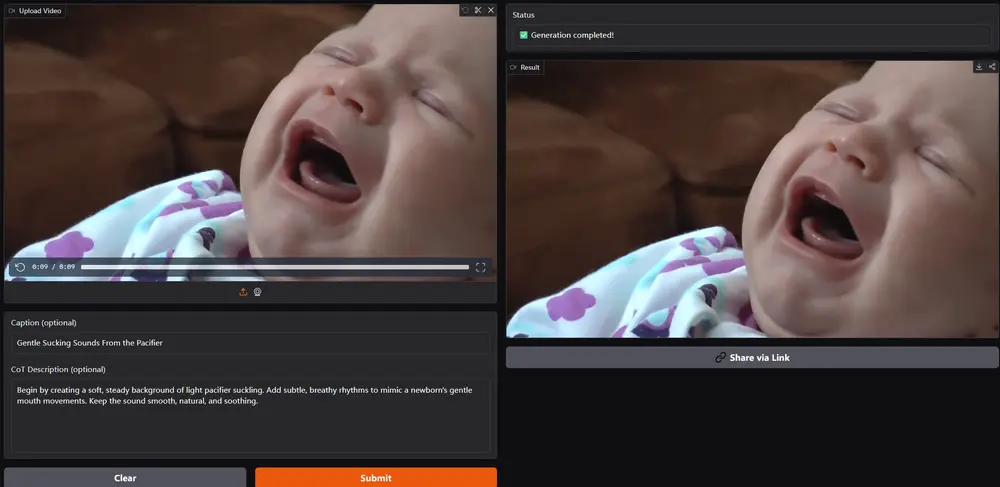
Kyutai Labs推出新一代流式TTS模型Kyutai TTS:实时语音生成迈入新阶段近日,Kyutai Labs 正式开源了一款名为 Kyutai TTS 的文本转语音(TTS)模型,参数规模达到16亿,支持实时、流式处理,成为该领域的技术新标杆。这一模型不仅具备出色的语音生成能力...语音模型# Kyutai Labs# Kyutai TTS# TTS模型9个月前02820
Kurma AI专为水产养殖领域打造的通用语言模型AQUA-7B和AQUA-1B:以生成式 AI 重塑美国水产养殖业美国拥有广阔的海岸线、纯净的水域资源以及领先的技术基础,具备发展高产、可持续水产养殖业的天然优势。然而,这一潜力远未被充分挖掘。 据2021年数据显示,美国人均海产品消费量已达约 20.5磅,其中 8...大语言模型# AQUA-1B# AQUA-7B# Kurma AI9个月前03800
阿里Ovis团队发布统一多模态模型Ovis-U1:理解、生成与编辑三位一体近日,阿里巴巴通义实验室Ovis团队正式发布了新一代统一多模态大模型——Ovis-U1。该模型以30亿参数为基础,实现了对多模态任务的全面覆盖,涵盖图像理解、文本到图像生成以及图像编辑三大核心能力。 ...图像模型# Ovis-U1# 统一多模态模型9个月前02830
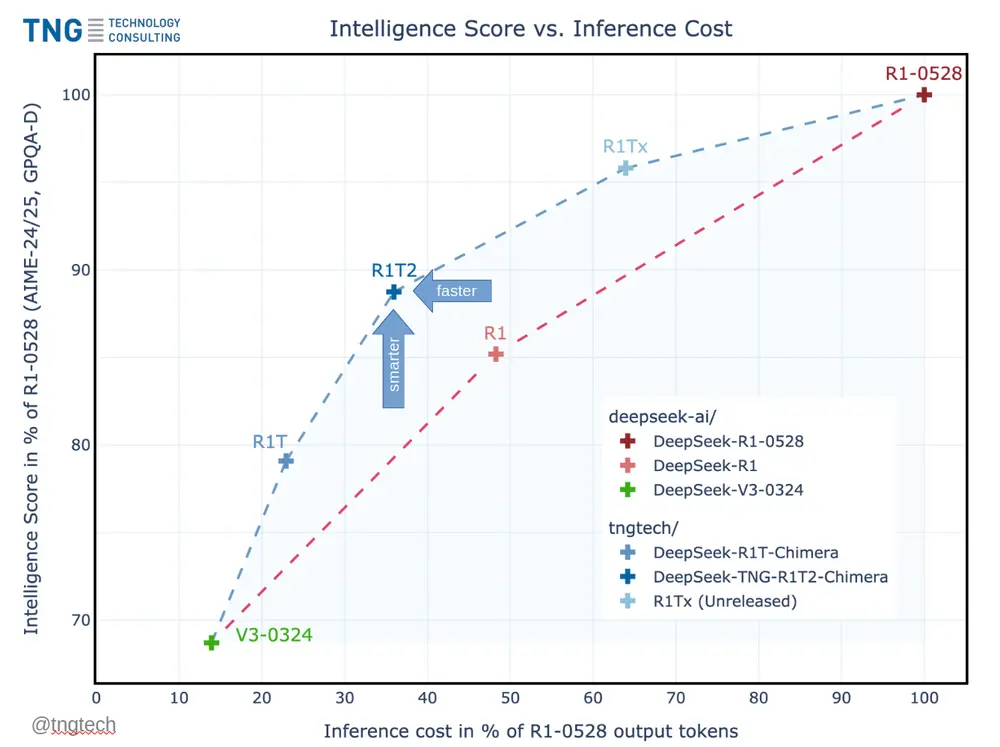
