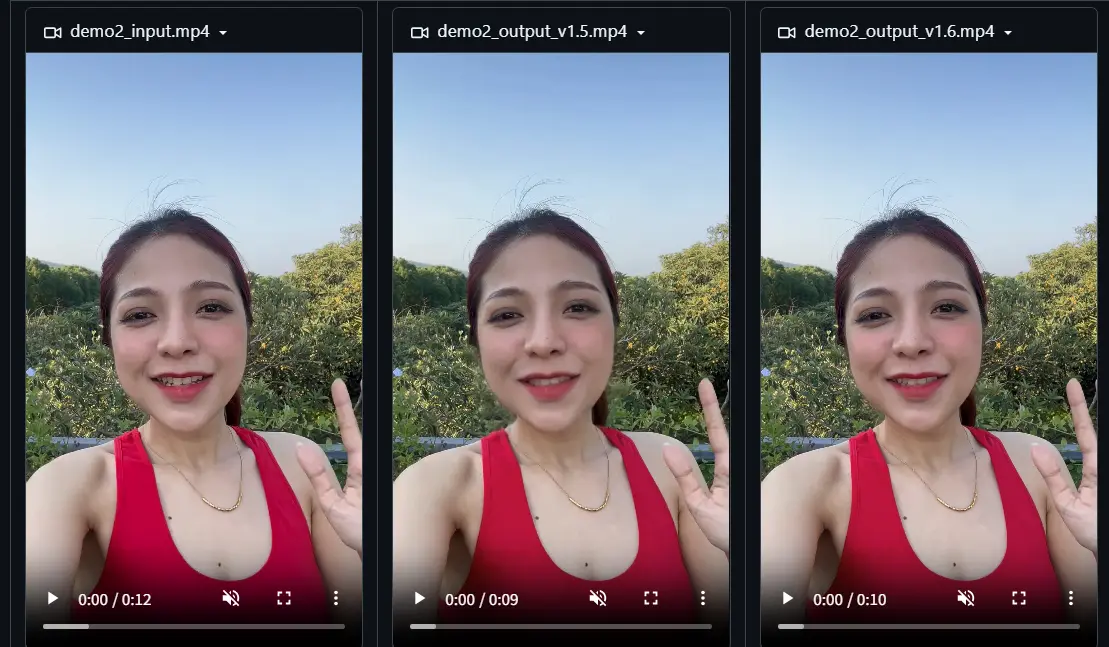
字节跳动发布 LatentSync 1.6:聚焦高分辨率视频生成,解决模糊问题字节跳动发布了其对口型视频生成模型 LatentSync 的新版本 1.6,重点解决了此前版本中生成牙齿和嘴唇区域模糊的问题。 模型:https://huggingface.co/ByteDance...视频模型# LatentSync 1.6# 字节跳动6个月前02820
字节跳动发布Seaweed APT2:专为实时交互式场景设计的流式视频生成模型字节跳动研究团队推出了Seaweed APT2,一款专为实时交互式场景设计的流式视频生成模型。该模型能够在单块H100 GPU上实现每秒24帧、分辨率高达736x416(等效640x480)的不间断视...视频模型# Seaweed APT2# 字节跳动6个月前02250
Meta推出基于视频训练的“世界模型”V-JEPA 2:AI“世界模型”迈出理解物理世界的重要一步Meta 发布了其最新 AI 研究成果 —— V-JEPA 2,一个基于视频训练的“世界模型”,旨在帮助 AI 更好地理解现实世界的物理规律,并用于机器人控制、任务规划等复杂场景。 项目主页:http...多模态模型# Meta# V-JEPA 2# 世界模型6个月前02100
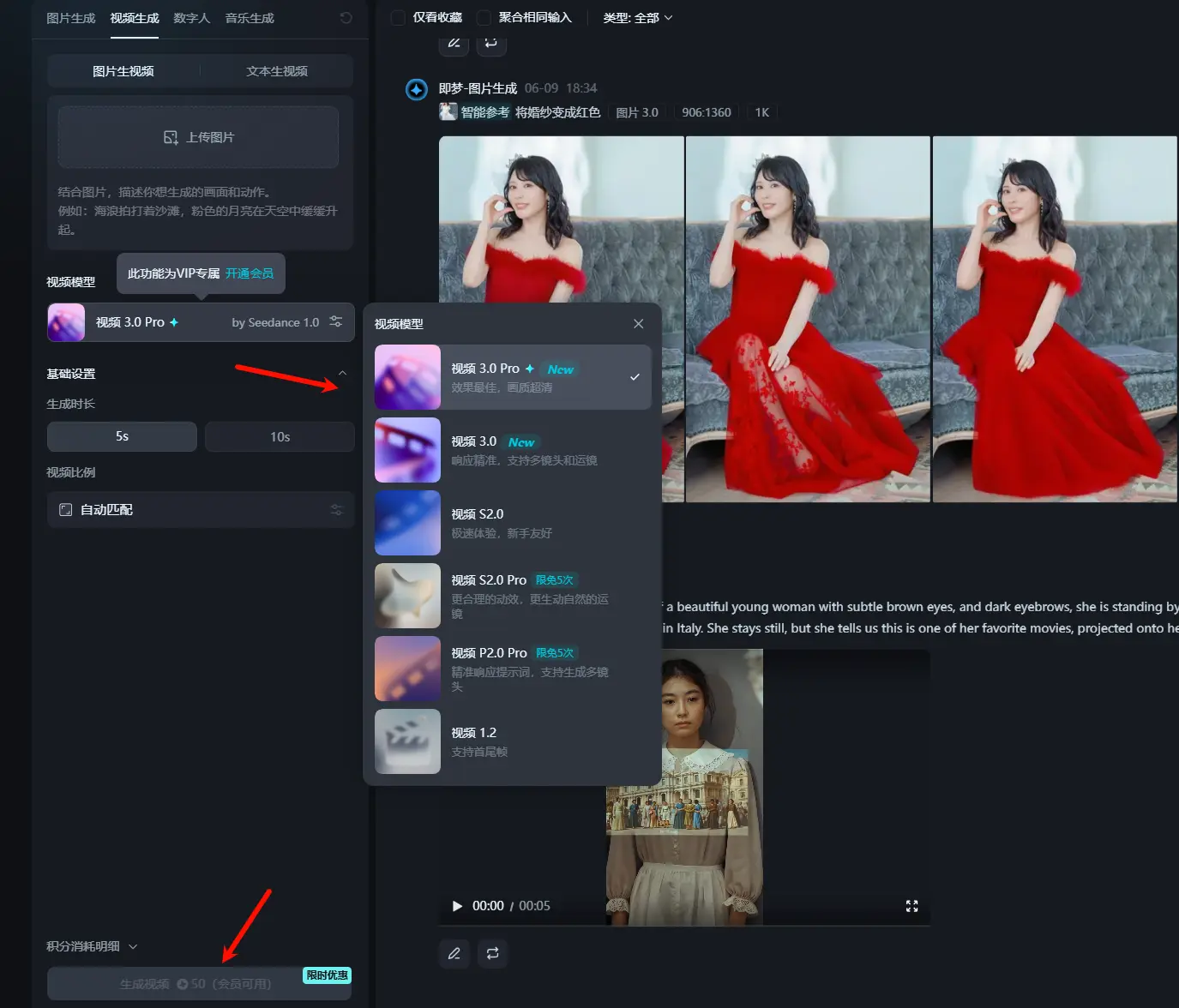
字节跳动推出视频生成模型 Seedance 1.0,视频生成迈入“电影级”体验字节跳动正式发布了其最新的视频生成模型 Seedance 1.0。该模型已集成在字节旗下 AI 创作平台“即梦”中,并以“视频生成3.0 Pro”版本面向用户开放(需会员权限使用)。目前,每生成一个5...视频模型# Seedance 1.0# 字节跳动# 视频生成模型6个月前02530
