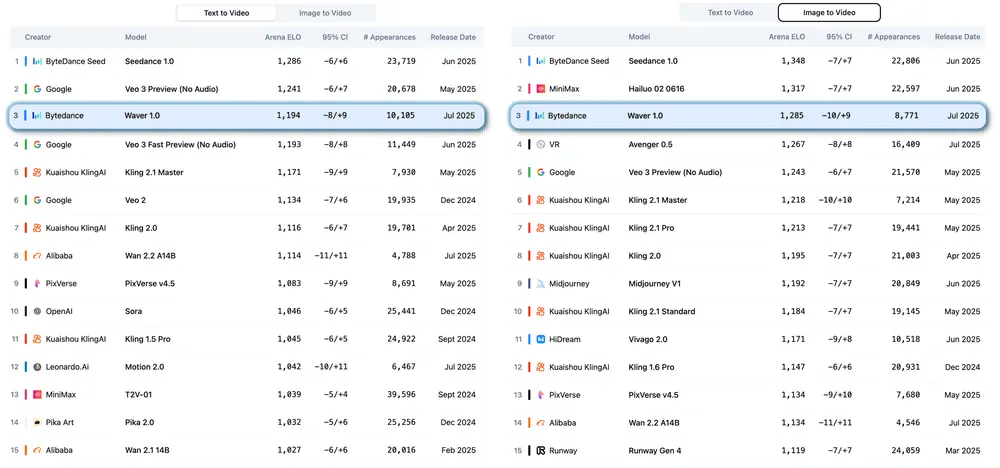
字节跳动 Waver 项目组推出一体化视频生成模型Waver 1.0:同时支持文生图、图生视频及文生图生成字节跳动 Waver 项目组近期正式推出 Waver 1.0 一体化视频生成模型,凭借多模态生成能力、高分辨率支持及卓越的运动建模效果,在视频生成领域实现重要突破,为工业级视频创作需求提供了全新解决方...视频模型# Waver 1.0# 字节跳动# 视频生成5个月前06080
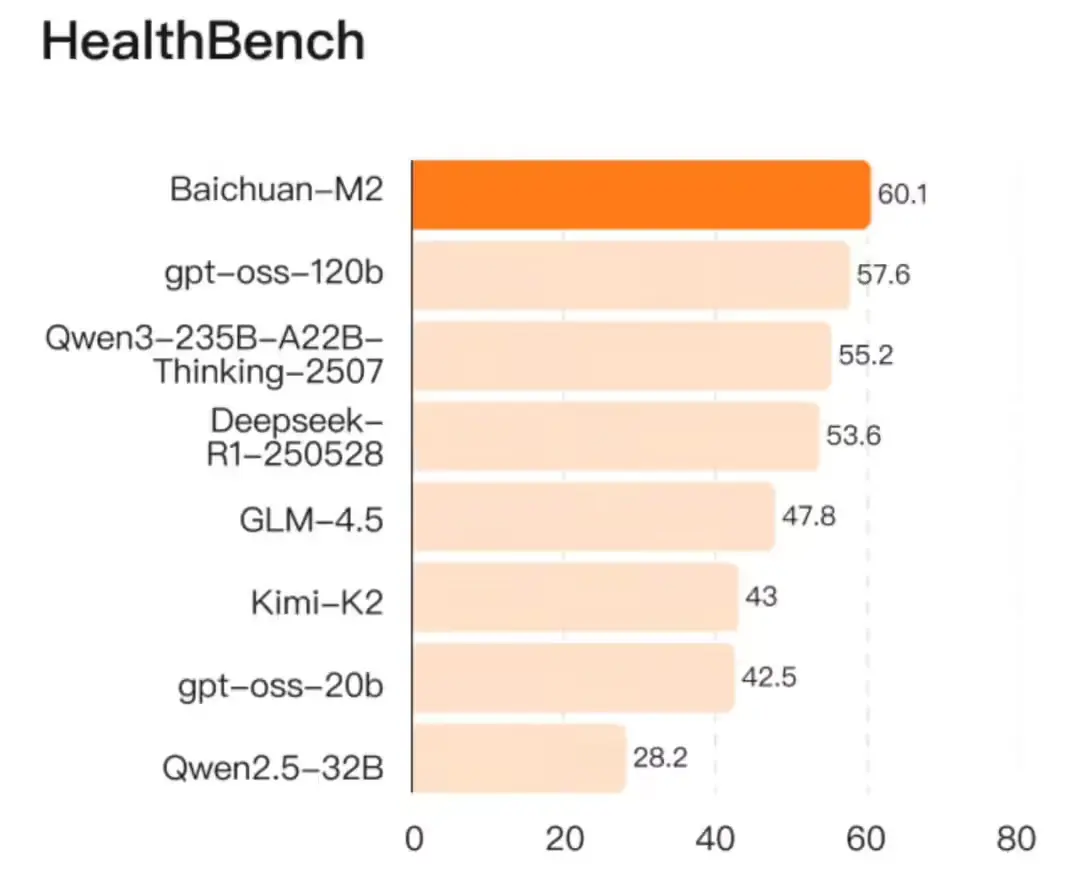
百川智能发布 Baichuan-M2:小模型,大医疗,单卡可部署的开源医疗大模型8 月 6 日,OpenAI 开源两款大模型,主打“低成本部署”与“医疗能力突破”。仅仅五天后,百川智能推出 Baichuan-M2 ——一款在更小参数规模下实现医疗能力反超的开源模型。 模型:htt...大语言模型# Baichuan-M2# 医疗大模型# 百川智能6个月前06040
Cohere 推出了 Command A:高性能、低计算需求的大语言模型,为企业量身定制今天,Cohere 推出了 Command A,一款专为企业设计的新型先进生成模型,旨在满足企业对快速、安全和高质量 AI 的高要求。Command A 在性能、效率和企业级功能上表现出色,是市场上最...大语言模型# Cohere# Command A# 企业11个月前05900
黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]截至今日,所有高性能的生成式图像编辑模型均为专有工具。今天,这一局面发生了改变。 黑森林实验室(Black Forest Labs)发布了 FLUX.1 Kontext [dev],这是 FLUX.1...图像模型# FLUX.1 Kontext [dev]# 图像编辑模型# 黑森林实验室7个月前05890
新型CLIP专家混合模型CLIP-MoE:可以无缝替换CLIP,以即插即用的方式,而无需在下游框架中进一步适应香港中文大学、上海人工智能实验室和舒尔茨大学的研究人员推出新型CLIP模型CLIP-MoE,它是为了增强现有的多模态智能模型CLIP而设计的。CLIP-MoE可以无缝替换CLIP,以即插即用的方式,而...多模态模型# CLIP-MoE# 多模态智能模型12个月前05860
智谱AI推出图像生成模型 CogView3 以及 CogView-3Plus清华和智谱 AI的研究团队开源了图像生成模型 CogView3 以及CogView-3-Plus ,CogView3 是一个基于级联扩散的文本生成图像系统,采用了接力扩散(relay diffusio...图像模型# CogView-3Plus# CogView3# 图像生成12个月前05860
