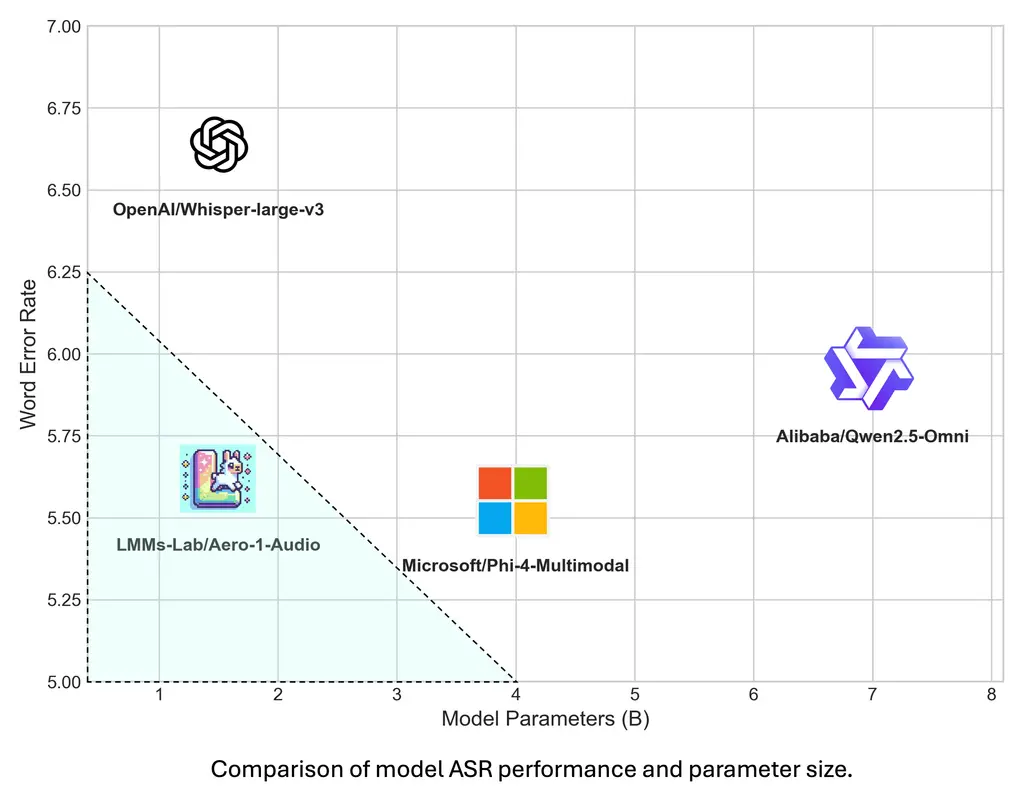
LMMs-Lab发布轻量高效音频模型Aero-1-Audio:擅长长语音ASR与多模态任务LMMs-Lab 推出了一款紧凑型音频模型 Aero-1-Audio,专为多种音频任务设计,包括语音识别(ASR)、音频理解和音频指令跟随。作为 Aero-1 系列的第一代产品,Aero-1-Audi...语音模型# Aero-1-Audio# LMMs-Lab# 语音识别9个月前05700
新型文生图模型YaART:利用人类反馈的强化学习与人类偏好进行对齐来自俄罗斯Yandex、斯科尔科沃科学技术学院、莫斯科国立大学和高等经济学院的研究团队推出新型的、适用于生产环境的文本到图像级联扩散模型YaART(Yet Another Art Rendering ...图像模型# YaART# 文生图模型12个月前05690
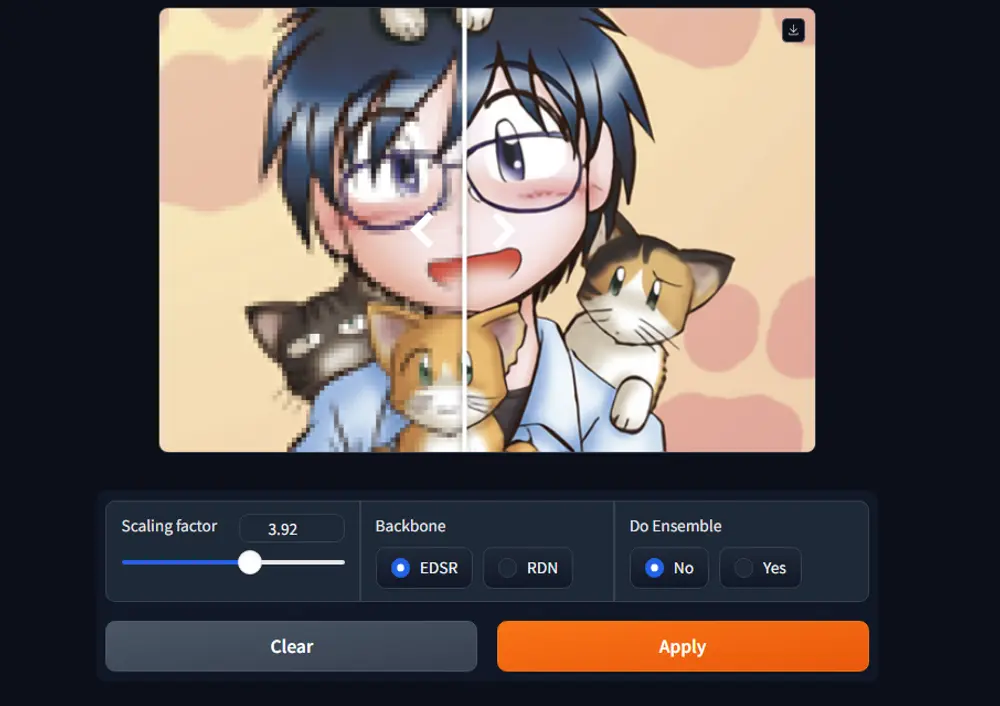
