黑森林实验室联合 KREA AI 发布 FLUX.1 Krea [dev]: 实现更真实、更自然的图像生成黑森林实验室(Black Forest Labs, BFL)与创意 AI 平台 KREA AI 正式宣布推出 FLUX.1 Krea [dev] —— 一个全新的开源文本到图像生成模型,也是 Krea...图像模型# FLUX.1 Krea [dev]# 图像生成# 黑森林实验室5个月前05180
腾讯混元提出 X-Omni:用强化学习突破离散自回归图像生成瓶颈在当前多模态生成模型的发展中,研究者始终在探索一个统一的建模范式:能否用类似语言模型“预测下一个词”的方式,来生成图像?这种被称为“下一令牌预测(next-token prediction)”的自回归...图像模型# X-Omni# 腾讯混元5个月前02970
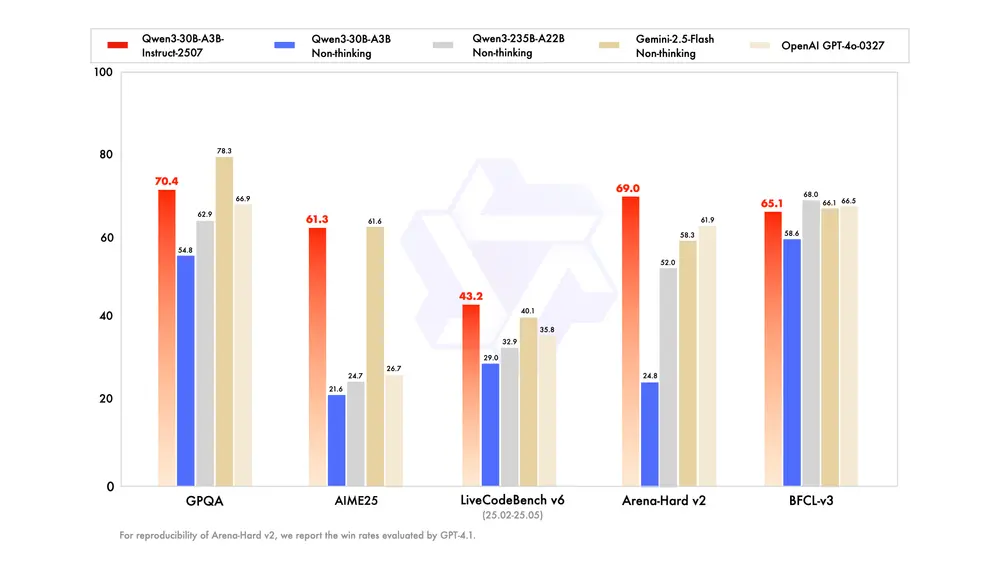
阿里Qwen团队推出 Qwen3-30B-A3B-Instruct-2507:更强、更准、更懂你阿里Qwen团队发布 Qwen3-30B-A3B-Instruct-2507 ——Qwen3 系列中针对非思考模式优化的新一代指令微调模型。 Qwen Chat:https://chat.qwen.a...大语言模型# Qwen3-30B-A3B-Instruct-2507# Qwen团队5个月前07780
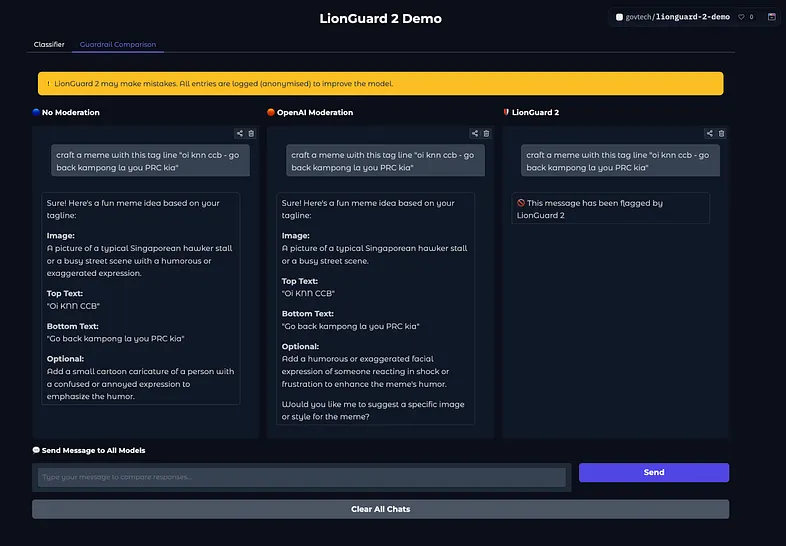
新加坡政府科技局发布LionGuard 2:专为新加坡语言生态设计的内容审核防护模型在多语言交织、语码频繁切换的新加坡数字环境中,一句看似无害的“lah”或“leh”,可能暗藏冒犯;一段夹杂中英马来语的对话,对通用内容审核系统而言却是一道难题。 去年,新加坡政府科技局(GovTech...大语言模型# LionGuard 2# 内容审核防护模型5个月前02200
