新型歌曲生成模型JAM:让歌词精准变成完整歌曲你有没有想过,输入一段歌词,再标上每个词该在什么时候唱,就能自动生成一首旋律自然、节奏准确、风格统一的完整歌曲? 这不是未来设想,而是已经实现的技术突破。 新加坡科技设计大学(SUTD)与 Lambd...语音模型# JAM# 歌曲生成模型6个月前01250
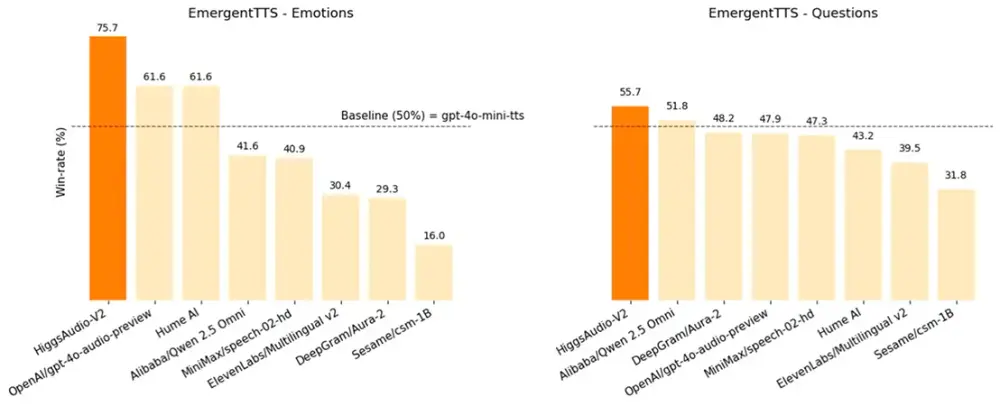
Boson AI 发布 Higgs Audio V2:首个开源的多说话者情感语音生成模型Boson AI 正式推出 Higgs Audio Generation 版本2(Higgs Audio V2),这是Boson AI在音频生成领域的一次重要突破。该模型具备强大的多说话者对话生成能力...语音模型# Boson AI# Higgs Audio V26个月前02430
字节跳动发布 Seed LiveInterpret 2.0:首个中英同传延迟与准确率接近人类水平的端到端语音翻译系统在跨语言实时沟通的长期挑战中,机器能否真正替代人类同声传译?字节跳动 Seed 团队给出了迄今为止最接近“是”的答案。 今日,字节跳动正式发布 Seed LiveInterpret 2.0 —— 一款...语音模型# Seed LiveInterpret 2.0# 同声传译模型# 字节跳动6个月前03040
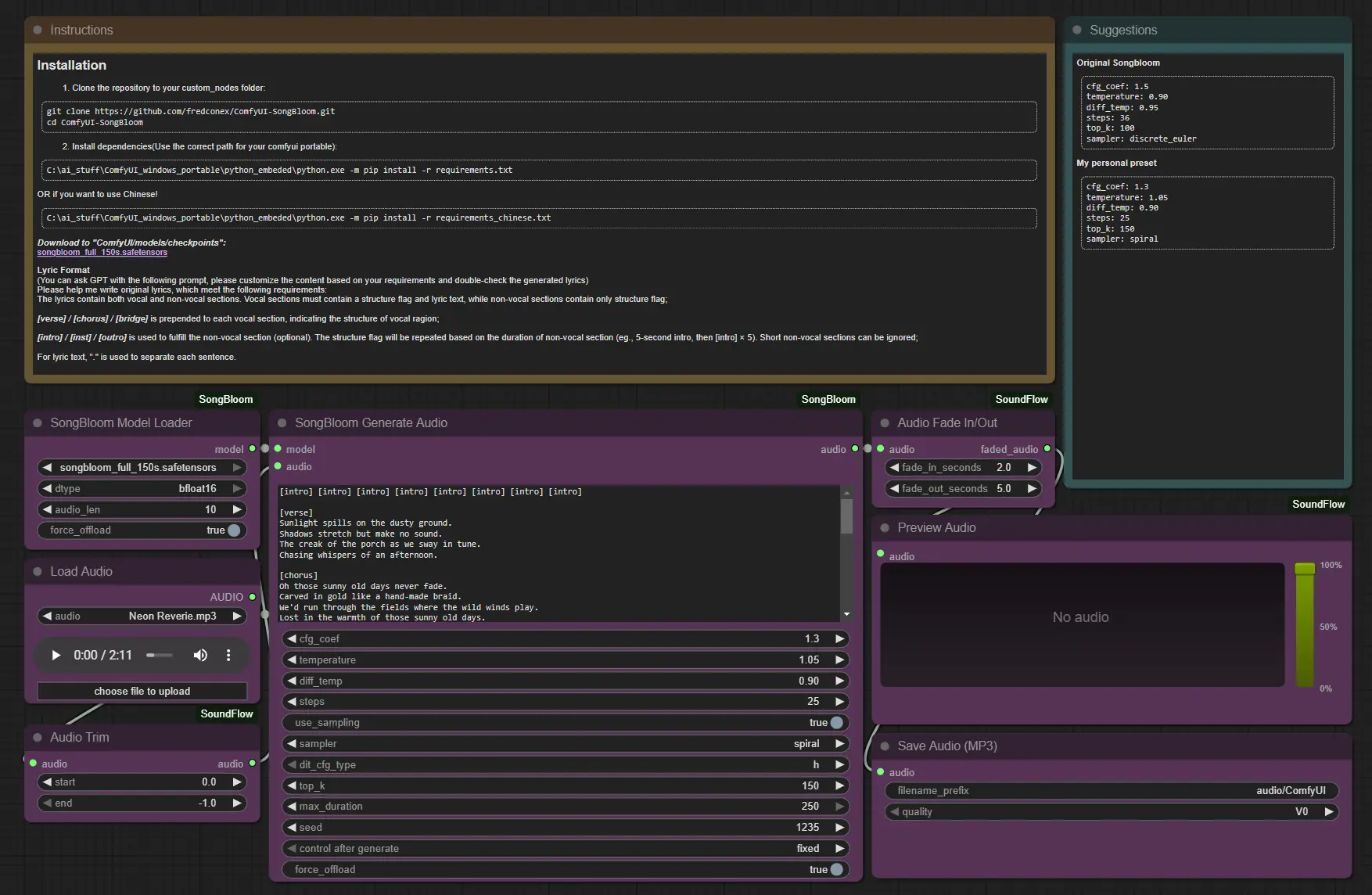
