OmniLottie:全球首个端到端多模态矢量动画生成器,文字/图片/视频一键转可编辑 Lottie在数字设计领域,动画是灵魂,但高质量动画的制作门槛却高不可攀。现有的 AI 视频生成工具大多输出“死视频”(MP4/GIF)——无法放大、无法修改颜色、无法提取元素。而设计师钟爱的 Lottie 矢量...多模态模型# Lottie# OmniLottie# 矢量动画2周前0380
Helios:北大与字节联手打造 14B 实时长视频模型,单卡 19.5 FPS 刷新生成速度纪录在 AI 视频生成领域,长期存在一个“不可能三角”:生成速度快、视频时长长、画面质量高,三者往往难以兼得。主流模型要么只能生成几秒的短视频,要么需要数十分钟才能渲染出几秒钟的画面,且长视频极易出现人物...视频模型# Helios# 实时长视频模型2周前01320
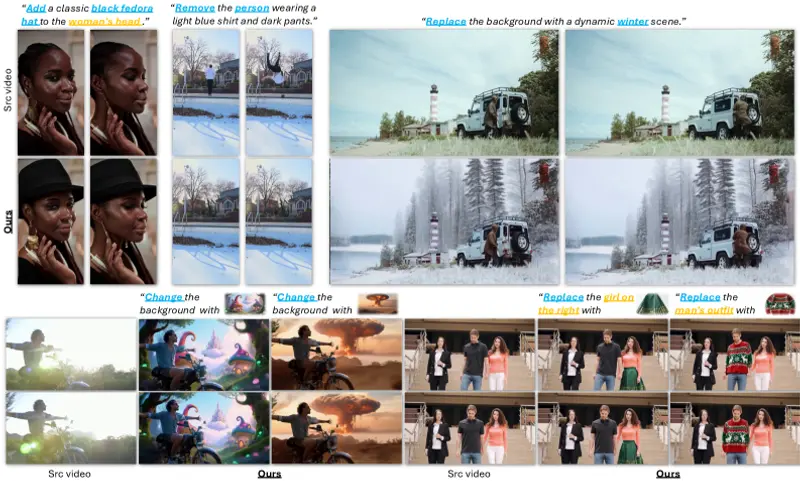
Kiwi-Edit:开源视频编辑新标杆,首创“指令 + 参考图”双模驱动,打破商业模型数据垄断在 AI 视频编辑领域,我们常面临一个尴尬境地:文字指令难以描述精确的视觉细节(如“把那辆车换成特定的红色法拉利”),而现有的参考图引导编辑又受限于高质量训练数据的极度匮乏。 Kiwi-Edit 是由...视频模型# Kiwi-Edit# 视频编辑2周前0270
Qwen3.5 小模型系列重磅发布:0.8B 至 9B 全覆盖,原生多模态与强化学习赋能边缘智能通义千问(Qwen)家族再添新成员!Qwen3.5 小模型系列今日正式发布,涵盖 0.8B、2B、4B、9B 四种参数量级。这一系列模型不仅继承了 Qwen3.5 大模型的强大基因,更在效率与性能的平...大语言模型# Qwen3.52周前0720