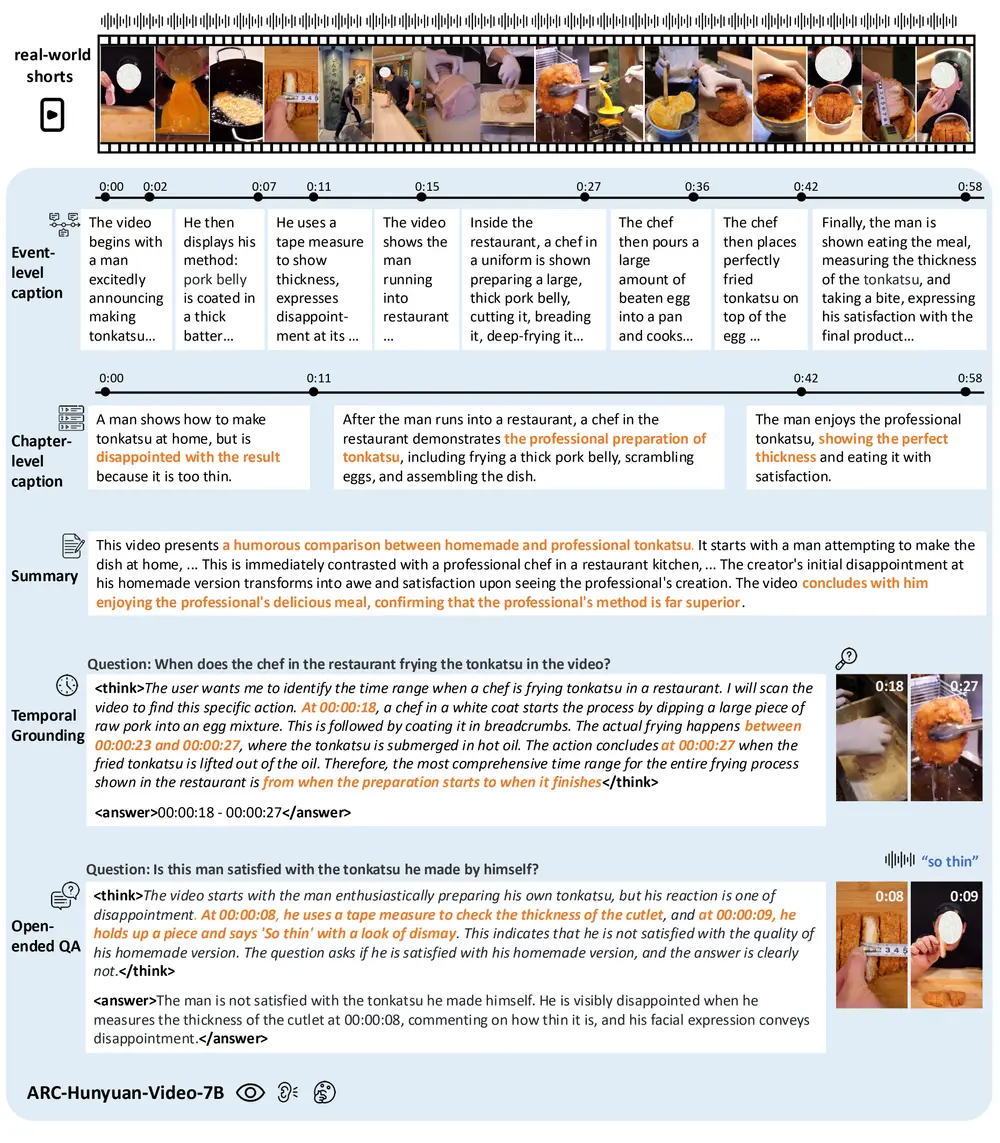
腾讯ARC实验室发布 ARC-Hunyuan-Video-7B:专为短视频理解而生的多模态模型在微信视频号、TikTok 等平台上,每天有数亿条用户生成的短视频被上传。这些视频内容多样、节奏快、信息密度高,往往融合了画面、语音、音效、文字甚至情绪表达。如何让AI真正“理解”这些视频,而不仅仅是...多模态模型# ARC-Hunyuan-Video-7B# 多模态模型# 腾讯ARC实验室5个月前04210
清华团队提出3D场景生成新框架ScenePainter:解决3D生成中的语义漂移难题从一张街景照片出发,AI能否自动“走”过整条街道,生成沿途连续、风格统一的3D视图?这不仅是虚拟现实、自动驾驶仿真的基础需求,也是生成式AI在空间理解上的重要挑战。 然而,当前主流方法在生成长序列3D...3D模型# 3D生成# ScenePainter5个月前02310
新型歌曲生成模型JAM:让歌词精准变成完整歌曲你有没有想过,输入一段歌词,再标上每个词该在什么时候唱,就能自动生成一首旋律自然、节奏准确、风格统一的完整歌曲? 这不是未来设想,而是已经实现的技术突破。 新加坡科技设计大学(SUTD)与 Lambd...语音模型# JAM# 歌曲生成模型5个月前01160
智谱AI正式推出 GLM 系列最新旗舰大模型GLM-4.5 系列:统一推理、编码与代理的全能旗舰模型智谱AI正式推出 GLM-4.5 与 GLM-4.5-Air —— GLM 系列最新旗舰大模型。这两款模型专为代理(Agent)导向应用设计,首次在单一架构中深度融合了复杂推理、高效编码与多工具协同能...大语言模型# GLM-4.5# GLM-4.5-Air# 智谱AI5个月前02360
