DRA-Ctrl:利用视频生成模型实现可控图像生成的新范式近年来,视频生成模型因其能够捕捉现实世界中的动态变化和复杂因果关系,被广泛视为一种“世界模拟器”。它们整合了视觉、时间、空间和语义等多个维度的信息,在建模长程依赖和多模态交互方面展现出强大潜力。 那么...图像模型# DRA-Ctrl# HunyuanVideo-I2V# 知识迁移10个月前03800
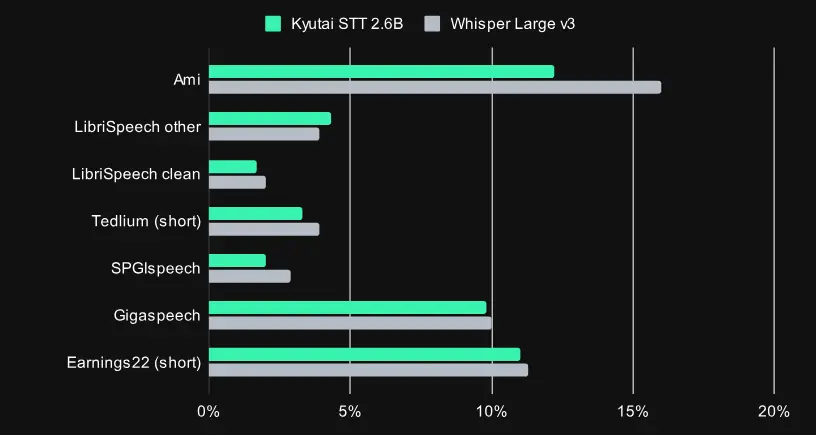
Kyutai STT:低延迟、高吞吐的流式语音识别模型,专为实时交互优化近日,Kyutai 实验室发布了一款全新的流式语音转文本(Speech-to-Text)模型——Kyutai STT,专为实时语音交互场景设计,在延迟与准确性之间实现了出色平衡,非常适合如语音助手、在...语音模型# Kyutai STT# 语音识别模型10个月前03810
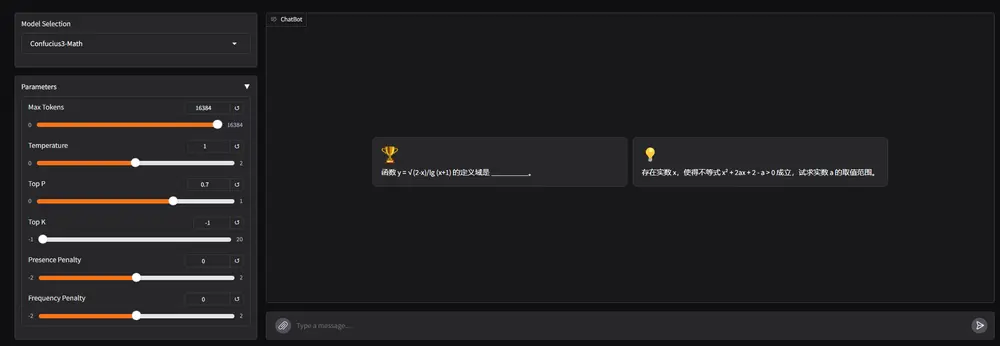
国内首个专攻K-12数学教育的大模型开源!网易有道发布“子曰3数学模型”,可在单卡消费级显卡运行网易有道宣布正式开源其“子曰3”系列大模型中的 数学推理专用模型——Confucius3-Math(中文名:子曰3数学模型),这是国内首个专注于 K-12 数学教育、且可在单块消费级 GPU(如 RT...大语言模型# Confucius3-Math# 子曰3数学模型# 网易有道10个月前03410