基于扩散的肖像动画生成新方法JoyVASA:用于生成音频驱动的面部动画,包括面部动态和头部运动音频驱动的肖像动画在基于扩散模型的推动下取得了显著进展,提高了视频质量和唇同步的准确性。然而,这些模型的复杂性增加导致了训练和推理的低效,以及对视频长度和帧间连续性的限制。为了解决这些问题,京东健康国...图像模型# JoyVASA# 肖像动画12个月前05840
英伟达推出多模态大语言模型Describe Anything 3B:为图像和视频局部描述量身定制的多模态 AI 模型英伟达、加州大学伯克利分校和加州大学旧金山分校的研究人员推出了 Describe Anything 3B (DAM-3B),这是一个专门用于生成细粒度图像和视频字幕的多模态大语言模型(LLM)。DAM...多模态模型# Describe Anything 3B# 多模态大语言模型# 英伟达9个月前05830
Nunchaku发布量化版Qwen-Image模型,支持高效图像生成Nunchaku 官方宣布,其基于Qwen-Image的四个量化版本模型已正式上线 Hugging Face和魔塔!这些模型专为高效文本到图像生成而优化,尤其在复杂文本渲染方面表现突出。 Huggin...图像模型# Nunchaku# Qwen-Image6个月前05760
KittenML推出一个仅 25MB 的开源文本转语音模型Kitten TTSKittenML推出一款名为 Kitten TTS 的新型文本转语音(TTS)模型,它以极小体积、无需 GPU 和高质量语音合成能力为特点,专为边缘设备和轻量级部署场景设计。 GitHub:https...语音模型# Kitten TTS# 文本转语音模型6个月前05760
对话也能生成语音?复旦大学开源 MOSS-TTSD 实现高质量对话语音合成复旦大学 OpenMOSS 团队正式发布了全新语音生成模型 MOSS-TTSD(Text to Spoken Dialogue),这是目前首个能够直接从对话文本生成自然、富有表现力对话语音的大规模模型...语音模型# MOSS-TTSD# 复旦大学7个月前05750
OpenAI视频模型Sora技术报告:构建虚拟世界的模拟器Sora我们专注于研究如何在大规模视频数据上训练生成模型。具体来说,我们针对不同时长、分辨率和宽高比的视频及图像,联合训练了基于文本条件的扩散模型。为了实现这一目标,我们运用了一种能够处理视频和图像潜在编码时...视频模型# OpenAI# Sora# 技术报告12个月前05720

![黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]](https://pic.sd114.wiki/wp-content/uploads/2025/06/1750964036-1750964036-FLUX.1-Kontext-2.webp~tplv-o4t1hxlaqv-image.image)