Meta推出基于视频训练的“世界模型”V-JEPA 2:AI“世界模型”迈出理解物理世界的重要一步Meta 发布了其最新 AI 研究成果 —— V-JEPA 2,一个基于视频训练的“世界模型”,旨在帮助 AI 更好地理解现实世界的物理规律,并用于机器人控制、任务规划等复杂场景。 项目主页:http...多模态模型# Meta# V-JEPA 2# 世界模型8个月前02130
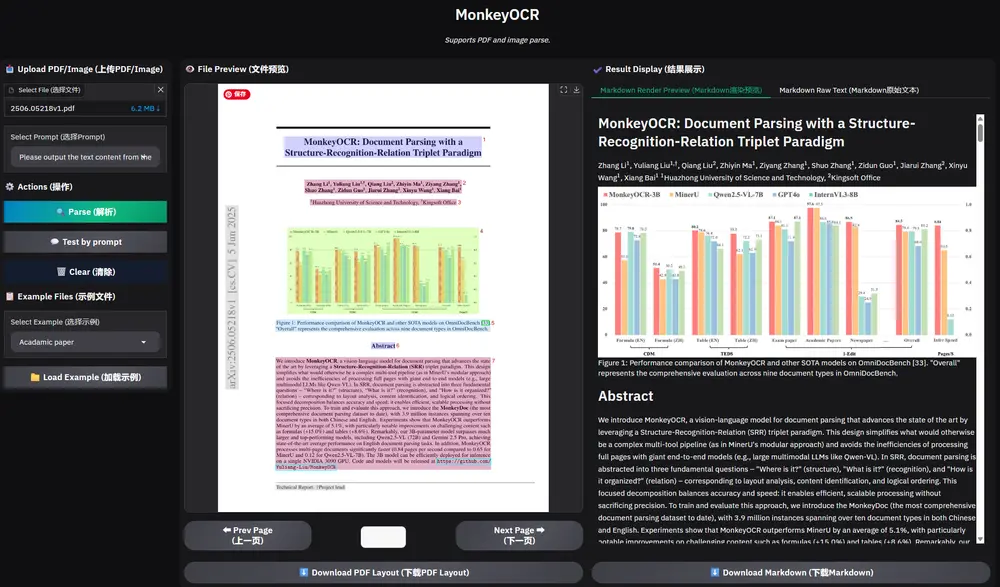
华科大联合金山办公推出文档解析新模型MonkeyOCR近日,华中科技大学与金山办公联合研究团队发布了一款全新的文档解析模型 —— MonkeyOCR。该模型通过引入“结构-识别-关系”(Structure-Recognition-Relation, SR...多模态模型# MonkeyOCR# 文档解析8个月前02380
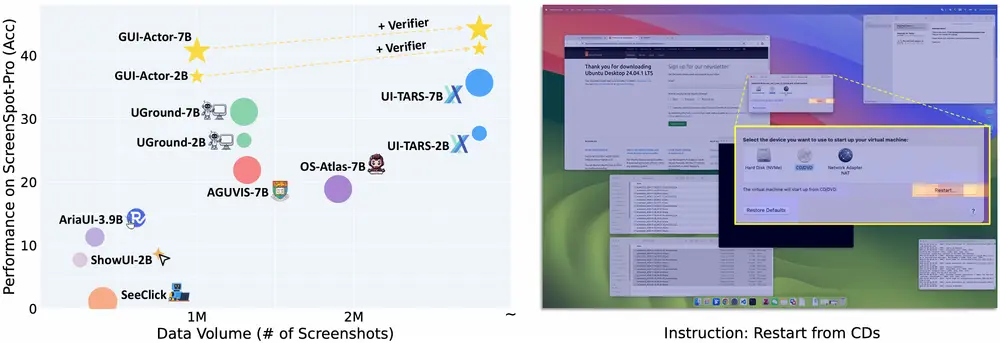
微软提出 GUI-Actor:基于视觉语言模型的无坐标 GUI 定位新范式在构建基于视觉语言模型(VLM)的 GUI 代理系统中,一个关键挑战是如何准确理解屏幕上的视觉内容并定位应执行操作的区域。传统方法通常将此问题建模为“文本到坐标的生成”任务,即通过语言描述预测具体像素...多模态模型# GUI-Actor# 微软8个月前03330