微软新推 Mu 模型:专为 Windows 设置代理而生的小而强语言模型微软近日推出了一款全新的小型语言模型——Mu,它专为边缘设备和特定任务设计,在本地运行时展现出卓越性能。目前,Mu 已经在 Copilot+ PC 的 Windows Insider 开发频道中,用于...大语言模型# Mu 模型# 微软10个月前02570
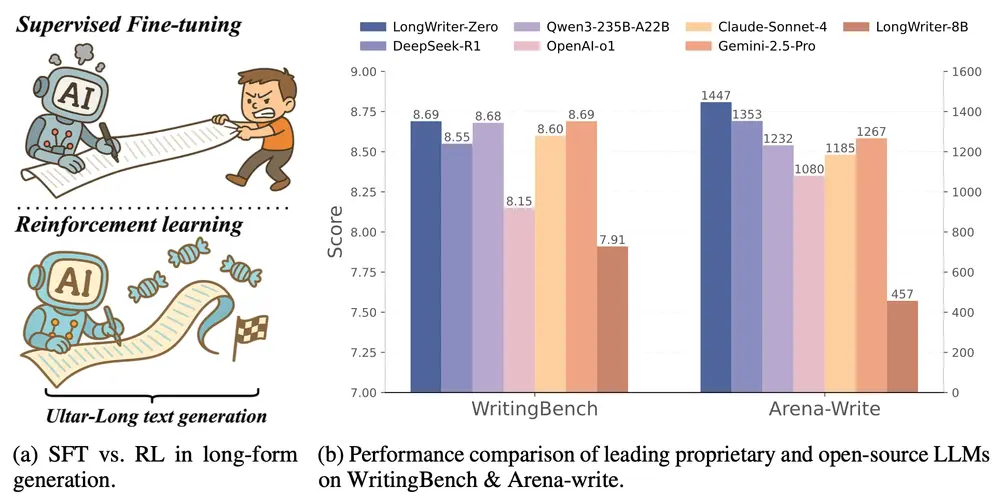
LongWriter-Zero:通过强化学习从零开始训练大语言模型,以实现超长文本生成新加坡科技设计大学和清华大学的研究人员推出新型模型LongWriter-Zero,基于 Qwen 2.5-32B-Base 构建,通过强化学习(RL)从零开始训练大语言模型(LLMs),以实现超长文本...大语言模型# LongWriter-Zero# 大语言模型10个月前02700
多模态框架Tar:通过统一的离散语义表示将视觉理解和生成任务整合到一个共享空间中香港中文大学和字节跳动的研究人员推出多模态框架Tar,通过统一的离散语义表示将视觉理解和生成任务整合到一个共享空间中。该框架的核心是 Text-Aligned Tokenizer (TA-Tok),它...图像模型# Tar# 多模态框架10个月前04230
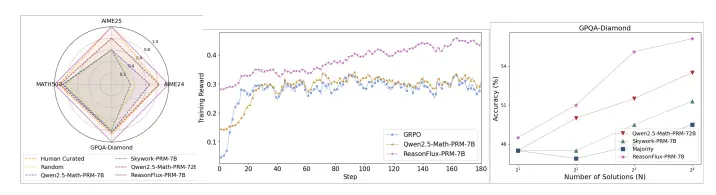