基于神经热场的无混叠任意尺度超分辨率(ASR)方法Thera:实现高质量的图像超分辨率重建苏黎世联邦理工学院和苏黎世大学的研究人员推出一种基于神经热场(Neural Heat Fields)的无混叠任意尺度超分辨率(ASR)方法Thera,该方通过结合神经场(Neural Fields)和...图像模型# Thera# 图像放大# 图像高清11个月前05680
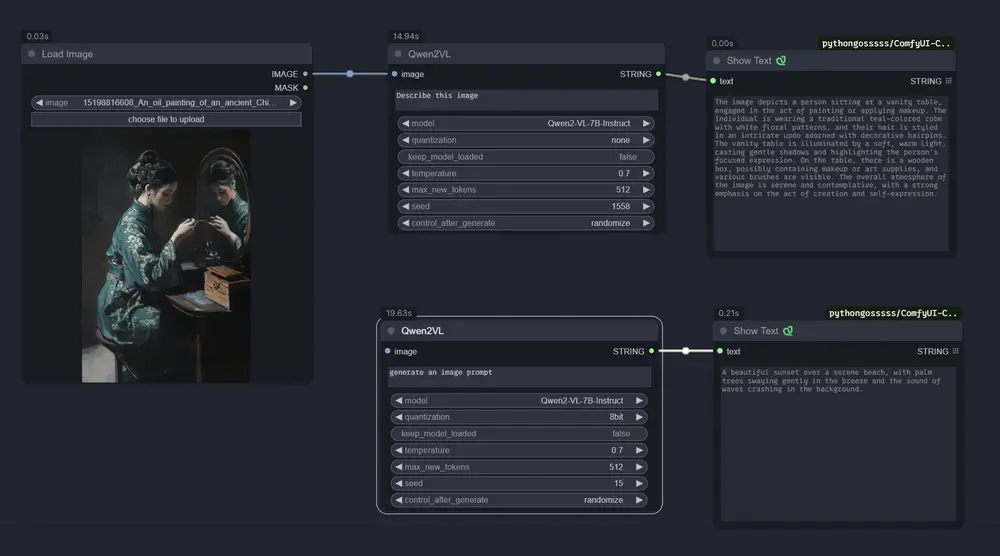
多模态大语言模型Qwen2-VL-7B-Captioner-Relaxed:经过指令调整的Qwen2-VL-7B-Instruct版本Qwen2-VL-7B-Captioner-Relaxed 是 Qwen2-VL-7B-Instruct 的一个经过指令调整的版本,它是一个多模态大语言模型。这个经过精细调整的版本是基于一个为文生图模...多模态模型# Qwen2-VL-7B-Captioner-Relaxed# 多模态大语言模型12个月前05630
MagicTailor框架:让用户对生成的图像中的特定视觉元素进行精确控制近年来,文本到图像(T2I)扩散模型取得了显著进展,能够从简单的文本提示中生成高质量的图像。然而,这些模型在精确控制特定视觉概念生成方面仍然面临挑战。现有的方法可以通过参考图像学习复制给定的概念,但缺...图像模型# MagicTailor# 图像定制12个月前05600