Krea AI 正式发布首款图像模型 Krea 1:专治“AI味”画面!今天,AI 创意工具平台 Krea AI 宣布推出其首款自研图像生成模型 —— Krea 1。这款模型专注于解决一个长期困扰创作者的问题: “AI 生成的画面,总感觉像 AI。” 而现在,Krea 1...图像模型# Krea 1# Krea AI# 图像模型6个月前03590
北大 × 字节 × CMU 联合推出 PartCrafter:首个支持多部件联合生成的 3D 网格生成模型来自北京大学、字节跳动和卡内基梅隆大学(CMU)的研究团队联合发布了一项突破性的研究成果——PartCrafter,这是目前首款能够从单张 RGB 图像中联合生成多个语义明确、几何独立的 3D 网格部...3D模型# 3D 网格生成模型# PartCrafter6个月前01160
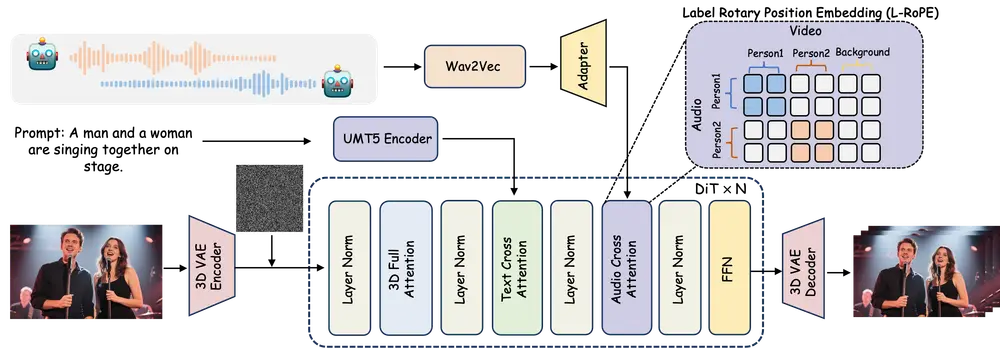
用于音频驱动的多人对话视频生成的新框架 MultiTalk:根据多路音频输入和提示生成包含互动的视频,同时确保唇部动作与音频同步中山大学深圳校区、美团和香港科技大学的研究人员推出用于音频驱动的多人对话视频生成的新框架 MultiTalk,该框架能够根据多路音频输入和提示生成包含互动的视频,同时确保唇部动作与音频同步。 项目主页...视频模型# MultiTalk# 多人对话视频生成6个月前01770
Mistral发布首款推理模型Magistral,挑战Gemini 2.5 Pro与Claude Opus法国AI实验室 Mistral AI 正式发布了其首个推理模型家族——Magistral,标志着这家以开源著称的AI公司正式进军高阶推理领域。 该系列包括两个版本: Magistral Small(2...大语言模型# Magistral# Mistral AI# 推理模型6个月前01270