新型轨迹感知过程奖励模型(PRM) ReasonFlux-PRM:专门用于评估大型语言模型在长链推理中的轨迹-响应型推理痕迹伊利诺伊大学厄巴纳-香槟分校、普林斯顿大学、康奈尔大学和字节跳动的研究人员推出新型轨迹感知过程奖励模型(PRM) ReasonFlux-PRM,专门用于评估大型语言模型(LLMs)在长链推理(Long...大语言模型# ReasonFlux-PRM# 轨迹感知过程奖励模型10个月前02500
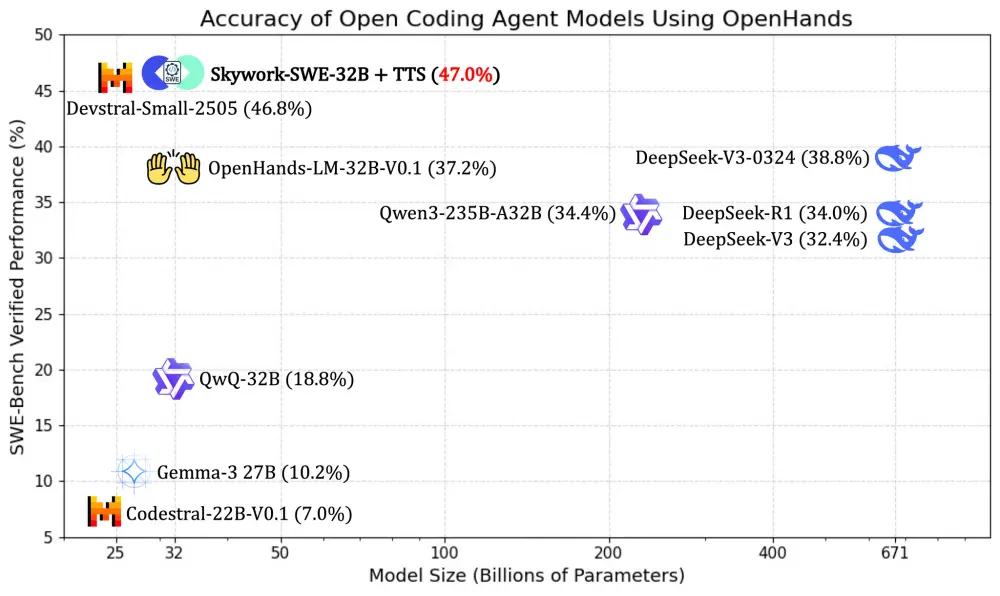
昆仑万维开源代码模型 Skywork-SWE-32B:用消费级显卡部署 AI 工程师的新可能今天,昆仑万维正式宣布开源其最新推出的代码智能体 Skywork-SWE-32B,该模型专为软件工程(SWE)任务设计,在 SWE-bench Verified 基准测试中达到 38.0% 的 pas...大语言模型# Skywork-SWE-32B# 代码模型# 昆仑万维10个月前03650
北京人工智能研究院推出新一代统一多模态图像生成模型OmniGen2:视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力在上一代模型 OmniGen 发布仅 7 个月后,北京人工智能研究院正式推出了其升级版——OmniGen2,一个集成了视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力的统一多模态模型...图像模型# OmniGen2# 北京人工智能研究院# 统一多模态图像生成10个月前04120
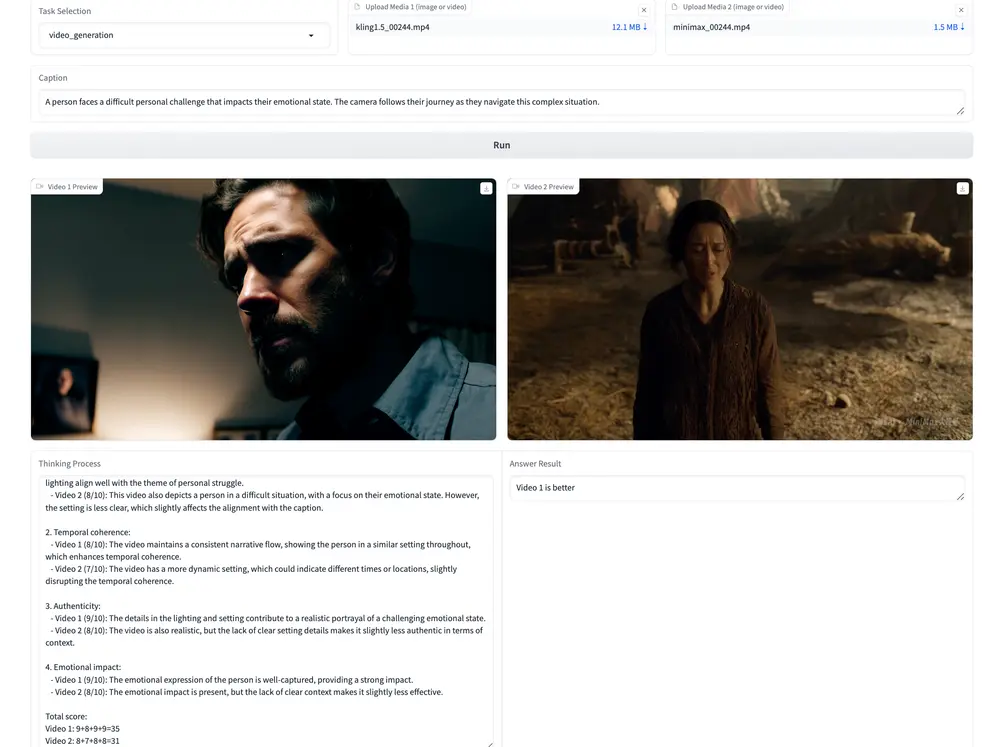