SongBloom:一种实现结构连贯与高保真度的全曲生成新框架在自动音乐生成领域,生成一首具备完整结构、风格统一、人声与伴奏和谐融合的全长歌曲,依然是极具挑战性的任务。 现有方法——无论是基于语言模型的自回归生成,还是基于扩散模型的音频合成——往往面临两难困境...语音模型# SongBloom# 音乐生成6个月前01000
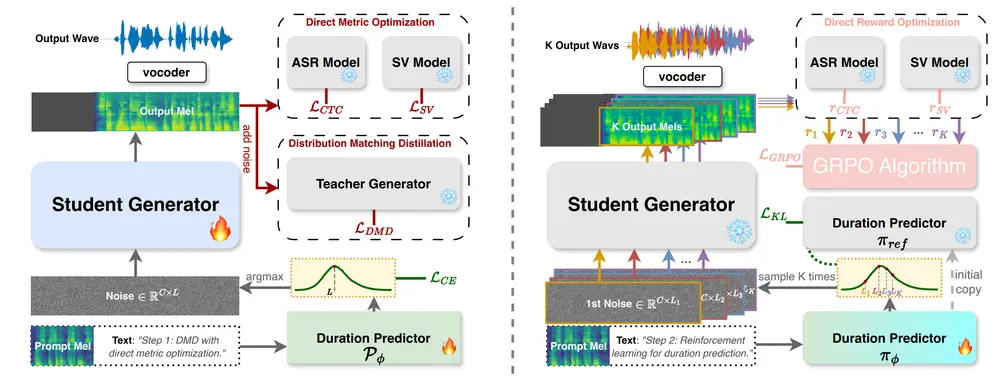
DMOSpeech 2:用强化学习优化语音合成的时长预测在零样本文本到语音(TTS)领域,基于扩散模型的系统近年来取得了显著进展。然而,大多数方法仍难以实现对整个生成流程的端到端感知质量优化——尤其是时长预测这一关键组件,长期依赖自监督训练,未能与语音生成...语音模型# DMOSpeech 2# TTS 框架6个月前03030
英伟达发布 Audio Flamingo 3:全球首个支持 10 分钟音频理解的开源模型在视觉和文本领域大模型持续突破之后,音频理解也开始迎来新的里程碑。英伟达近日发布了 Audio Flamingo 3(AF3),这是目前最先进的开源大型音频语言模型(Large Audio Langu...语音模型# Audio Flamingo 3# 英伟达# 音频理解模型7个月前04280
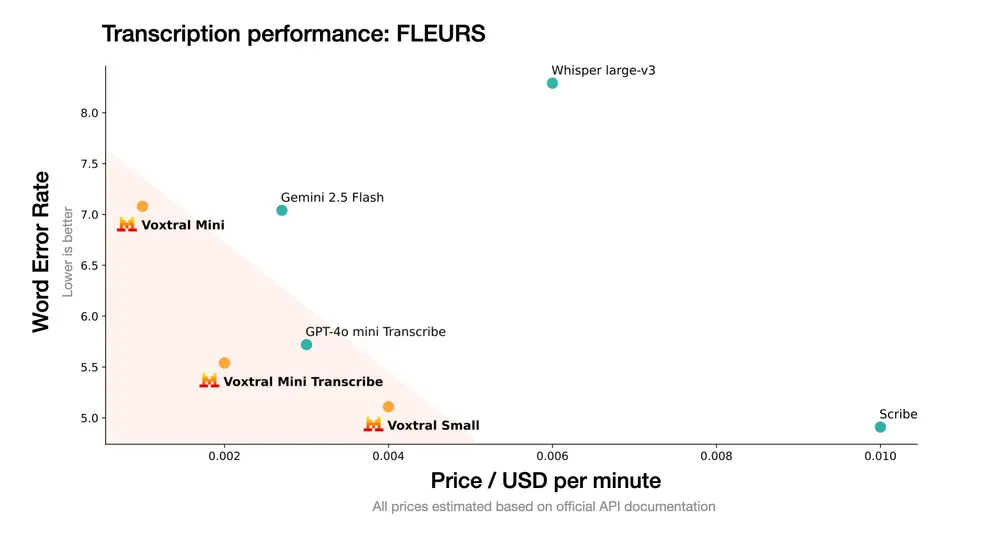
