字节跳动提出的新一代多主体可控图像生成模型XVerse在文本到图像生成领域,如何实现对多个主体身份和语义属性(如姿势、风格、照明)的细粒度控制,同时保持高质量和一致性,一直是一个极具挑战性的问题。 传统方法往往存在以下问题: 在多主体场景中容易引入视觉伪...图像模型# XVerse# 图像生成模型9个月前04830
阿里 Qwen 项目组正式推出全新多模态模型Qwen VLo随着多模态大模型的不断发展,我们对技术边界的认知也在持续被刷新。从最初的 QwenVL 到如今的 Qwen2.5 VL,我们在提升模型图像理解能力方面不断取得进步。 项目主页:https://qwen...多模态模型# Qwen VLo# Qwen 项目组# 阿里巴巴9个月前02280
阿里通义项目组更新 Qwen-TTS:合成语音自然度接近人类水平阿里通义实验室通过 Qwen API 发布了最新版本的 Qwen-TTS 语音合成模型(支持 qwen-tts-latest 或 qwen-tts-2025-05-22)。该模型在语音合成领域实现了多...语音模型# Qwen-TTS9个月前04130
Jina AI推出文本嵌入模型Jina Embeddings v4:多模态多语言检索的通用嵌入模型Jina AI正式发布 jina-embeddings-v4 —— 一款全新的38亿参数通用嵌入模型,支持文本与图像输入,适用于多种检索任务。该模型在多个基准测试中表现优异,特别是在处理表格、图表等视...多模态模型# Jina AI# Jina Embeddings v4# 文本嵌入模型10个月前04300
JarvisArt:由AI驱动的照片修饰智能体,释放你的艺术创造力来自厦门大学、香港科技大学(广州)、字节跳动、新加坡国立大学等机构的研究人员联合推出了一项令人瞩目的新成果 —— JarvisArt。这是一个由多模态大语言模型(MLLM)驱动的照片修饰智能体,能够理...图像模型# JarvisArt# 照片修饰智能体10个月前04220
谷歌发布 Gemma 3n:为移动设备而生的高效多模态AI模型继去年首款 Gemma 模型发布以来,Gemmaverse 生态系统迅速壮大,累计下载量突破 1.6亿次,覆盖从安全防护到医疗应用等十余个专业领域。社区创新成果斐然,例如 Roboflow 打造的企业...大语言模型# Gemma 3n# 谷歌10个月前01820
腾讯推出全新MoE模型Hunyuan-A13B:小参数、高性能的AI新选择在大模型持续演进的过程中,如何在提升性能的同时控制资源消耗,成为行业面临的关键挑战。腾讯最新推出的 Hunyuan-A13B 模型,正是这一问题的创新性解决方案。该模型采用混合专家(MoE)架构,在仅...大语言模型# Hunyuan-A13B# 腾讯10个月前01610
黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]截至今日,所有高性能的生成式图像编辑模型均为专有工具。今天,这一局面发生了改变。 黑森林实验室(Black Forest Labs)发布了 FLUX.1 Kontext [dev],这是 FLUX.1...图像模型# FLUX.1 Kontext [dev]# 图像编辑模型# 黑森林实验室10个月前06450
Janus-4o:基于数据集 ShareGPT-4o-Image 的新型多模态图像生成模型香港中文大学(深圳) 的研究人员推出了一项重要的多模态研究成果 —— ShareGPT-4o-Image 数据集 及其衍生的开源多模态大语言模型 Janus-4o。该研究旨在将 GPT-4o 在图像生...图像模型# Janus-4o# ShareGPT-4o-Image# 数据集10个月前03810
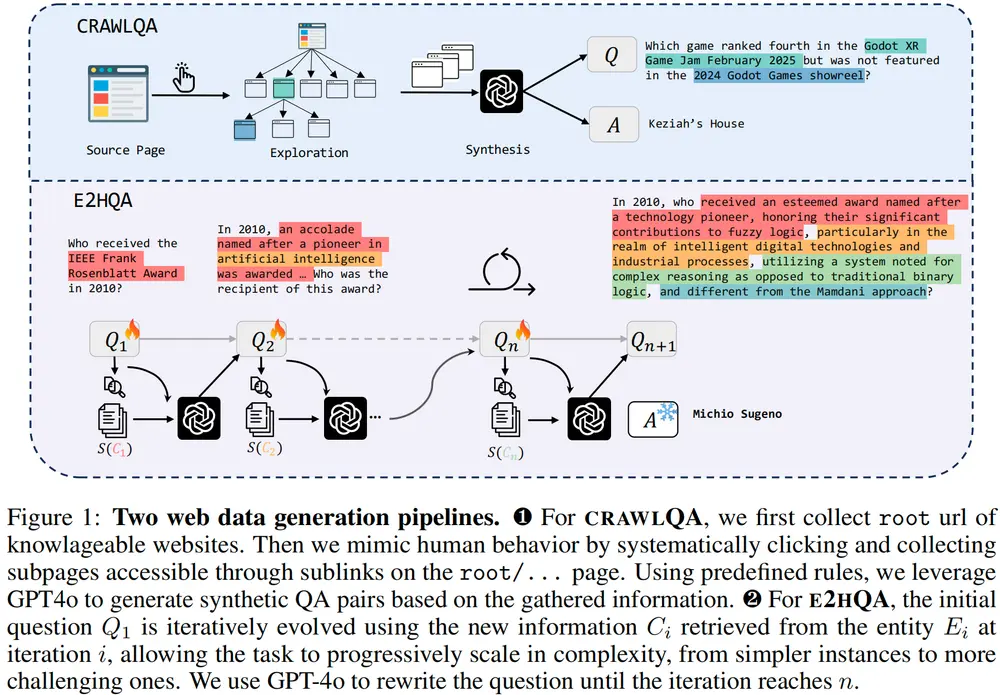
阿里通义实验室推出的端到端网络代理训练框架WebDancer在信息检索和智能代理领域,如何让 AI 代理具备自主搜索、推理和决策能力是一个关键挑战。为此,阿里通义实验室提出了 WebDancer —— 一个全新的 端到端代理训练框架,旨在增强基于网络的代理在多...大语言模型# WebDancer# 阿里通义实验室10个月前03080
对话也能生成语音?复旦大学开源 MOSS-TTSD 实现高质量对话语音合成复旦大学 OpenMOSS 团队正式发布了全新语音生成模型 MOSS-TTSD(Text to Spoken Dialogue),这是目前首个能够直接从对话文本生成自然、富有表现力对话语音的大规模模型...语音模型# MOSS-TTSD# 复旦大学10个月前07180
Neta Lumina 发布:专为二次元创作打造的高品质图像生成模型由捏Ta实验室(Neta.art)训练的 Neta Lumina 是一款专注于二次元风格的高质量图像生成模型。此模型基于上海人工智能实验室 Alpha-VLLM 团队开源的 Lumina-Image...图像模型# Neta Lumina# 二次元10个月前01,1250







![黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]](https://pic.sd114.wiki/wp-content/uploads/2025/06/1750964036-1750964036-FLUX.1-Kontext-2.webp~tplv-o4t1hxlaqv-image.image)