艾伦AI研究所推出全新开源 ASR 模型家族OLMoASR在自动语音识别(ASR)领域,Whisper 一直是开源社区的标杆——强大、鲁棒、支持零样本迁移。但它有一个根本局限:训练数据未公开,模型行为难以分析,也无法完全复现。 现在,艾伦人工智能研究所(AI...语音模型# OLMoASR# 艾伦AI研究所7个月前01450
腾讯混元开源轻量级翻译模型 Hunyuan-MT-7B:33语种互译,小模型也能大作为腾讯混元宣布将其国际翻译模型 Hunyuan-MT-7B 正式开源,供全球开发者免费下载与本地部署。同时开源的还有业界首个翻译集成模型 Hunyuan-MT-Chimera-7B(奇美拉),支持多译文...大语言模型# Hunyuan-MT-7B# 翻译模型# 腾讯7个月前02000
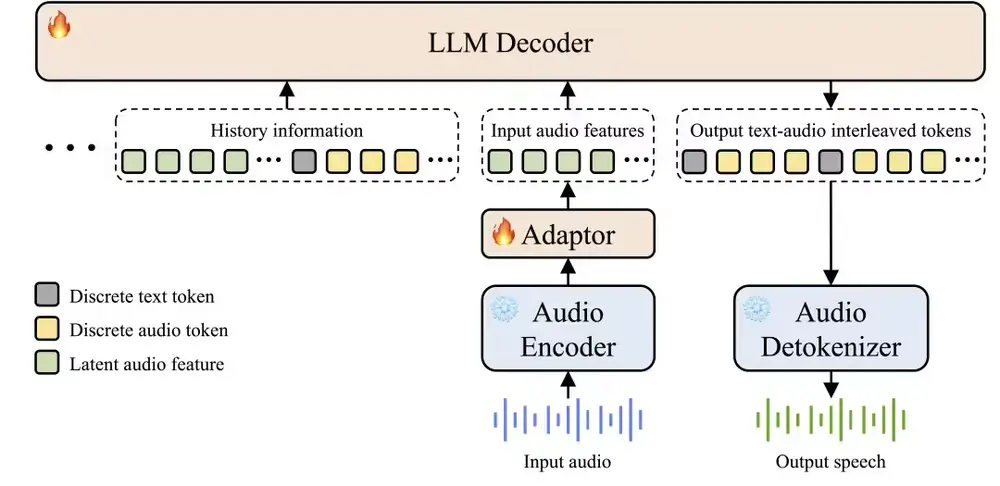
阶跃星辰发布开源语音大模型Step-Audio 2 mini:多任务性能登顶SOTA,攻克语音AI“智商情商”痛点今日,阶跃星辰正式发布开源端到端语音大模型Step-Audio 2 mini,该模型在音频理解、语音识别、翻译及对话等多个国际基准测试集中均斩获SOTA(state-of-the-art,当前最优)成...语音模型# Step-Audio 2 mini# 阶跃星辰7个月前02600
CoMPaSS:让AI“看懂”空间关系,提升文生图模型的空间理解能力尽管当前的文本到图像(Text-to-Image, T2I)扩散模型能够生成高度逼真的图像,但在一个关键任务上仍频频失手:准确理解并渲染文本中描述的空间关系。 例如,当用户输入: “一个棕色皮革沙发放...图像模型# CoMPaSS7个月前01820