英伟达推出面向文档理解的小而强视觉-语言模型 Llama Nemotron Nano VL英伟达正式发布了 Llama Nemotron Nano VL —— 一款专为高效处理复杂文档设计的轻量级视觉-语言模型(VLM)。该模型基于 Llama 3.1 架构构建,在保持高性能的同时兼顾推理...多模态模型# Llama Nemotron Nano VL# 英伟达8个月前02760
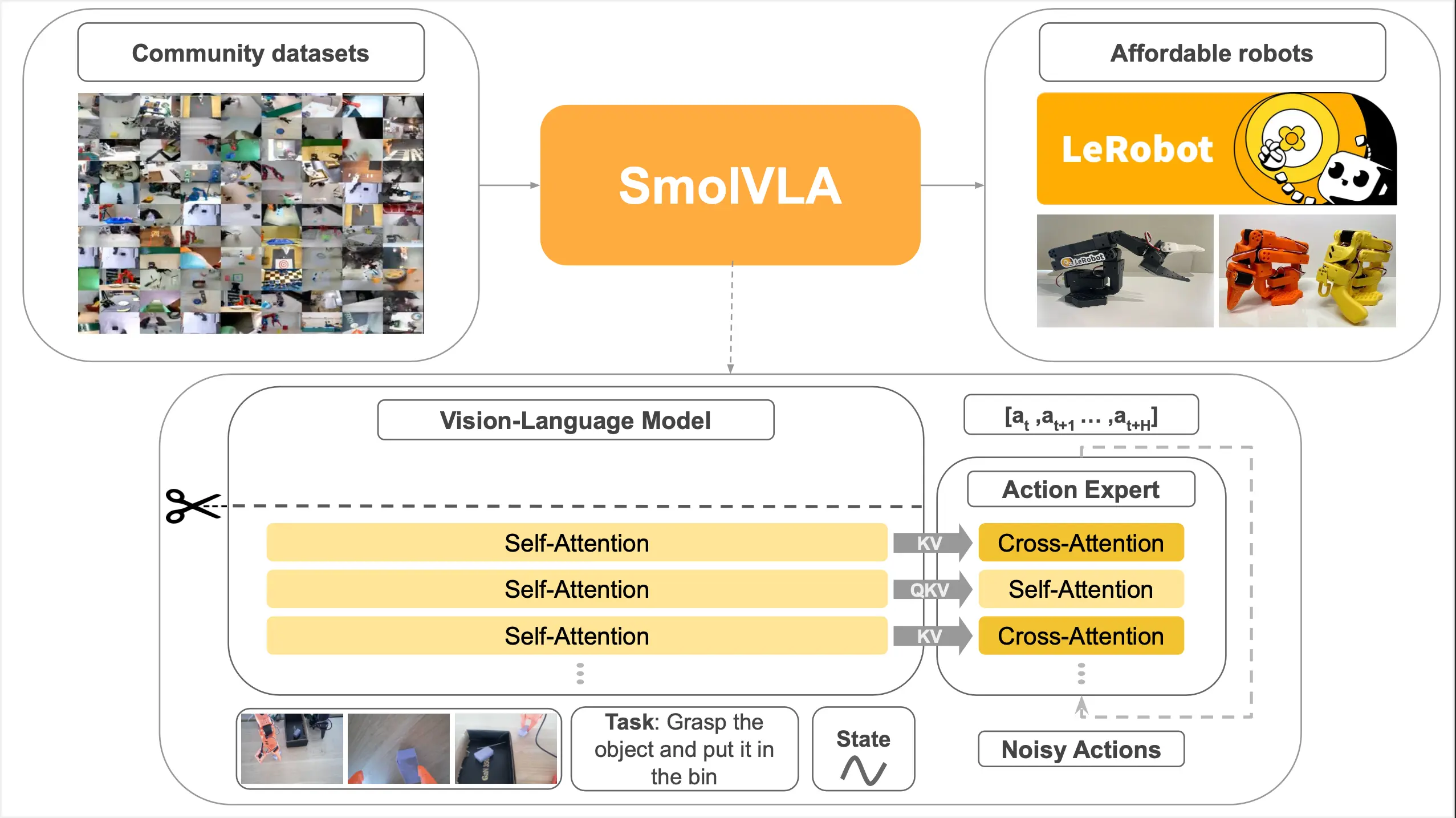
Hugging Face 推出轻量级机器人AI模型SmolVLA:可在MacBook运行随着AI与机器人技术的融合不断深入,构建个人机器人项目正变得前所未有的容易。近日,知名AI平台 Hugging Face 正式发布了其最新研发的机器人AI模型——SmolVLA,这一模型不仅小巧高效...多模态模型# Hugging Face# SmolVLA8个月前03550
SignGemma:谷歌推出全球最强手语翻译模型,为听障人群打开沟通新通道谷歌近日宣布推出全新 AI 模型 SignGemma,作为 Gemma 家族的新成员,它专注于将手语(尤其是美式手语 ASL)翻译成英文文本或语音输出,是目前最强大的开源手语理解模型之一。 SignG...多模态模型# SignGemma# 手语翻译模型8个月前01620
