腾讯混元宣布将其国际翻译模型 Hunyuan-MT-7B 正式开源,供全球开发者免费下载与本地部署。同时开源的还有业界首个翻译集成模型 Hunyuan-MT-Chimera-7B(奇美拉),支持多译文融合优化。
- 项目主页:https://hunyuan.tencent.com/llm/zh?tabIndex=0
- 模型:https://huggingface.co/collections/tencent/hunyuan-mt-68b42f76d473f82798882597
- 魔塔:https://modelscope.cn/collections/Hunyuan-MT-2ca6b8e1b4934f
这一系列动作标志着腾讯在机器翻译领域的技术积累正逐步向社区开放,也为轻量级、高精度翻译模型的应用提供了新选择。
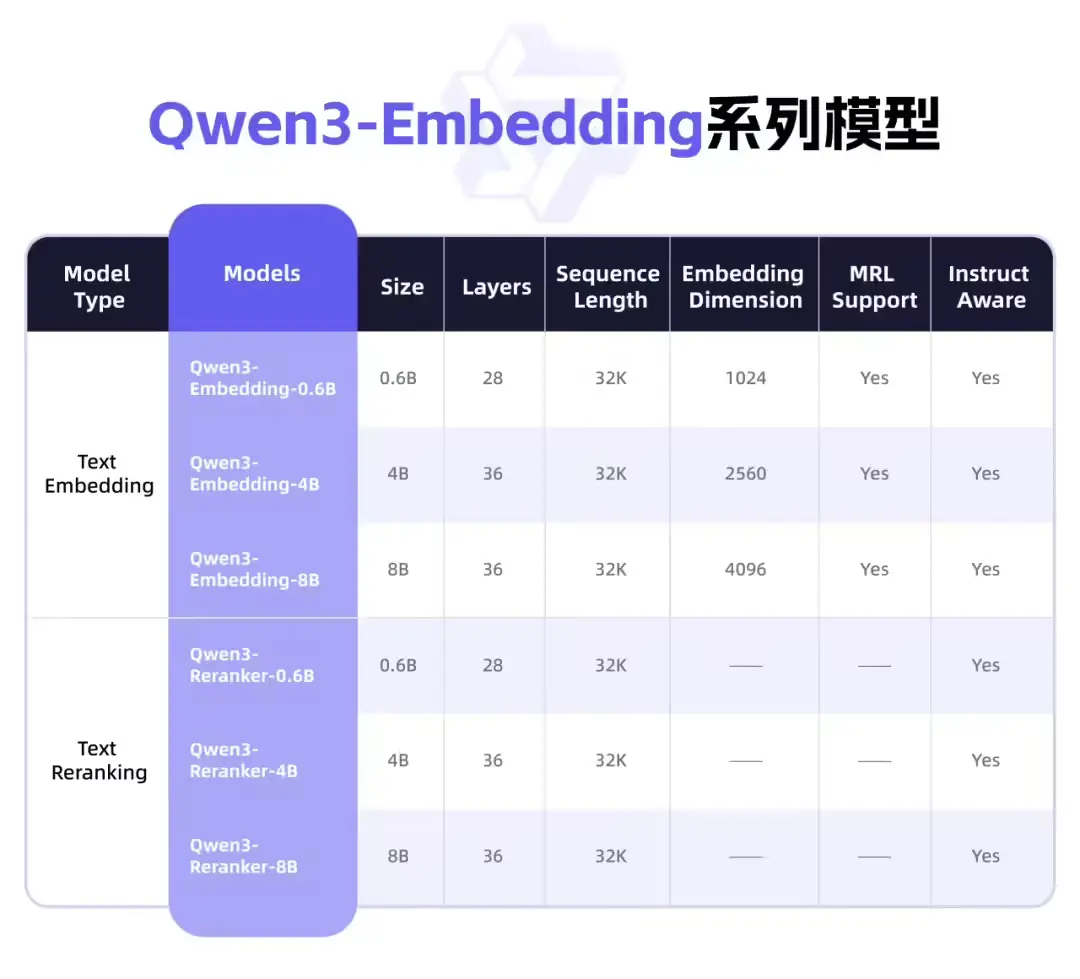
模型概览
Hunyuan-MT-7B 是一个参数量为 70亿 的多语言翻译模型,具备以下核心能力:
- 支持 33个语种 之间的互译,覆盖中、英、日、德、法、西等主流语言
- 支持 5种民族语言与汉语互译(如藏语-汉语、维吾尔语-汉语等)
- 模型轻量,适合在中端GPU上部署,兼顾性能与成本
配套开源的 Hunyuan-MT-Chimera-7B 并非传统翻译模型,而是一个翻译结果集成器:它能接收多个翻译模型的输出,结合原文,生成更准确、流畅的最终译文,显著提升翻译质量。
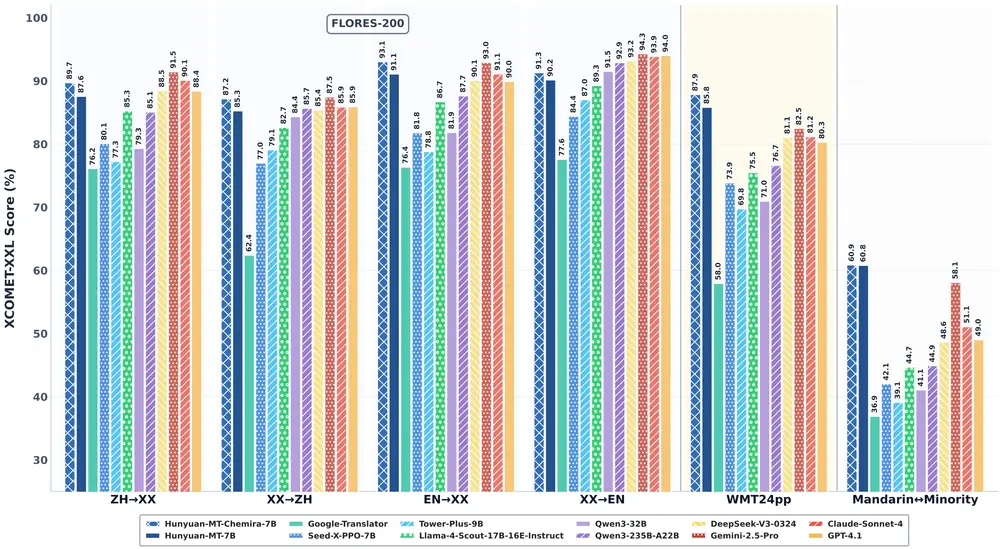
技术突破:小模型为何能赢?