蚂蚁集团开源医学智能体MedResearcher-R1:以知识引导技术破解领域AI推理难题蚂蚁集团正式开源医学智能体 MedResearcher-R1,同时对外公开模型及合成数据生成方法。这一智能体聚焦医学领域AI推理的核心痛点,通过“知识图谱构建-轨迹生成-评估验证”的全流程框架,为领域...多模态模型# MedResearcher-R1# 医学智能体# 蚂蚁集团7个月前0860
苹果发布 MobileCLIP2:更小、更快、更高效的移动端多模态模型苹果近期推出了新一代轻量级图像-文本模型家族 —— MobileCLIP2,在保持高精度的同时,显著降低模型体积与推理延迟,专为移动设备上的实时多模态理解任务而设计。 GitHub:https://g...多模态模型# MobileCLIP2# 图像-文本模型# 苹果7个月前0850
苹果推出视觉语言模型FastVLM:用更少的视觉 Token,更快理解高分辨率图像苹果近期发布了 FastVLM系列视觉语言模型,并首次引入其自研混合视觉编码器 FastViTHD。该模型解决当前多模态系统在处理高分辨率图像时面临的效率瓶颈,尤其在移动端和实时交互场景中展现出显著优...多模态模型# FastVLM# 苹果# 视觉语言模型7个月前0910
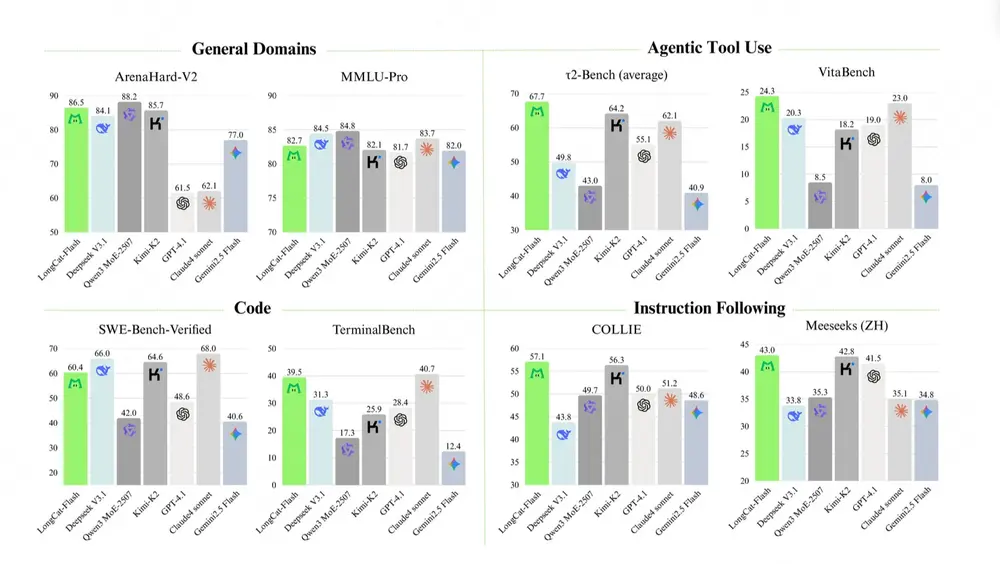
美团LongCat团队发布5600亿参数模型LongCat-Flash,以MoE架构突破效率与性能瓶颈美团LongCat团队正式推出大语言模型LongCat-Flash,该模型以5600亿总参数规模为基础,创新采用专家混合(MoE)架构,通过动态计算、架构优化等核心设计,在训练效率、推理性能与实用能力...大语言模型# LongCat-Flash# 美团7个月前01350
