
来自北京大学、字节跳动和卡内基梅隆大学(CMU)的研究团队联合发布了一项突破性的研究成果——PartCrafter,这是目前首款能够从单张 RGB 图像中联合生成多个语义明确、几何独立的 3D 网格部件的结构化 3D 生成模型。
这一成果标志着 3D 生成领域从“整体建模”迈向“细粒度结构合成”的新阶段,对内容创作、工业设计、游戏开发等领域具有重要意义。

🔍 PartCrafter 是什么?
传统 3D 生成模型通常只能输出一个完整的形状,或需依赖图像分割进行分步重建。而 PartCrafter 的核心创新在于:
无需预分割输入图像,即可端到端地生成多个语义明确、几何独立的 3D 部件。
这意味着:
- 用户只需上传一张照片;
- 模型就能自动识别出物体的不同部分(如椅子的椅背、扶手、腿等);
- 并分别生成高质量的 3D 网格,实现真正的“部件级可控生成”。
此外,PartCrafter 不仅能还原可见部分,还能合理推断出图像中未直接展示的隐藏结构,具备强大的 3D 合成能力。
🧩 技术亮点:组合式潜在空间 + 层次注意力机制
PartCrafter 基于预训练的 3D 网格扩散变换器(DiT)构建,并引入两项关键创新:
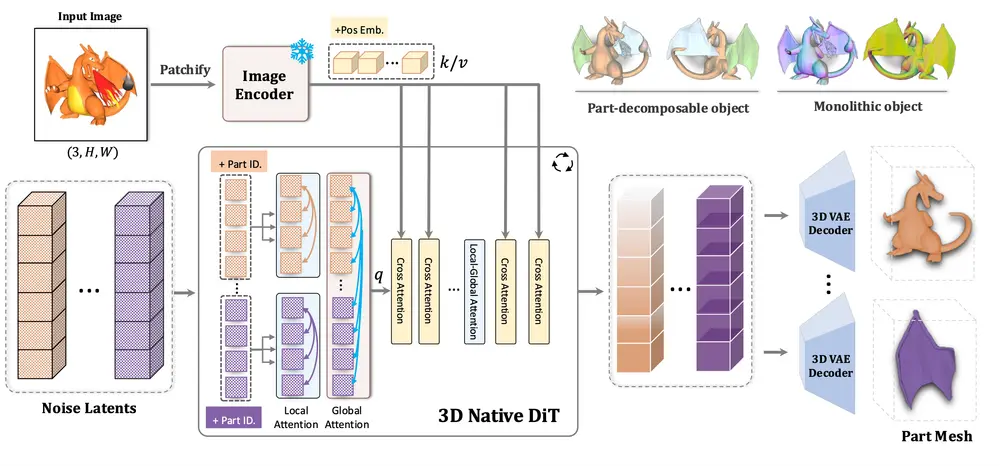
✅ 1. 组合式潜在空间(Compositional Latent Space)
每个 3D 部分由一组**解耦的潜在令牌(latent tokens)表示,并通过添加可学习的部件身份嵌入(part identity embeddings)**来区分不同部分。这种设计允许:
- 各个部件独立编辑、替换或组合;
- 支持更灵活的 3D 场景构建与修改。
✅ 2. 层次注意力机制(Hierarchical Attention Mechanism)
在生成过程中,PartCrafter 引入了两层注意力机制:
- 局部注意力:用于捕捉单个部件内部的细节特征;
- 全局注意力:用于建模部件之间的相互关系,确保整体结构的一致性。
这种机制使得模型在保留部件级别精细度的同时,仍能维持整体结构的合理性。
📦 数据集支持:50,000+ 带部件标注的 3D 对象
为了支持部件级别的监督训练,研究人员从大规模 3D 数据集中挖掘并整理了一个全新数据集,包含:
- 130,000 个 3D 对象
- 其中 100,000 个包含多个部件
- 最终筛选后保留 约 50,000 个带部件标签的对象
- 总计 300,000 个单独部件
该数据集经过纹理质量、部件数量及平均交并比(IoU)等指标筛选,确保训练数据的高质量与多样性。
🧪 实验表现:性能领先,生成质量显著提升
PartCrafter 在多个基准测试中展现出优于现有方法的表现:
| 模型 | Chamfer Distance | F-Score | IoU |
|---|---|---|---|
| HoloPart | 0.1916 | 0.6916 | 0.0443 |
| PartCrafter(本研究) | 0.1726 | 0.7472 | 0.0359 |
注:Chamfer Distance 越低越好;F-Score 和 IoU 越高越好。
在 Objaverse 和 3D-Front 数据集上,PartCrafter 表现出更强的生成质量和结构一致性,尤其在遮挡严重或多物体场景中依然保持稳定输出。
🎯 应用潜力:不只是生成,更是可编辑的 3D 创作平台
PartCrafter 的出现,不仅推动了 3D 生成的技术边界,也为多个行业带来新的可能性:
- 内容创作:设计师可通过图像快速生成带部件结构的 3D 模型,提升建模效率;
- 游戏开发:支持快速构建复杂场景中的多部件对象,如家具、机械装置等;
- 工业设计:便于对产品组件进行独立调整与迭代;
- 教育科研:提供一种全新的 3D 理解与生成范式,助力计算机视觉与图形学研究。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