德国科技咨询公司TNG发布全新 DeepSeek R1-0528 变体DeepSeek-TNG R1T2 Chimera,速度提升 200%距离中国 AI 初创公司 DeepSeek 发布其热门开源模型 DeepSeek-R1-0528 不到两个月,该模型因其低成本训练和高性能推理能力迅速风靡全球 AI 社区。 如今,这款强大模型已被广泛...大语言模型# DeepSeek-R1-0528# DeepSeek-TNG R1T2 Chimera# TNG9个月前02450
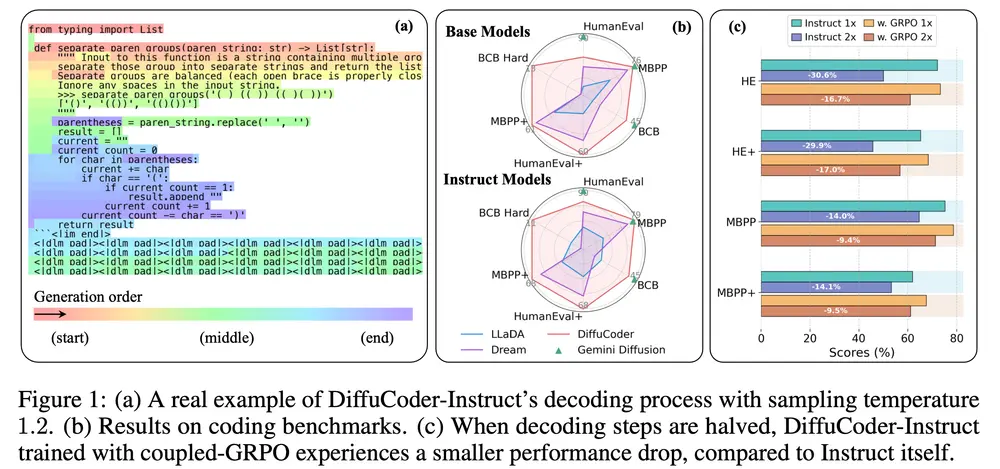
苹果 & 香港研究人员推出 DiffuCoder:首个面向代码生成的扩散大语言模型近日,苹果与香港的研究团队联合提出了一种全新的基于扩散机制的大语言模型(Diffusion Large Language Model, dLLM)——DiffuCoder,专为代码生成任务设计。 Gi...大语言模型# DiffuCoder# 扩散大语言模型# 苹果9个月前01960
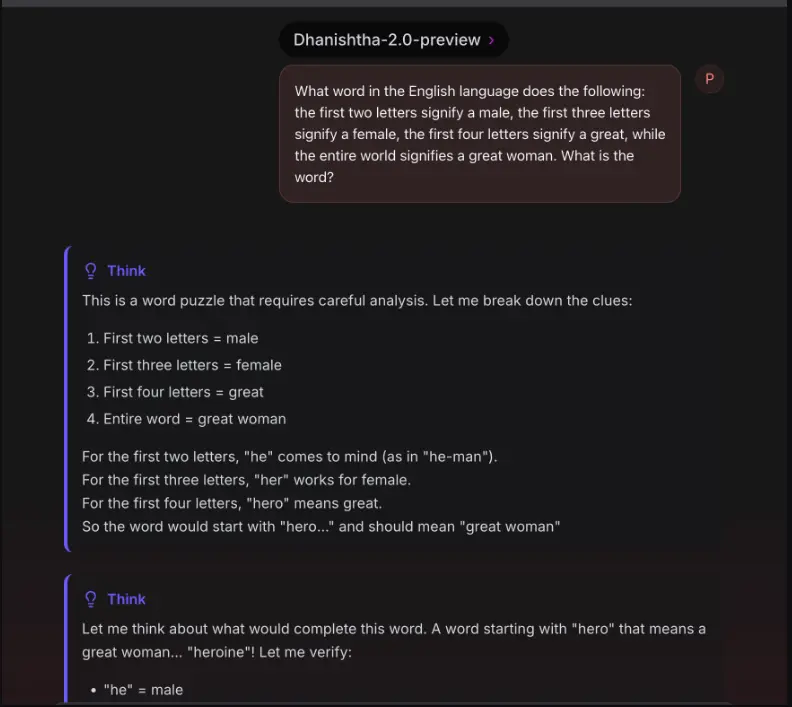
HelpingAI 团队推出全球首个支持“中间思维”的AI模型Dhanishtha-2.0想象一个不仅能快速回答问题,还能像人类一样逐步思考、自我反思、甚至中途改变主意的人工智能。这不是科幻场景,而是 Dhanishtha-2.0 带来的现实。 模型:https://huggingface...大语言模型# Dhanishtha-2.0# HelpingAI8个月前02000
