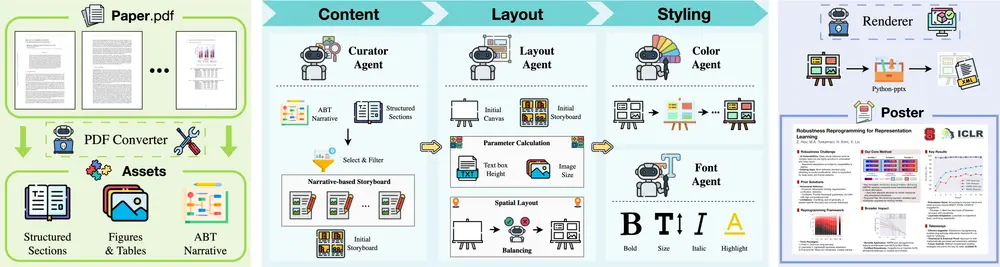
PosterGen:用多智能体系统自动生成高质量学术海报对研究人员而言,撰写论文只是第一步。在会议展示阶段,如何将复杂的研究内容浓缩成一张信息清晰、视觉美观、叙事连贯的学术海报,是一项耗时且需要设计经验的任务。 尽管已有自动化工具尝试解决这一问题,但大多数...图像模型# PosterGen# 学术海报7个月前04440
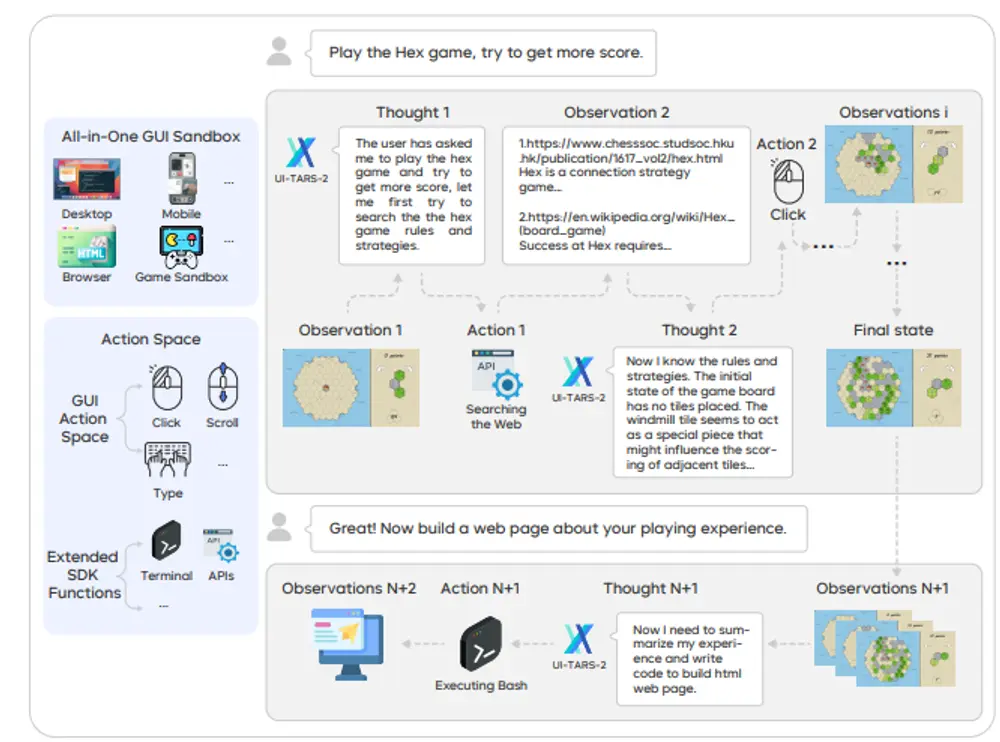
字节跳动发布UI-TARS-2:一个面向真实GUI交互的原生代理模型在图形用户界面(GUI)日益复杂的背景下,如何让AI代理像人类一样流畅操作系统、完成多步骤任务,是自动化与智能体研究的重要方向。然而,当前自主GUI代理的发展仍面临诸多挑战:训练数据难以规模化获取、多...大语言模型# UI-TARS-27个月前01670
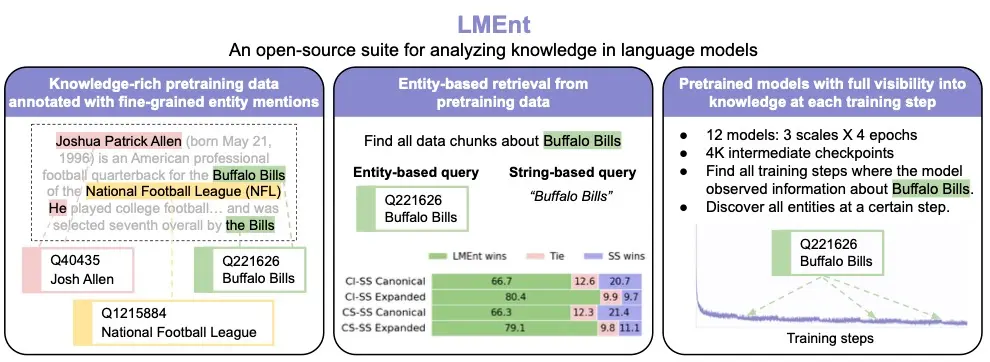
大语言模型知识获取研究新工具:特拉维夫大学与麦吉尔大学推出 LMEnt 套件语言模型正在越来越多地承担需要世界知识的任务:回答问题、生成事实性文本、辅助决策……但一个根本性问题仍未解决: 模型是如何从训练数据中“学会”知识的? 我们训练模型时喂的是文本,但它输出的却是“信念...大语言模型# LMEnt# 大语言模型7个月前01480