在2025年国际计算语言学协会(ACL)旗下的 WMT25 翻译竞赛中,Hunyuan-MT-7B(参赛名:Shy-hunyuan-MT)在31个语向比赛中斩获 30项第一,涵盖捷克语、爱沙尼亚语、冰岛语、马拉地语等小语种。
值得注意的是,WMT25 对参赛模型有严格限制:
- 必须完全基于公开数据集训练
- 模型需满足开源要求
- 不允许使用闭源语料或私有增强技术
在这些约束下,Hunyuan-MT-7B 凭借 7B 参数量击败多个更大规模模型,证明其单位参数效率处于行业领先水平。
在通用评测集 Flores-200 上,该模型同样表现优异,翻译质量明显优于同尺寸竞品,部分语向接近甚至媲美百亿级模型。
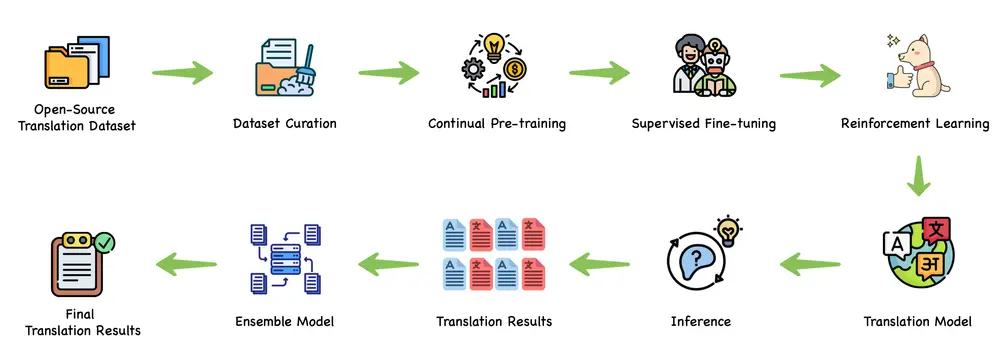
训练范式:从预训练到集成强化
腾讯混元提出了一套完整的翻译模型训练流程,覆盖全链路优化:
- Pretrain:大规模多语言语料预训练,建立基础语言理解能力
- CPT(Conditional Prefix Tuning):引入条件前缀机制,提升跨语言对齐精度
- SFT(Supervised Fine-Tuning):在高质量双语数据上进行监督微调
- 翻译强化:通过强化学习优化流畅性与忠实度
- 集成强化:训练 Chimera 模型,融合多源译文并生成最优结果
这一范式不仅提升了单模型性能,也为后续翻译系统的可解释性与可控性打下基础
Hunyuan-MT-Chimera:首个开源翻译集成模型
传统翻译系统通常依赖单一模型输出,而 Chimera 的创新在于:
- 接收来自不同模型(如 Hunyuan-MT、DeepSeek 等)的多个候选译文
- 结合原文语义,自动判断各版本优劣
- 输出一个综合质量更高的“融合译文”
这种“多模型投票+智能集成”的方式,在专业翻译、法律文档、技术手册等对准确性要求高的场景中尤为有效。
开发者可通过 API 或本地部署方式接入 Chimera,构建自己的高质量翻译流水线。
已在腾讯多业务落地
目前,Hunyuan 翻译模型已深度集成至多个腾讯产品中:
- 腾讯会议:实时字幕翻译,支持跨国会议无障碍沟通
- 企业微信:跨语言消息自动翻译,提升全球化协作效率
- QQ浏览器:网页内容一键翻译,覆盖小语种页面
- 翻译君:提供离线与在线翻译服务
- 海外客服系统:自动翻译用户问题,提升响应速度
这些真实场景的打磨,使模型在鲁棒性、延迟控制和领域适应性方面更具优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