阿里通义实验室联合港科大 & 浙大推出 ThinkSound:首个支持视频到音频生成与编辑的统一框架阿里巴巴通义实验室联合香港科技大学与浙江大学的研究团队提出了一种全新的多模态视频-音频生成与编辑框架 —— ThinkSound。 项目主页:https://thinksound-project.gi...语音模型# ThinkSound# 多模态视频-音频生成9个月前02250
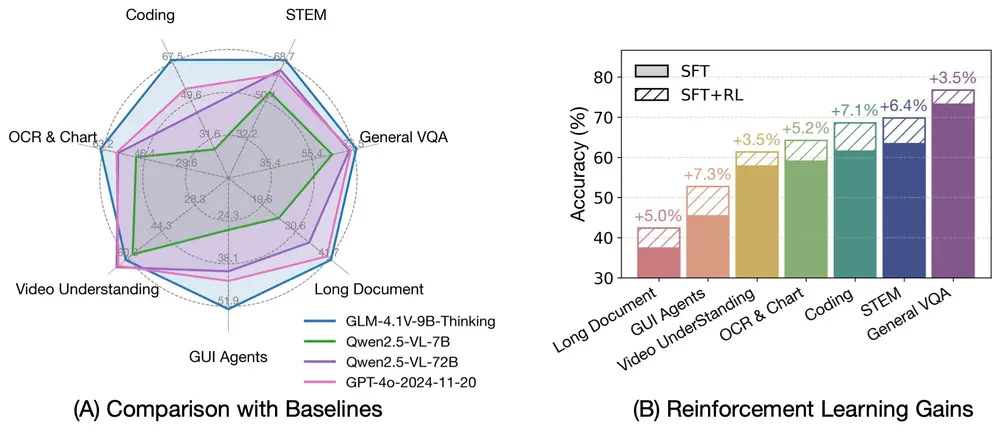
智谱AI联合清华推出新一代视觉语言推理模型开源 GLM-4.1V-9B-Thinking随着智能任务日益复杂,视觉语言大模型(VLM)正从基础的多模态感知迈向更高层次的推理能力提升。为了应对这一趋势,智谱AI 与清华大学联合推出了新一代 VLM 开源模型 —— GLM-4.1V-9B-T...多模态模型# GLM-4.1V-9B-Thinking# 智谱AI9个月前03310
BRIA AI 推出 Bria 3.2:专为商业设计的下一代文本到图像模型BRIA AI 正式发布其最新文本到图像模型 Bria 3.2。作为一款专为企业和商业应用打造的生成模型,Bria 3.2 凭借仅 40 亿参数 的轻量架构,在美学效果与文本渲染能力方面表现优异,经评...图像模型# Bria 3.2# BRIA AI9个月前01820