大型多模态模型LLaVA-Video:专门设计来处理视频指令并进行视频内容理解字节跳动、南洋理工大学S-Lab和北京邮电大学的研究人员推出大型多模态模型LLaVA-Video,专门设计来处理视频指令并进行视频内容理解。这个模型特别擅长于解析和生成与视频内容相关的语言描述,比如详...多模态模型# LLaVA-Video# 多模态模型12个月前05600
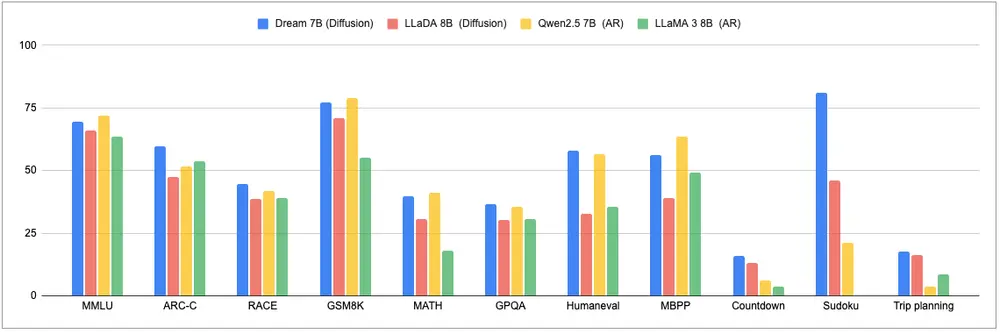
香港大学与华为合作发布扩散大语言模型 Dream 7B香港大学与华为诺亚方舟实验室携手,正式发布了迄今为止最强大的开放扩散(Diffusion)大语言模型——Dream 7B。这一模型不仅在性能上大幅超越现有的扩散语言模型,还在通用能力、数学能力和编码能...大语言模型# Dream 7B# 华为诺亚方舟实验室# 扩散大语言模型10个月前05590
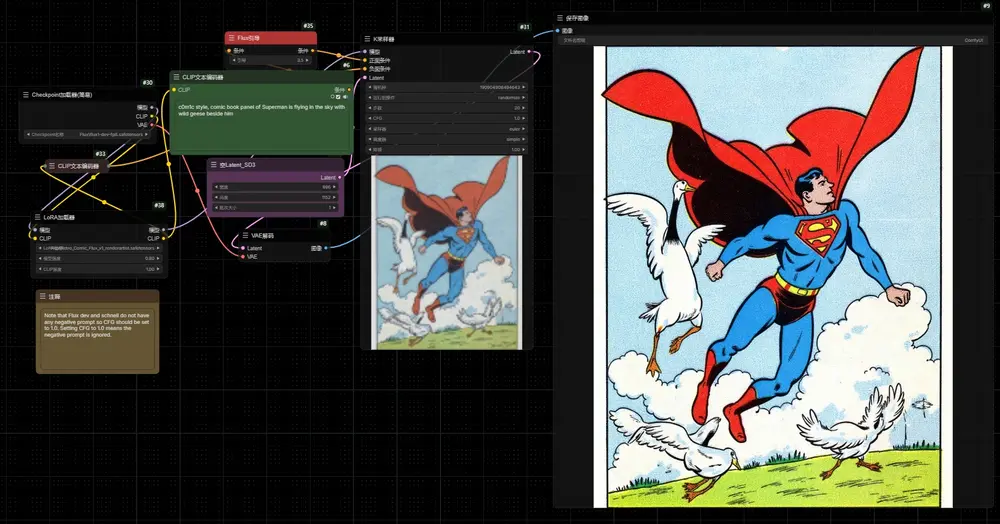
