
在构建轻量级、隐私优先的 AI 应用时,如何在资源受限的设备上实现高质量语义理解,是一大挑战。传统的嵌入模型往往依赖云端计算,带来延迟、隐私和离线可用性问题。

为此,谷歌推出 EmbeddingGemma —— 一款专为设备端 AI 打造的开放文本嵌入模型。它以仅 3.08 亿参数的轻量架构,在多语言语义表示任务中达到同规模下的最先进水平(SOTA),并支持在手机、笔记本等本地设备高效运行。
无论你是开发离线搜索、移动端 RAG 聊天机器人,还是构建隐私敏感的应用,EmbeddingGemma 都是一个理想选择。
核心特性:小模型,大能力
同类最优性能
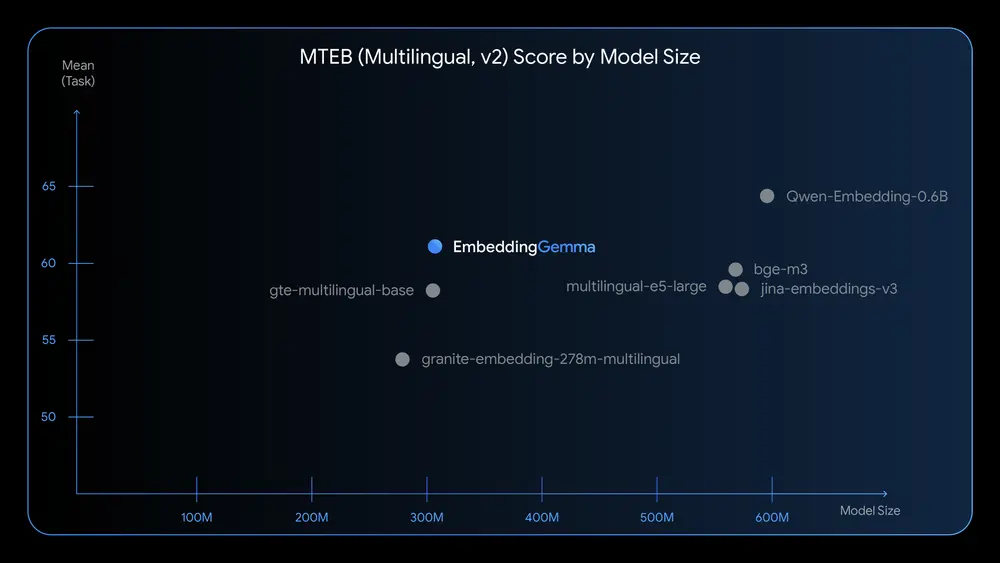
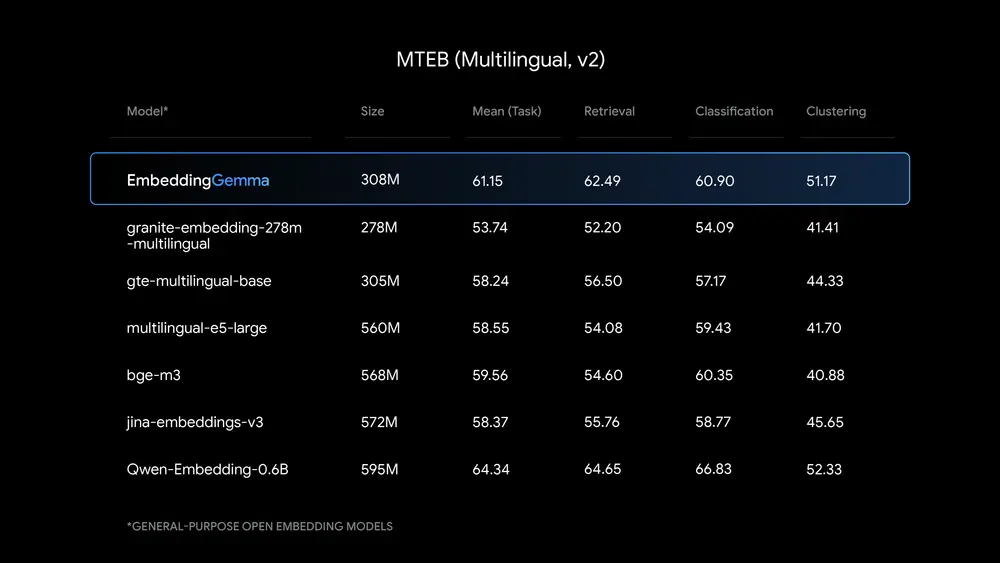
在 Massive Text Embedding Benchmark (MTEB) 上,EmbeddingGemma 是 500M 参数以下性能最高的开放多语言嵌入模型。其表现优于同级别开源模型,在语义相似度、检索准确率等关键指标上领先。
模型基于 Gemma 3 架构,在超过 100 种语言上进行训练,具备出色的跨语言理解能力。
轻量化设计,低资源运行
- 模型大小:约 200MB RAM 即可运行(经量化优化)
- 参数构成:3.08 亿参数(含 1 亿模型参数 + 2 亿嵌入参数)
- 上下文长度:支持 2K token,满足长文本处理需求
- 推理速度:在 EdgeTPU 上,256 输入 token 的嵌入生成时间 <15ms
这意味着它可在智能手机、树莓派、笔记本等日常设备上实现实时响应。
支持 Matryoshka 表示(MRL),灵活调整维度
通过 Matryoshka 表示学习(Matryoshka Representation Learning, MRL),EmbeddingGemma 支持从单一模型输出多种维度的嵌入向量:
| 维度 | 适用场景 |
|---|---|
| 768D | 高质量检索,最佳精度 |
| 512D / 256D | 平衡速度与精度 |
| 128D | 极速推理,低存储开销 |
开发者可根据设备性能或任务需求动态选择维度,无需重新训练或部署多个模型。
全面集成主流工具链
EmbeddingGemma 已支持开发者常用框架和平台,开箱即用:
- 推理引擎:
llama.cpp、MLX、LiteRT、Ollama、LMStudio、transformers.js - RAG 框架:
LangChain、LlamaIndex - 向量数据库:
Weaviate、Cloudflare Vectorize - 本地运行:支持 Android、iOS、Web、桌面端
为什么需要设备端嵌入模型?