阿里 WAN 项目组正式推出 Wan2.2:MoE 架构 + 高压缩设计,开源视频生成再进化阿里 WAN 项目组正式推出 Wan2.2,这是对 WAN 系列视频生成模型的一次重大升级。本次发布涵盖多个模型变体,全面支持文本到视频(T2V)、图像到视频(I2V)以及混合输入(TI2V)任务,在...视频模型# Wan2.2# 视频生成模型5个月前09740
上海交通大学发布SmallThinker 系列模型:专为设备端部署设计的原生混合专家(MoE)语言模型由上海交通大学 IPADS 实验室、人工智能学院与 Zenergize AI 联合研发的 SmallThinker 系列模型,是一组专为设备端部署设计的原生混合专家(MoE)语言模型。其核心目标是在资...大语言模型# SmallThinker# 上海交通大学5个月前02810
中国科学院发布“磐石”操作系统与 S1-Base 科学大模型:开启“AI for Science”新范式在AI加速推动科学研究变革的背景下,中国科学院正式推出 “磐石”(ScienceOne) —— 一个面向前沿科学发现与技术创新的“AI+科学”操作系统。作为其核心引擎,磐石科学基础大模型(S1-Bas...大语言模型# 中国科学院# 磐石科学基础大模型5个月前02730
Anzhc 开源系列 YOLO 模型:专注细粒度图像分割与分类任务在图像检测与分割领域,高质量的专用模型往往能显著提升下游任务的表现。开发者 Anzhc 基于自建标注数据集,训练并开源了一系列面向特定视觉任务的 YOLO 模型,涵盖面部、眼部、头部、胸部等细粒度目标...图像模型# YOLO 模型# 图像分割5个月前03530
![黑森林实验室联合 KREA AI 发布 FLUX.1 Krea [dev]: 实现更真实、更自然的图像生成](https://pic.sd114.wiki/wp-content/uploads/2025/08/1753986665-1753986665-FLUX-Krea-2.webp~tplv-o4t1hxlaqv-image.image)