音频描述数据集FusionAudio-1.2M:通过多模态上下文融合来生成细粒度的音频描述香港中文大学(深圳)和华南理工大学的研究人员推出推出一个名为FusionAudio-1.2M的音频描述数据集,通过多模态上下文融合来生成细粒度的音频描述。该数据集通过模拟人类听觉感知的方式,整合了多种...语音模型# FusionAudio-1.2M6个月前01470
华科大联合金山办公推出文档解析新模型MonkeyOCR近日,华中科技大学与金山办公联合研究团队发布了一款全新的文档解析模型 —— MonkeyOCR。该模型通过引入“结构-识别-关系”(Structure-Recognition-Relation, SR...多模态模型# MonkeyOCR# 文档解析7个月前02380
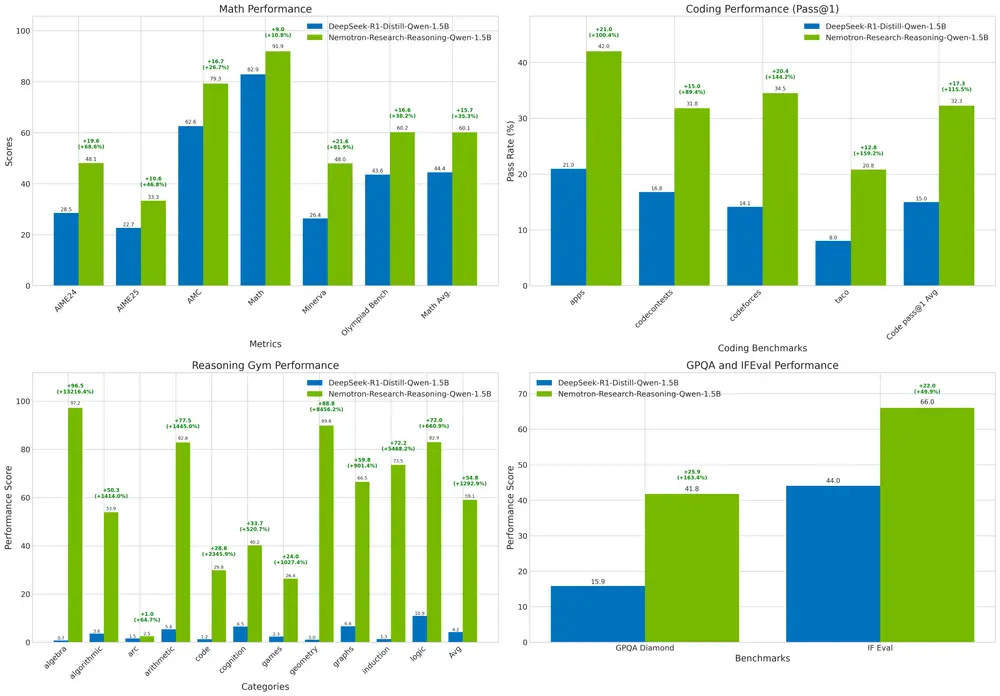
英伟达推出一款专为复杂推理任务设计的开源模型 — Nemotron-Research-Reasoning-Qwen-1.5B英伟达近日发布了一款专为复杂推理任务设计的开源模型 —— Nemotron-Research-Reasoning-Qwen-1.5B,该模型参数量为 1.5B,在数学、编程、科学问题和逻辑谜题等任务上...大语言模型# Nemotron-Research-Reasoning-Qwen-1.5B# 英伟达7个月前01080
昆仑万维推出 SkyReels-Audio:多模态驱动、无限长度的高质量会说话肖像视频生成框架昆仑万维旗下 SkyReels 团队 发布了全新音视频生成模型——SkyReals-Audio,一个用于合成高保真、时间一致的“会说话”肖像视频的统一框架。 项目主页:https://skyworka...语音模型# SkyReels-Audio# 昆仑万维7个月前02200