像素空间推理视觉语言模型Pixel Reasoner:引入像素空间推理的概念,显著提升了视觉语言模型在视觉密集型任务中的表现中国科学技术大学、香港科技大学和滑铁卢大学的研究人员推出基于 Qwen2 的开源视觉语言模型Pixel Reasoner,它通过引入像素空间推理(pixel-space reasoning)的概念,显...多模态模型# Pixel Reasoner# 视觉语言模型8个月前02750
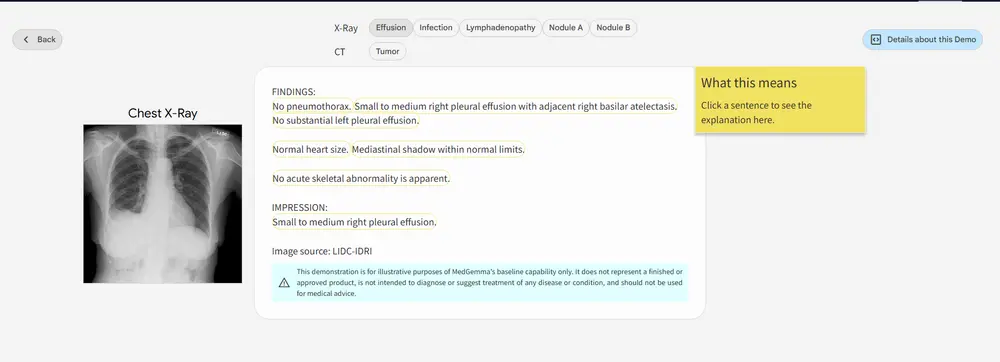
谷歌发布医学多模态开源模型MedGemma:支持图像与文本理解,支持X光CT分析谷歌近日推出了一款面向医疗领域的开源模型系列 —— MedGemma,该模型基于 Gemma 3 构建,在医学图像识别与文本理解方面表现出色,标志着医疗 AI 在开源方向上的重要进展。 MedGemm...多模态模型# MedGemma# 医学多模态开源模型# 谷歌8个月前02020
蚂蚁集团开源全新统一多模态大模型 Ming-Lite-Omni:支持图像、文本、音频、视频近日,蚂蚁集团旗下的 百灵大模型(Ling)团队 正式宣布开源其最新推出的统一多模态大模型 —— Ming-Lite-Omni。这是一款基于 Ling 系列轻量模型构建的 MoE 架构全模态 AI 模...多模态模型# Ming-Lite-Omni# 多模态大模型# 蚂蚁集团8个月前03040
MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune :使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune ,使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务。该系统通过整合三个互补组件——样本级数据格式化(Sample-Le...多模态模型# MiniMax# V-Triune# 视觉语言模型8个月前04790
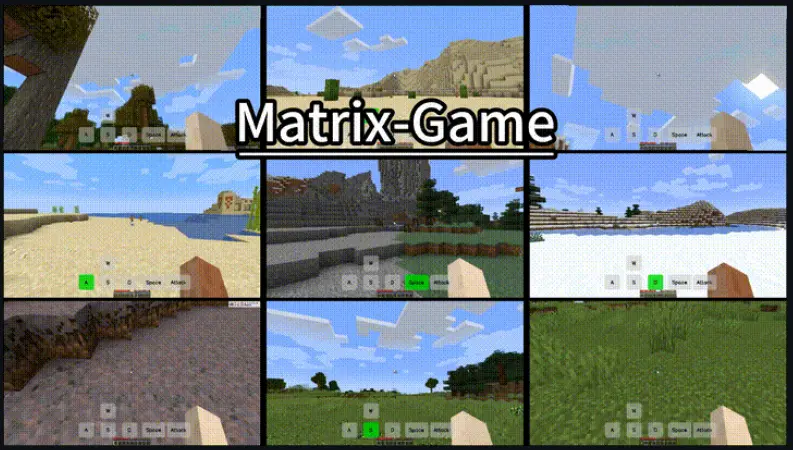
天工AI推出Matrix-Game:首个支持可控交互式游戏世界生成的170亿参数基础模型昆仑万维旗下天工AI团队正式发布了其最新研究成果——Matrix-Game,这是一个面向游戏世界的可交互视频生成基础模型,专为 Minecraft 及类似开放世界设计,具备精确控制角色动作、视角变换和...多模态模型# Matrix-Game# 游戏世界生成8个月前03020
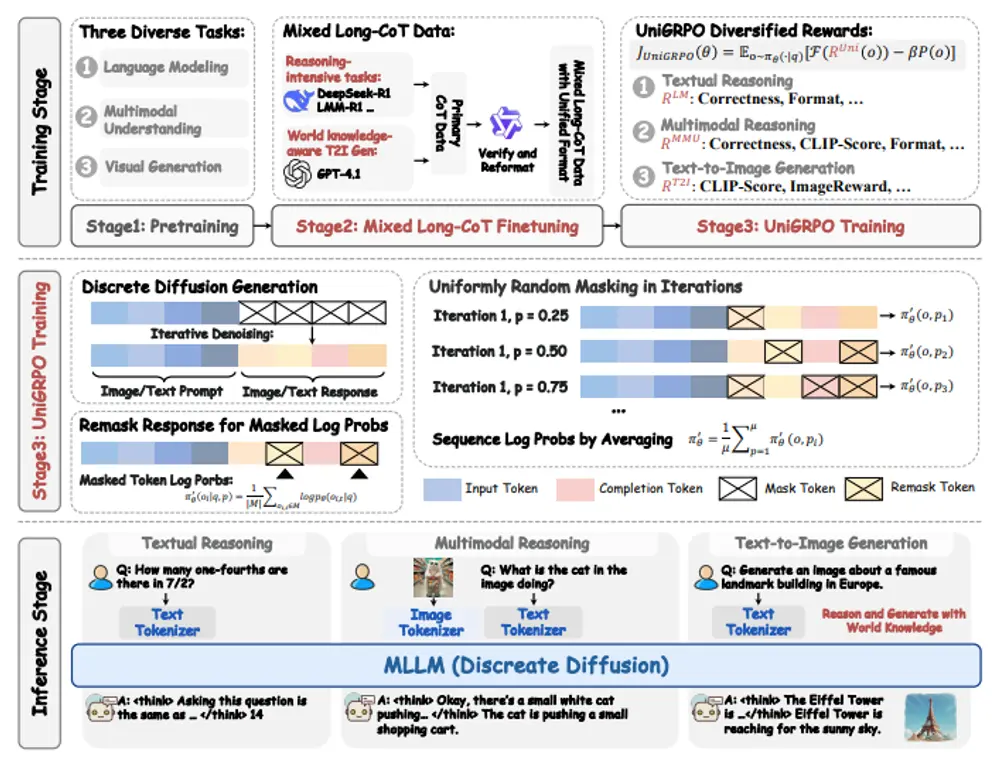
新型多模态扩散基础模型MMaDA:通过统一的扩散架构和训练策略,在多种领域(如文本推理、多模态理解和文本到图像生成)中实现卓越性能普林斯顿大学、北京大学、清华大学和字节跳动的研究人员推出新型多模态扩散基础模型MMaDA系列,该模型通过统一的扩散架构和训练策略,在多种领域(如文本推理、多模态理解和文本到图像生成)中实现卓越性能。 ...多模态模型# MMaDA# 多模态扩散基础模型8个月前04250