让视频"无中生有"的AI魔术师!PISCO:基于稀疏控制的精确视频实例插入技术想象一下,你拍了一段空无一人的街道视频,现在想把一只奔跑的猫放进画面里——不仅要让它看起来真实,还要让它和周围环境产生互动:地上要有影子,经过水坑要有倒影,被路灯照到要反光。更神奇的是,你只需要告诉A...视频模型# PISCO# 视频编辑2个月前0190
复杂运动、多模态参考、双声道音频!字节跳动正式发布Seedance 2.0:统一多模态架构, 支持导演级编辑的工业级音视频生成字节跳动正式推出新一代视频创作模型 Seedance 2.0。作为迭代升级后的重磅版本,它采用全新统一的多模态音视频联合生成架构,全面支持文本、图片、音频、视频四种模态输入,集成了当前行业内覆盖面最广...早报视频模型# Seedance 2.0# 字节跳动2个月前0160
Soul AI Lab推出SoulX-FlashTalk :140 亿参数模型实现 0.87 秒启动、32 FPS 实时数字人直播当前 AI 数字人技术面临一个根本矛盾:高保真生成与实时性难以兼得。顶尖模型虽能生成逼真口型与表情,但因依赖多步迭代去噪,生成一秒钟视频常需数秒甚至更久,无法用于视频通话、直播带货等实时交互场景。更严...视频模型# Soul AI Lab# SoulX-FlashTalk# 数字人2个月前0310
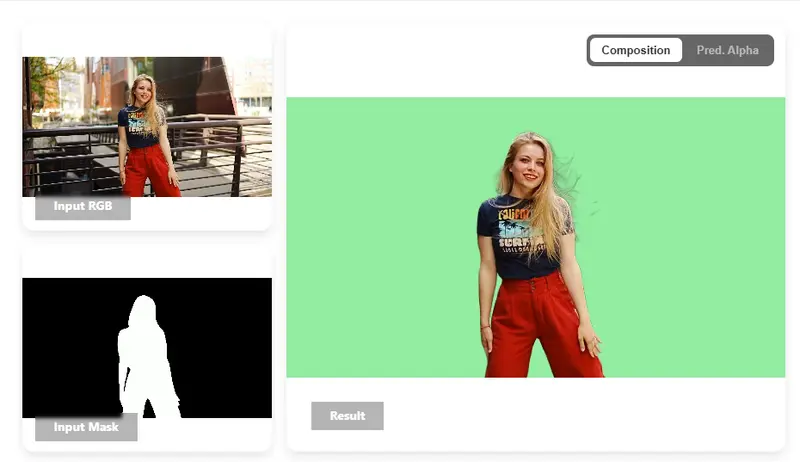
VideoMaMa:基于扩散模型的视频抠图新SOTA,粗糙掩码一键生成高精度Alpha遮罩高丽大学、Adobe Research 与 KAIST AI 联合提出 VideoMaMa(Video Mask-to-Matte Model),一种基于 Stable Video Diffusion...视频模型# VideoMaMa# 视频抠图2个月前0210
InteractAvatar:文本驱动的可控说话化身框架,实现高保真场景化人-物交互清华大学联合腾讯混元项目组研发的InteractAvatar,是一款创新的双流DiT(扩散变换器)框架,首次让说话虚拟化身突破简单手势局限,实现基于静态场景的文本驱动可控人-物交互。该模型能从参考图像...视频模型# InteractAvatar# 数字人2个月前0570
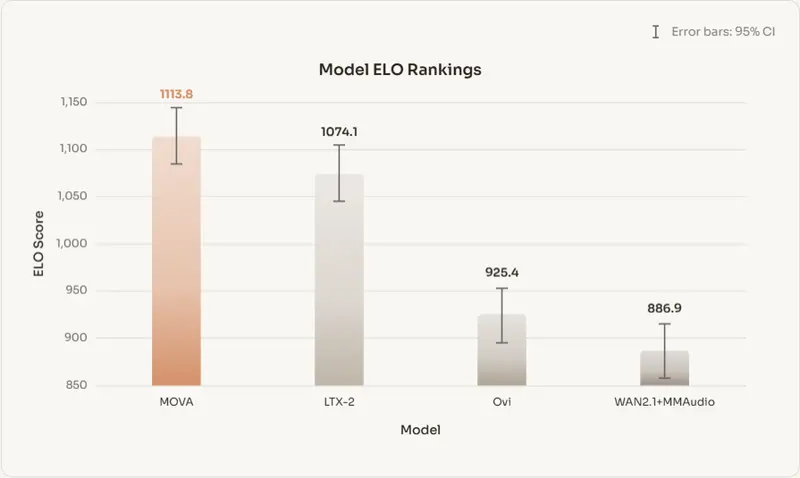
模思智能推出 MOVA:开源同步音视频生成基座模型,打破“无声视频”困局模思智能正式开源 MOVA(MOSS Video and Audio)——一款专注于原生同步生成视频与音频的基座模型。针对当前主流系统(如 Sora 2、Veo 3)普遍采用的“先画后音”级联流程,M...视频模型# MOVA# 模思智能2个月前0190