xAI 推出 Grok Code Fast 1:瞄准 GitHub Copilot,主打“快速且经济”的编程辅助埃隆·马斯克旗下的 xAI 正式发布代理式编码模型 Grok Code Fast 1,直接对标微软 GitHub Copilot 和 OpenAI Codex。这款基于全新架构构建的模型,以“速度快...大语言模型# Grok Code Fast 1# 编程辅助7个月前0720
Nous Research 发布 Hermes 4:无内容限制,数学性能超越 ChatGPT 的开源 AI 新选择神秘的 AI 初创公司 Nous Research 本周悄然推出开源大语言模型家族 Hermes 4。该公司声称,这一系列模型不仅在性能上比肩主流专有系统,更以“最小内容限制”和“用户高度可控”为核心...大语言模型# Hermes 4# Nous Research7个月前04830
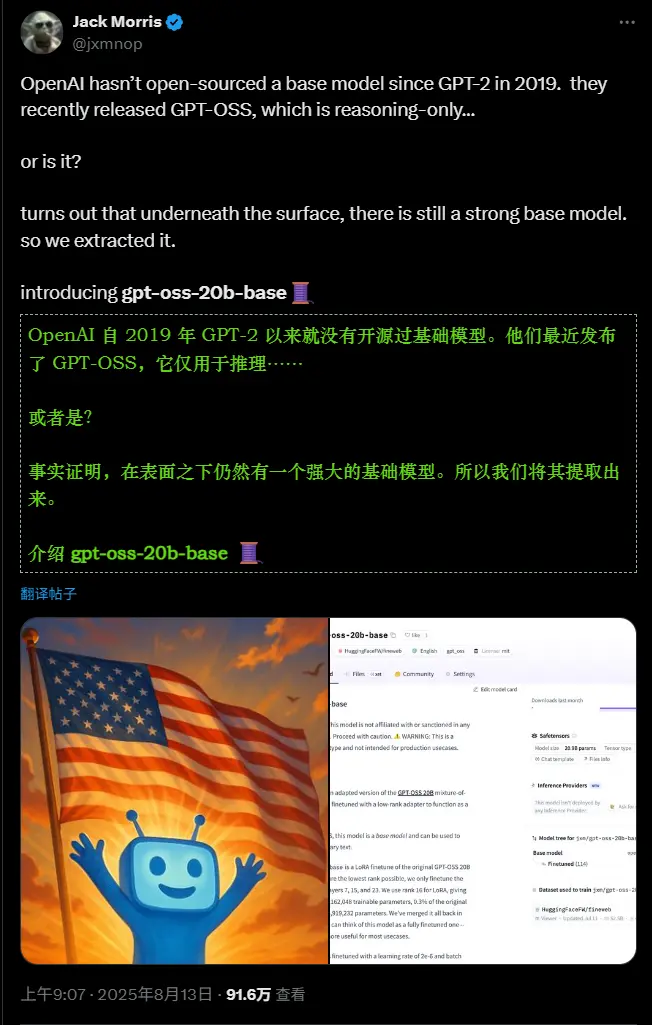
研究员改造 OpenAI 开源模型 gpt-oss-20b:移除推理约束,还原 “无对齐” 基础版本8月初,OpenAI 发布了其首个自 GPT-2 以来的开放权重大语言模型系列 gpt-oss,包含 200 亿(gpt-oss-20b)和 1200 亿(gpt-oss-120b)参数两个版本,采用...大语言模型# gpt-oss-20b# gpt-oss-20b-base7个月前01880
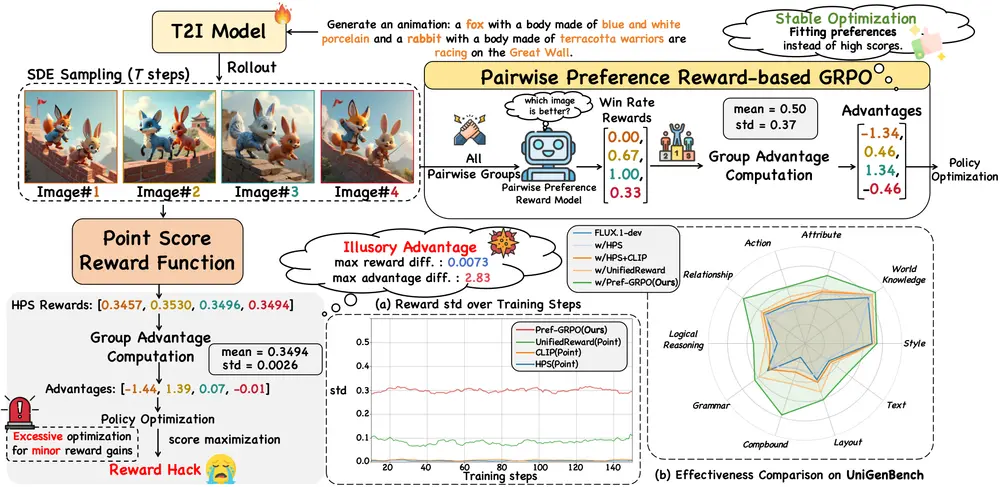
复旦等团队联合突破文生图模型生成瓶颈:Pref-GRPO解决奖励操控,UniGenBench补上评估短板文本到图像(T2I)生成技术的进步,离不开强化学习方法的优化与基准测试的支撑。但当前领域存在两大核心问题:一是传统强化学习依赖“点式奖励模型”打分,易出现“分数涨而质量降”的奖励操控现象;二是现有基准...图像模型# Pref-GRPO# 文生图模型7个月前03450