Mistral 推出首个面向企业的开源语音理解模型 Voxtral:具备高精度的语音转录能力,还支持对音频内容的深度语义理解,如问答、摘要、翻译和功能调用随着语音逐渐成为人机交互的核心方式,法国AI初创公司 Mistral 正式发布其首个开源音频模型 Voxtral,标志着其在语音智能领域的重大突破。 Voxtral 是一款面向企业的语音理解模型(Sp...语音模型# Mistral# Voxtral# 语音理解模型7个月前01600
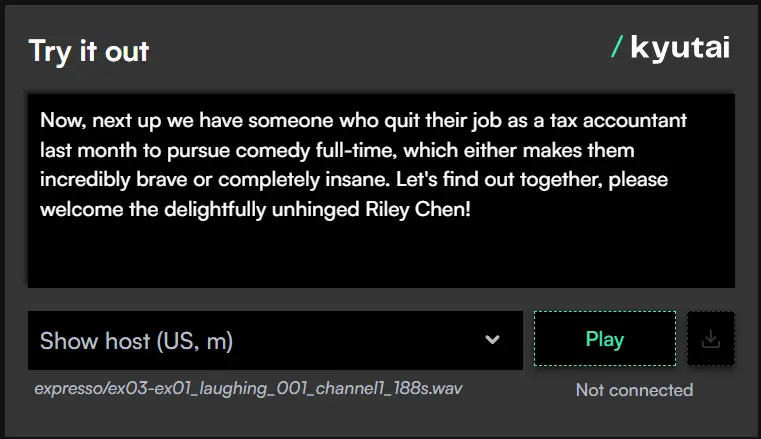
Kyutai Labs推出新一代流式TTS模型Kyutai TTS:实时语音生成迈入新阶段近日,Kyutai Labs 正式开源了一款名为 Kyutai TTS 的文本转语音(TTS)模型,参数规模达到16亿,支持实时、流式处理,成为该领域的技术新标杆。这一模型不仅具备出色的语音生成能力...语音模型# Kyutai Labs# Kyutai TTS# TTS模型7个月前02500
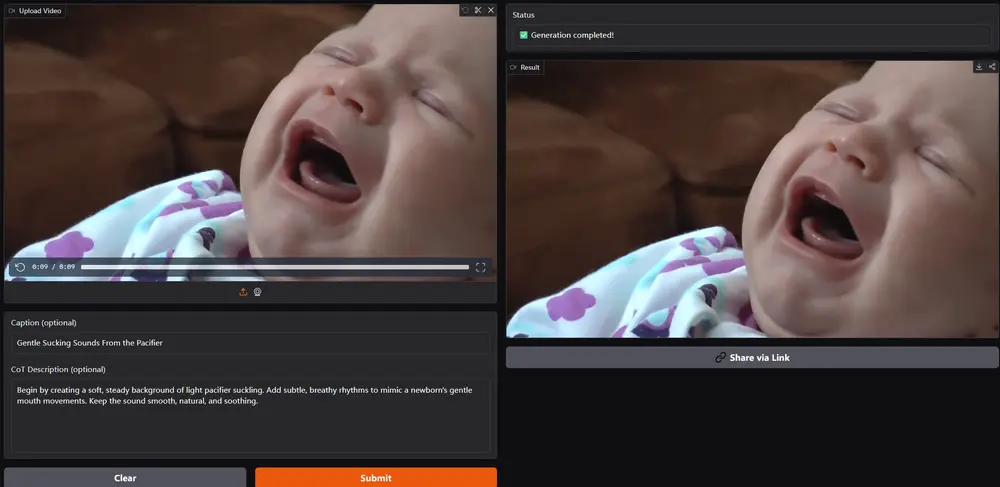
阿里通义实验室联合港科大 & 浙大推出 ThinkSound:首个支持视频到音频生成与编辑的统一框架阿里巴巴通义实验室联合香港科技大学与浙江大学的研究团队提出了一种全新的多模态视频-音频生成与编辑框架 —— ThinkSound。 项目主页:https://thinksound-project.gi...语音模型# ThinkSound# 多模态视频-音频生成7个月前01950