UniVideo:滑铁卢大学与快手推出统一视频生成与编辑模型,支持理解、生成、编辑一体化长久以来,视频 AI 能力被割裂为多个独立任务: 理解:靠视觉语言模型(如 Qwen-VL) 生成:依赖扩散模型(如 Sora、HunyuanVideo) 编辑:需专门的编辑网络或掩码引导 这种碎片化...视频模型# UniVideo# 视频生成# 视频编辑3个月前0240
Lightricks发布LTX-2:首个基于 DiT 的开源音视频基础模型Lightricks发布了首个基于 Diffusion Transformer(DiT) 架构的开源音视频联合生成模型LTX-2。它在一个统一框架中集成了现代视频生成的核心能力:同步的音频与视频输出...视频模型# Lightricks# LTX-2# 音视频模型3个月前0400
Stable Video Infinity(SVI)发布 2.0 Pro:基于错误回收机制的无限长视频生成模型洛桑联邦理工学院(EPFL)的研究团队推出 Stable Video Infinity(SVI) ——一款能够生成任意长度视频的人工智能模型。它通过一项名为 “错误回收微调(Error-Recycli...视频模型# Stable Video Infinity3个月前01430
StoryMem:基于Wan2.2的新框架,用“视觉记忆”生成连贯的多镜头长视频生成一段包含多个镜头、角色一致、场景连贯、时长达一分钟的叙事视频,是当前视频生成模型的重大挑战。主流方法要么局限于单镜头,要么在跨镜头切换时出现角色崩坏、场景断裂等问题。 由南洋理工大学与字节跳动联合...视频模型# StoryMem# Wan2.23个月前0830
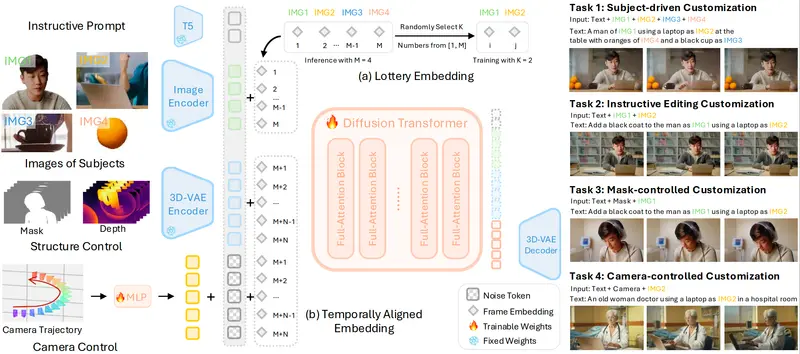
OmniVCus:用多模态控制信号实现前馈式主题驱动视频定制在视频生成领域,一个长期挑战是:如何让用户通过简单指令(如文本、草图或相机轨迹),灵活定制视频中一个或多个主体的外观、动作与空间关系? 由约翰·霍普金斯大学、Adobe 研究院、香港大学、香港中文大学...视频模型# OmniVCus# 视频3个月前0290
TurboDiffusion:视频扩散模型提速 100–200 倍,质量几乎无损视频扩散模型虽能生成高质量内容,但其缓慢的推理速度长期制约实际应用。近日,清华大学、生数科技与加州大学伯克利分校联合提出 TurboDiffusion——一个端到端视频生成加速框架,在单张 RTX 5...视频模型# TurboDiffusion# Wan2.23个月前0330