复旦联合团队发布首个统一多模态奖励模型UNIFIEDREWARD:图像视频都能评,还能优化视觉生成近日,由复旦大学、上海创新创意设计研究院、上海人工智能实验室和上海人工智能科学院组成的研究团队,正式发布了全球首个支持图像与视频理解与生成任务评估的统一奖励模型 —— UNIFIEDREWARD。 项...多模态模型# UNIFIEDREWARD# 统一多模态奖励模型10个月前04160
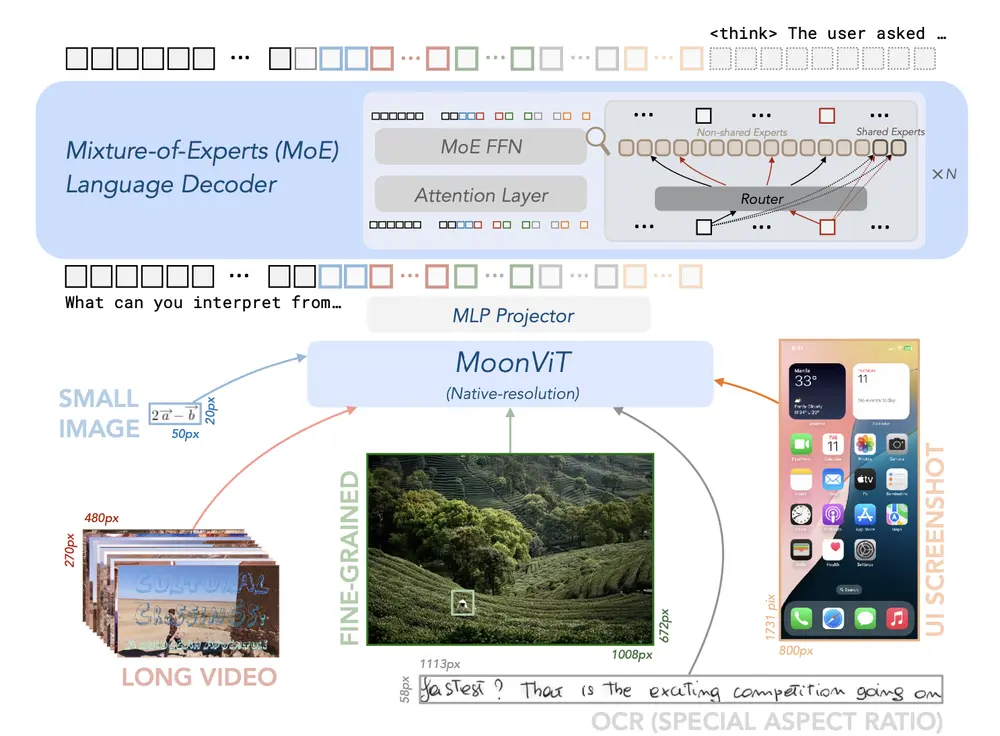
Kimi-VL-A3B-Thinking-2506 正式上线:更强推理、更高分辨率、支持视频理解两个月前,月之暗面推出了首个开源多模态推理模型 Kimi-VL-A3B-Thinking,如今他们正式推出其升级版本 Kimi-VL-A3B-Thinking-2506。 模型:https://hug...多模态模型# Kimi-VL-A3B-Thinking-2506# 多模态推理模型# 月之暗面10个月前03960
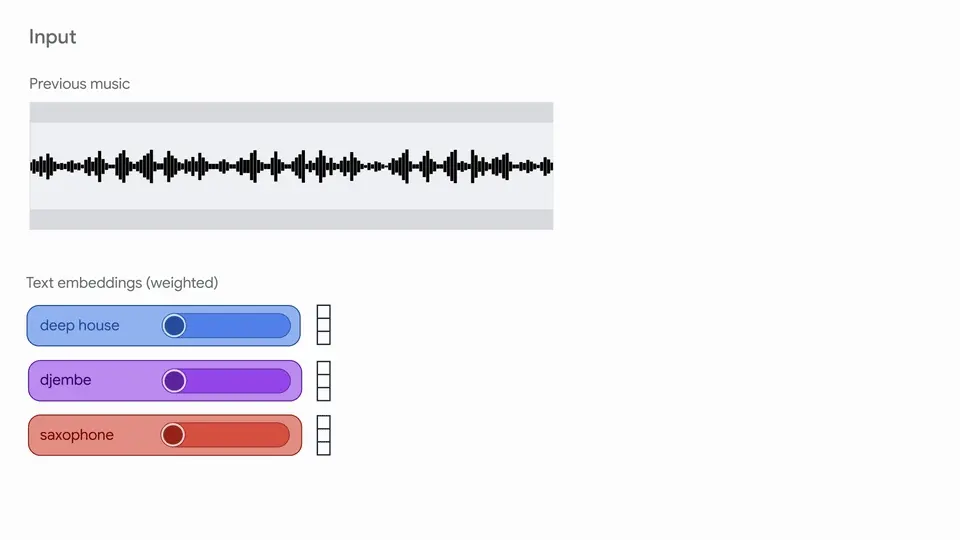
谷歌开源实时音乐生成模型 Magenta RealTime:8亿参数,支持文本/音频操控今天,Google DeepMind 宣布开源一款名为 Magenta RealTime 的实时音乐生成模型。该模型基于 Apache 2.0 许可证发布,具备实时交互能力,能够根据文本提示或音频示例...语音模型# Magenta RealTime# 音乐生成模型10个月前03510