Retro Comic Flux:基于FLUX.1-dev的美式复古漫画风格LoRARetro Comic Flux是一款基于FLUX.1-dev的美式复古漫画风格LoRA模型,主要擅长处理人物形象,当你描述角色和背景场景时,它效果最好。 模型下载(Civitai):https...Flux衍生# Lora# Retro Comic Flux# 复古漫画12个月前05570
时间延时视频生成模型MagicTime:学习现实世界中的物理知识,并能够生成展示这些知识的时间延时视频来自北京大学深圳研究生院、罗彻斯特大学、新加坡国立大学、广东工业大学和加州大学圣克鲁斯分校的研究人员推出新型时间延时视频生成模型MagicTime,这个模型的目标是学习现实世界中的物理知识,并能够生成...视频模型# MagicTime# 时间延时视频生成模型12个月前05570
Meta推出图像和视频分割模型SAM 2:图像和视频中的可提示视觉分割Meta在去年推出了图像分割模型Segment Anything,今年它们又推出了升级版Segment Anything Model 2 (SAM 2),这是一种用于图像和视频中可提示视觉分割的基础模...图像模型# Meta# SAM 2# 分割模型12个月前05560
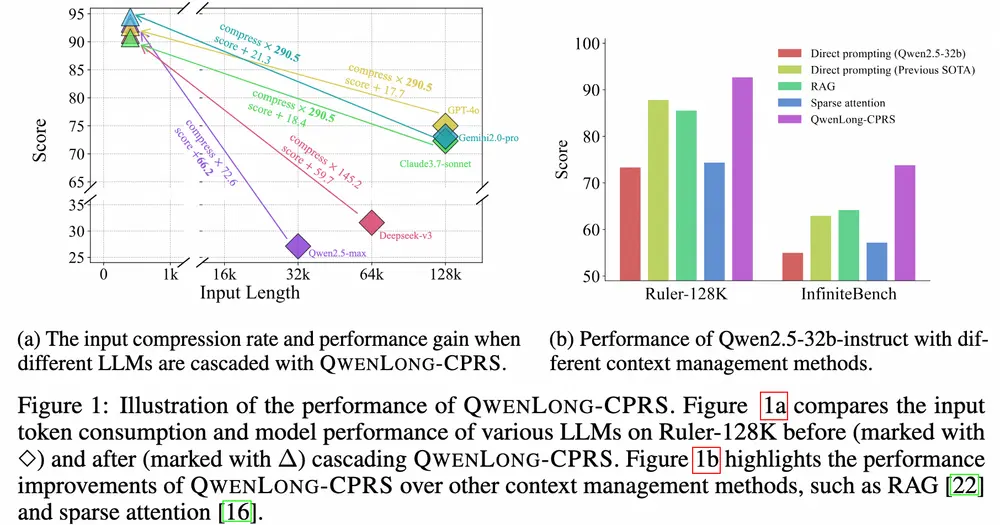
阿里推出高效的长上下文压缩框架QwenLong-CPRS在大语言模型(LLM)处理长文本时,两个核心问题始终存在:计算开销高 和 中间信息丢失严重。为了解决这些问题,阿里通义实验室 Qwen-Doc 团队推出了一个全新上下文压缩框架 —— QwenLong...大语言模型# QwenLong-CPRS# QwenLong-CPRS-7B8个月前05550
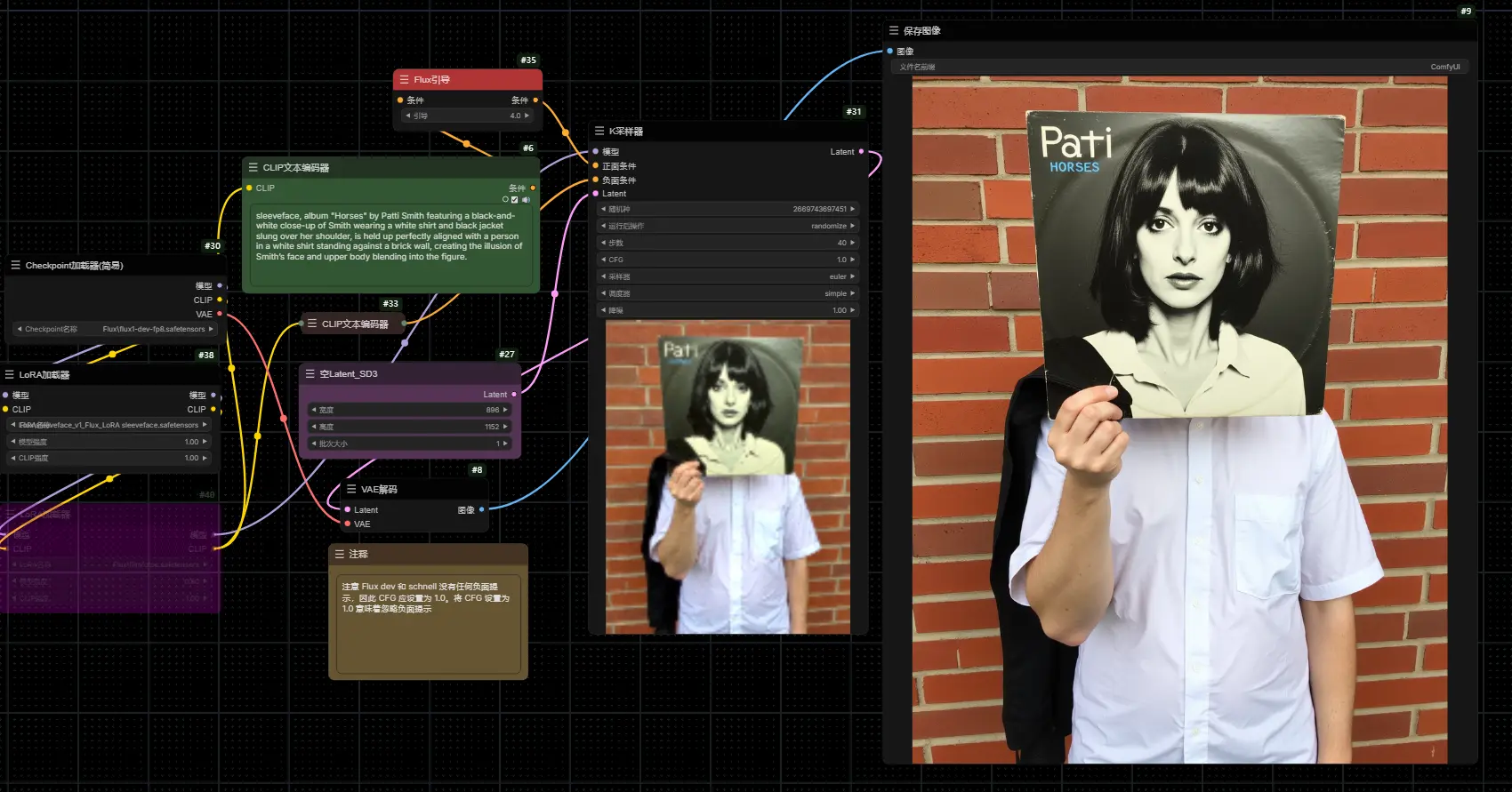
Sleeveface :基于 FLUX.1-dev 的风格LoRA,专门设计用来重现2000年代流行的“Sleeveface”风格Sleeveface 是一款基于 FLUX.1-dev 的概念LoRA,专门设计用来重现2000年代流行的“Sleeveface”风格的图像。这种风格的图像通常展示一个人手持一张专辑封面,巧妙地将其与...Flux衍生# FLUX.1-dev# Sleeveface12个月前05480