随着 AI 应用向移动端和边缘设备延伸,隐私、延迟和离线可用性成为关键考量。
传统基于云的嵌入服务存在三大痛点:
- 隐私风险:用户数据需上传至服务器;
- 网络依赖:无网环境无法使用;
- 响应延迟:每次查询需往返云端。
EmbeddingGemma 的出现,正是为了解决这些问题:
在设备本地完成文本到向量的转换,全程无需联网,数据不出设备。
典型应用场景
1. 移动端 RAG(检索增强生成)
结合 Gemma 3n 等小型生成模型,可在手机上构建完整的离线问答系统:
- 用户提问:“上次谁修过地板?电话是多少?”
- 模型在本地邮件、笔记、通话记录中检索相关信息
- 返回结构化答案,无需上传任何个人数据
适用于个人知识库、企业内网助手、离线客服等场景。
2. 本地语义搜索
支持对设备上的文档、邮件、短信、通知等内容进行跨应用语义搜索:
- 查询“合同”可匹配“协议”“签署文件”等近义词
- 不依赖关键词匹配,理解上下文含义
- 响应速度快,体验接近原生搜索
3. 智能分类与路由
将用户输入自动分类并路由到对应功能模块:
- “帮我订会议室” → 触发日历 API
- “查一下发票” → 跳转财务系统
- 适用于智能代理、语音助手、自动化工作流
4. 领域微调与定制化
虽然 EmbeddingGemma 已具备通用语义能力,但你也可以通过少量数据进行领域微调,提升特定任务表现:
- 医疗术语理解
- 法律文书检索
- 工业设备日志分析
官方提供微调指南与 Jupyter Notebook 示例,快速上手。
技术亮点解析
1. 量化感知训练(QAT)
EmbeddingGemma 采用 Quantization-Aware Training(QAT),在训练阶段模拟低精度计算,确保模型在量化后仍保持高精度。这使得模型可在 8-bit 或更低精度下运行,大幅降低内存占用和功耗。
2. 与 Gemma 3n 分词器一致
使用与 Gemma 3n 相同的 tokenizer,便于在设备端构建端到端流水线,减少额外依赖和内存开销。
3. 高效的嵌入生成流程
输入文本 → Tokenization → 嵌入模型 → 向量输出(768D)
↓ 截断
512D / 256D / 128D
整个流程可在毫秒级完成,支持高并发、低延迟交互。
如何选择合适的嵌入模型?
谷歌提供了清晰的选型建议:
| 使用场景 | 推荐模型 |
|---|---|
| 设备端、离线、隐私敏感 | ✅ EmbeddingGemma |
| 服务器端、高吞吐、强性能 | ✅ Gemini Embedding API |
- 如果你需要在手机、IoT 设备或本地环境中运行,追求低延迟和数据安全,EmbeddingGemma 是首选;
- 如果你在云端构建大规模检索系统,追求极致质量和吞吐,可使用 Gemini API。
立即开始使用
EmbeddingGemma 已全面开放,支持多种方式接入:
下载模型
- Hugging Face: https://huggingface.co/google/embedding-gemma
- Kaggle: https://www.kaggle.com/models/google/embeddinggemma/
- Vertex AI: 支持直接调用与部署
学习资源
- 官方文档:集成指南、API 说明
- 微调教程:基于特定数据集优化模型
- Gemma Cookbook:包含 RAG 快速入门示例
支持平台
| 平台 | 支持状态 |
|---|---|
| transformers.js | ✅ |
| MLX | ✅ |
| llama.cpp | ✅ |
| LiteRT | ✅ |
| Ollama | ✅ |
| LMStudio | ✅ |
| Weaviate | ✅ |
| LangChain / LlamaIndex | ✅ |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