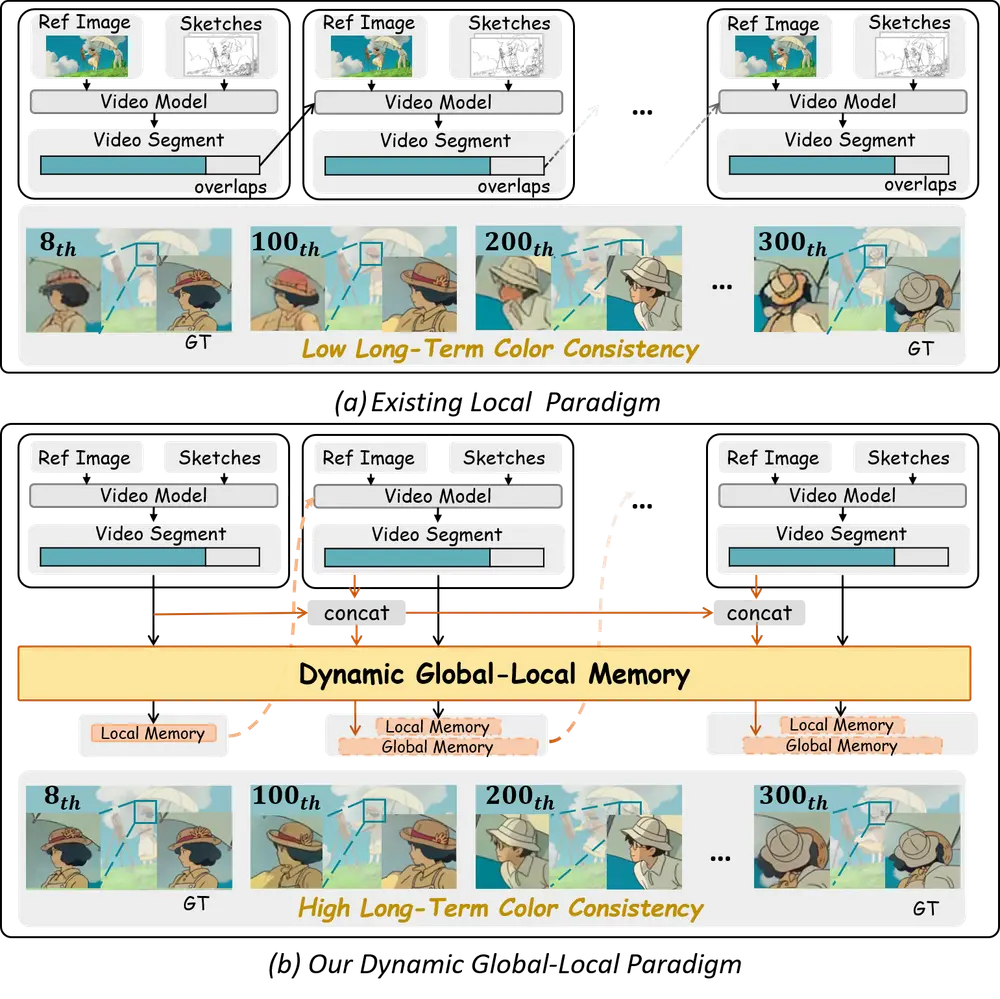
中科大 & 港科大联合推出 LongAnimation :实现长动画自动上色的新框架来自中国科学技术大学与香港科技大学的研究团队联合提出了一种名为 LongAnimation 的新型动画着色框架。该框架旨在实现长动画序列的自动化着色,并在整个动画过程中保持长期的颜色一致性。 项目主页...视频模型# LongAnimation# 动画自动上色9个月前02270
快手 Keye 团队发布 Kwai Keye-VL :专注短视频理解的多模态大模型快手 Keye 团队近日推出了一款全新的多模态大型语言模型(MLLM)——Kwai Keye-VL。该模型拥有 80 亿参数,专注于提升对短视频的理解能力,同时保持强大的通用视觉-语言能力。 GitH...多模态模型# Kwai Keye-VL# 多模态大模型# 快手9个月前03160
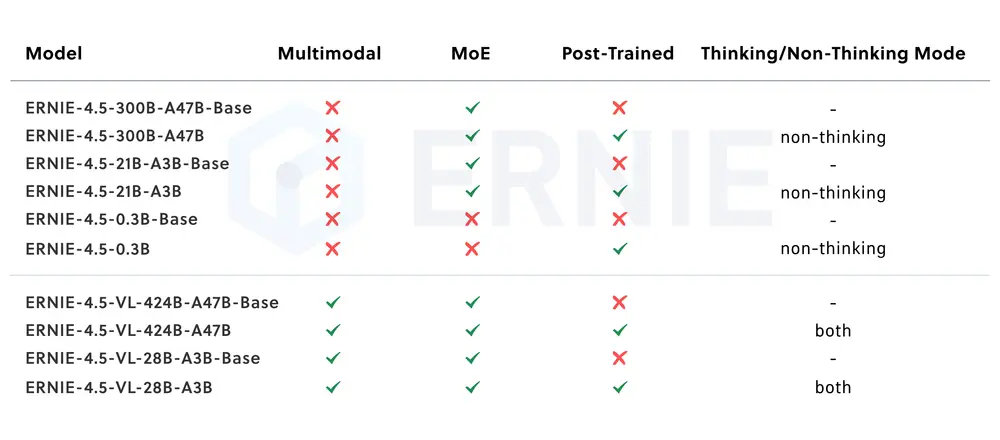
百度开源 ERNIE 4.5:覆盖 0.3B 到 424B 参数的大型语言模型系列百度正式开源了其最新的 ERNIE 4.5 系列,这是继 ERNIE 系列之后又一重磅发布的基础语言模型家族。该系列包含 10 款不同规模与架构的模型,从仅 0.3B(十亿)参数的小型密集模型 到高达...大语言模型# ERNIE 4.5# 百度9个月前03470