保真的多主体个性化生成在个性化图像生成任务中,我们常常希望将多个参考主体(如人物、动物、物体)的特征融合到一张新图像中——例如,“让A的脸型、B的发型、C的表情和D的服饰出现在同一人身上”。这类任务被称为多主体个性化生成...图像模型# MOSAIC# 个性化生成7个月前01700
基于图像编辑模型的 FE2E:革新单目密集几何预测在单目深度估计、表面法线预测等密集几何预测任务中,如何在有限标注数据下实现高精度的零样本泛化,一直是三维视觉的核心挑战。 近年来,研究者尝试利用文本到图像生成模型(如Stable Diffusion...图像模型# FE2E# 图像编辑7个月前03120
Face-MoGLE:一种面向高保真与可控人脸生成的新框架在生成模型中,可控人脸合成是一项极具挑战的任务。既要保证生成图像的真实感与细节质量,又要实现对发型、五官、表情等语义属性的精确控制,二者往往难以兼顾。 现有方法常将语义条件直接拼接或交叉注意力注入生成...图像模型# Face-MoGLE# 人脸生成7个月前03180
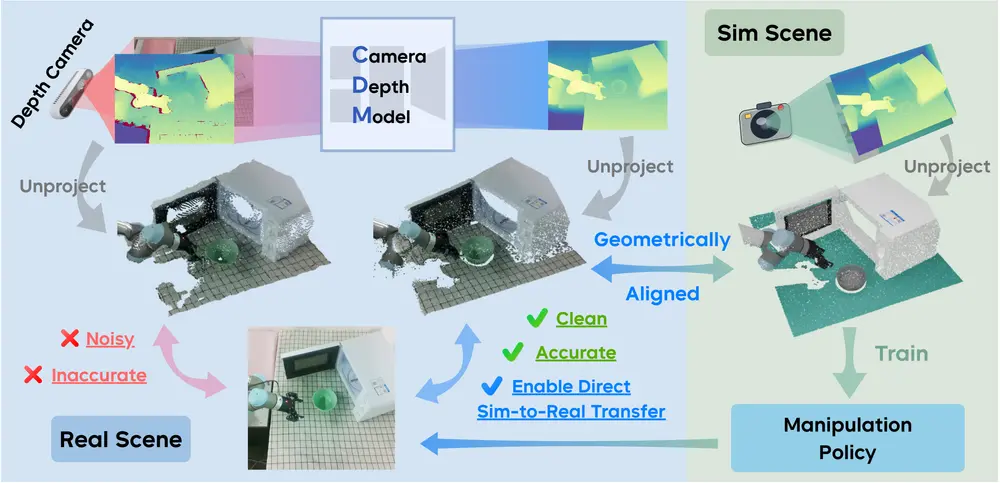
CDMs:让机器人“看清”三维世界,实现从仿真到现实的无缝迁移在机器人技能学习中,视觉感知是决策与操作的基础。然而,当前大多数方法依赖2D彩色图像作为输入——这种模式虽能捕捉纹理和颜色,却难以准确理解物体的距离、大小、形状等关键几何信息。 相比之下,人类在与环境...多模态模型# CDMs# 机器人7个月前0960
谷歌推出EmbeddingGemma:专为设备端设计的高性能开放嵌入模型在构建轻量级、隐私优先的 AI 应用时,如何在资源受限的设备上实现高质量语义理解,是一大挑战。传统的嵌入模型往往依赖云端计算,带来延迟、隐私和离线可用性问题。 为此,谷歌推出 EmbeddingGem...大语言模型# EmbeddingGemma# 嵌入模型# 谷歌7个月前02530
Instinct:由 Continue 打造的全球首个开放 Next Edit 模型在代码编辑中,真正消耗时间的往往不是“写代码”,而是重构、调整、维护与迭代。传统自动补全工具只能在光标处插入文本,面对复杂的多行修改仍需手动操作,打断开发节奏。 为此,开发工具团队 Continue ...大语言模型# Continue# Instinct# Next Edit 模型7个月前02990
月之暗面发布 Kimi K2 新版本(0905):编程能力再升级,支持 256K 上下文与高速 API月之暗面宣布推出其旗舰模型 Kimi K2 的最新版本(0905),重点针对真实编程任务进行优化,在代码生成能力、上下文处理、API 性能和平台兼容性等方面实现多项重要升级。 此次更新聚焦于提升模型在...大语言模型# Kimi K2# Kimi-K2-Instruct-0905# 月之暗面7个月前02400