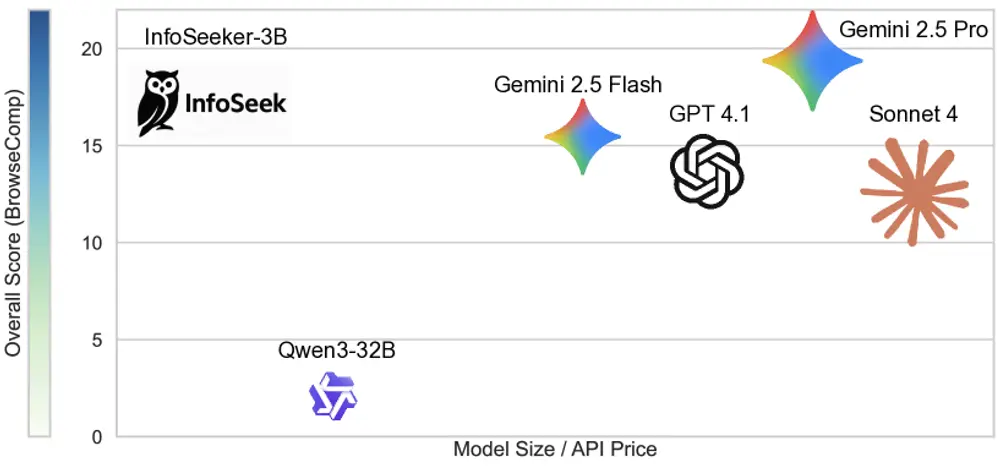
InfoSeek:智源研究院提出可扩展的深度研究数据合成框架在大模型迈向“自主思考”的过程中,一个关键瓶颈逐渐显现: 现有基准任务太简单,无法真正测试模型的复杂推理能力。 Natural Questions、HotpotQA 等主流数据集虽然推动了多跳推理的发...大语言模型# InfoSeek# 深度研究7个月前02550
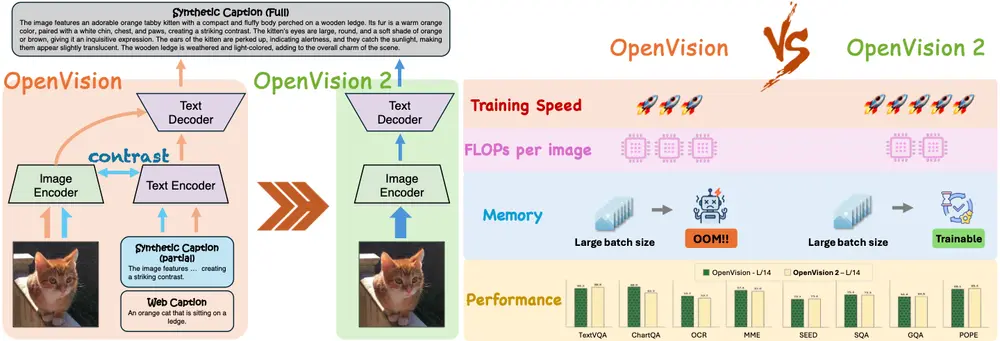
OpenVision 2:更高效、更对齐的生成式视觉编码器在多模态大模型(MLLM)快速发展的今天,一个核心问题日益凸显:预训练视觉编码器的训练方式是否真的适配下游任务? 传统方法依赖图像-文本对比学习(如 CLIP),但这类模型在接入 LLM 进行微调时...多模态模型# OpenVision 2# 视觉编码器7个月前01910
Pusa Wan2.2 V1.0:将开创性的 Pusa 范式扩展到先进的 Wan2.2-T2V-A14B 架构Pusa Wan2.2 V1.0 将开创性的 Pusa 范式扩展到先进的 Wan2.2-T2V-A14B 架构,该架构采用 MoE DiT 设计,包含独立的噪声和高噪声模型。这种架构提供了增强的质量控...视频模型# Pusa Wan2.2 V1.0# Wan2.2-T2V-A14B7个月前02420