阿里通义项目组更新 Qwen-TTS:合成语音自然度接近人类水平阿里通义实验室通过 Qwen API 发布了最新版本的 Qwen-TTS 语音合成模型(支持 qwen-tts-latest 或 qwen-tts-2025-05-22)。该模型在语音合成领域实现了多...语音模型# Qwen-TTS7个月前03830
对话也能生成语音?复旦大学开源 MOSS-TTSD 实现高质量对话语音合成复旦大学 OpenMOSS 团队正式发布了全新语音生成模型 MOSS-TTSD(Text to Spoken Dialogue),这是目前首个能够直接从对话文本生成自然、富有表现力对话语音的大规模模型...语音模型# MOSS-TTSD# 复旦大学7个月前05750
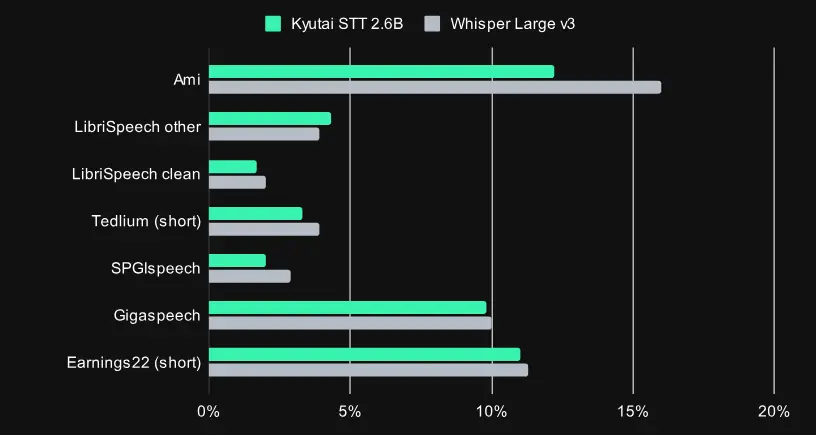
Kyutai STT:低延迟、高吞吐的流式语音识别模型,专为实时交互优化近日,Kyutai 实验室发布了一款全新的流式语音转文本(Speech-to-Text)模型——Kyutai STT,专为实时语音交互场景设计,在延迟与准确性之间实现了出色平衡,非常适合如语音助手、在...语音模型# Kyutai STT# 语音识别模型7个月前03240