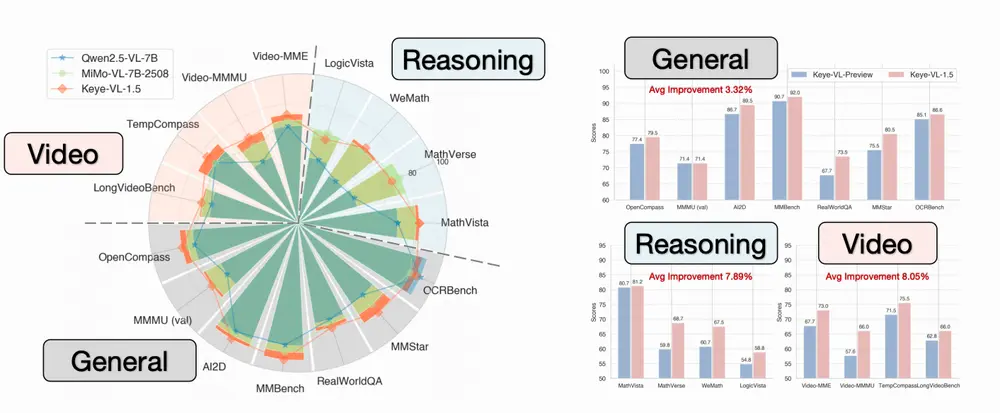
快手 Keye 团队发布Keye-VL-1.5 :支持 128K 上下文的视频理解大模型在多模态大模型的竞争中,视频理解正成为下一个关键战场。相比图像,视频包含更丰富的时空信息——动作的起止、事件的因果、场景的演变。要让AI真正“看懂”一段视频,不仅需要识别画面内容,还要理解时间逻辑与行...多模态模型# Keye-VL-1.5# 快手# 视频理解大模型7个月前0770
ElevenLabs 发布音效生成模型SFX v2:音效生成更真实,支持无缝循环ElevenLabs 今天推出了其音效生成模型 SFX v2,在音质、功能和使用体验上实现多项重要升级。现在,用户只需输入一段文字提示,即可生成高质量、可循环的环境音效,适用于有声书、播客、视频、冥想...语音模型# ElevenLabs# SFX v2# 音效生成模型7个月前02110
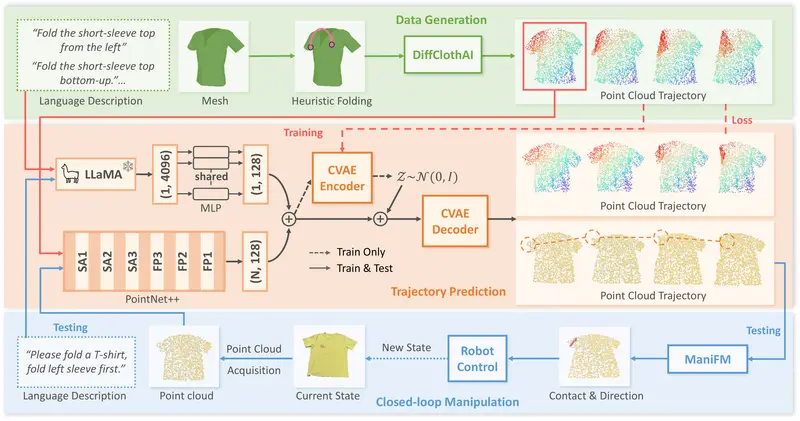
MetaFold:用语言指导机器人叠衣服,还能通用于不同衣物让机器人叠衣服,听起来简单,做起来极难。 布料柔软、易变形,同一件T恤每次摆放的形态都不同。这种高度的可变性使得机器人难以像抓取刚性物体那样,靠预设动作完成操作。更别说还要应对不同款式——无袖、短袖...多模态模型# MetaFold7个月前01130
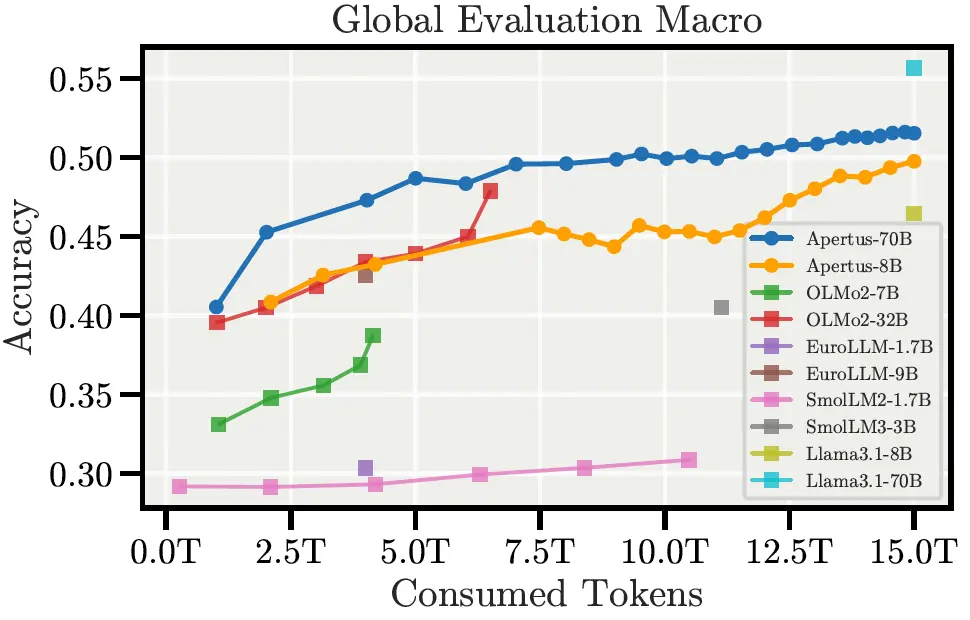
瑞士发布国家级开源大模型 Apertus,构建自主可控、合规透明的AI基础设施瑞士近日正式推出其国家级开源大语言模型 Apertus,标志着该国在构建自主可控、合规透明的人工智能基础设施方面迈出关键一步。 这一模型由 洛桑联邦理工学院(EPFL)、苏黎世联邦理工学院(ETH Z...大语言模型# Apertus# 开源大模型# 瑞士7个月前02740
阿里发布 AgentScope 1.0:面向生产级智能体的开源开发框架阿里巴巴近日正式推出 AgentScope 1.0 —— 一个以开发者为核心的开源智能体(Agent)开发框架,致力于解决当前智能体应用在可控性、可维护性和落地部署方面的关键挑战。 不同于仅聚焦于单点...大语言模型# AgentScope 1.0# 智能体开发框架# 阿里巴巴7个月前01840
腾讯发布混元世界模型 - Voyager:单图生成 3D 场景,实现长距离沉浸式探索腾讯今天正式推出混元世界模型 - Voyager(HunyuanWorld-Voyager),这是一款创新的视频扩散框架。其核心能力在于:基于单张输入图像即可生成具备世界一致性的 3D 点云,支持用户...视频模型# HunyuanWorld-Voyager# 混元世界模型 - Voyager# 腾讯7个月前0780