阿里通义发布 Fun-CosyVoice3.5 与 Fun-AudioGen-VD:自然语言指令即可实现“FreeStyle”语音与场景生成阿里通义实验室语音团队今日正式宣布,推出两款支持 FreeStyle 指令生成 的突破性模型:Fun-CosyVoice3.5 与 Fun-AudioGen-VD。 官方文档:https://help...语音模型# Fun-AudioGen-VD# Fun-CosyVoice3.5# 阿里通义2周前0300
ImageCritic:AI 绘图的“细节质检员”,专治 Logo 变形与文字乱码的通用后处理方案在 AI 绘画飞速发展的今天,我们早已习惯了让模型根据文字描述创造出惊艳的画面,甚至能将特定的商品、宠物或角色无缝植入新场景。然而,一个长期存在的“老大难”问题始终困扰着专业应用:细节一致性。 当你试...图像模型# ImageCritic# 图像编辑2周前0340
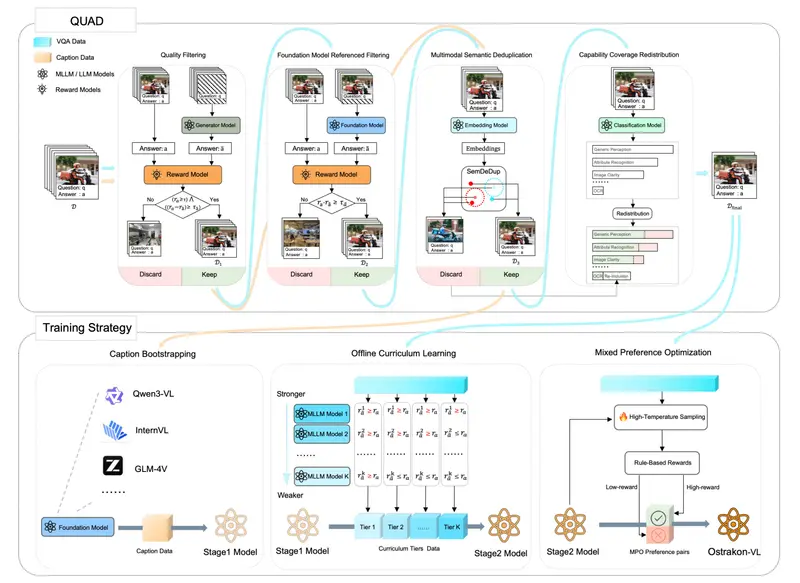
淘宝闪购开源“白泽”大模型Ostrakon-VL:基于 Qwen3-VL 打造餐饮风控神器,免费开放全行业使用在食品安全日益受到重视的今天,如何利用 AI 技术实现高效、精准的数字化治理,成为外卖平台与餐饮零售行业共同面临的挑战。今日,淘宝闪购正式宣布,将其专为餐饮服务与零售门店打造的风控治理垂直领域大模型...多模态模型# Ostrakon-VL# 淘宝闪购# 白泽2周前0250
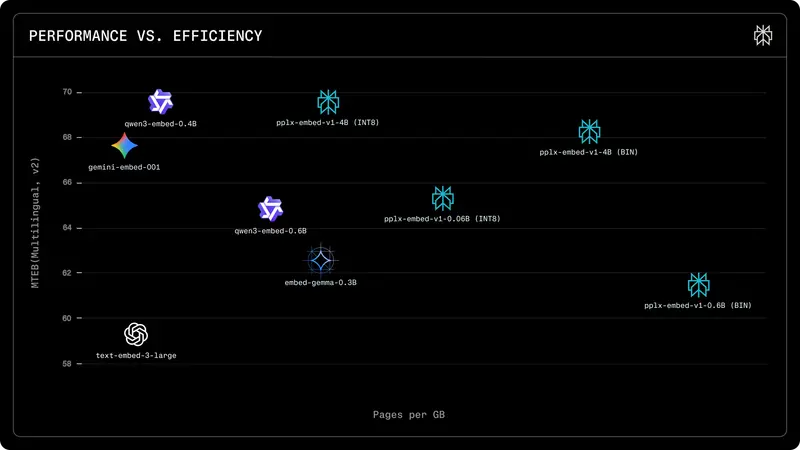
Perplexity 开源两款高性能嵌入模型:4B 参数支持二进制量化,检索效果超越 Gemini 与 Qwen在检索增强生成(RAG)和大规模语义搜索领域,嵌入模型(Embedding Model)的性能与成本往往难以兼得。今日,AI搜索引擎 Perplexity AI 发布了专为互联网规模检索任务打造的两款...大语言模型# Perplexity# pplx-embed-context-v1# pplx-embed-v12周前0220
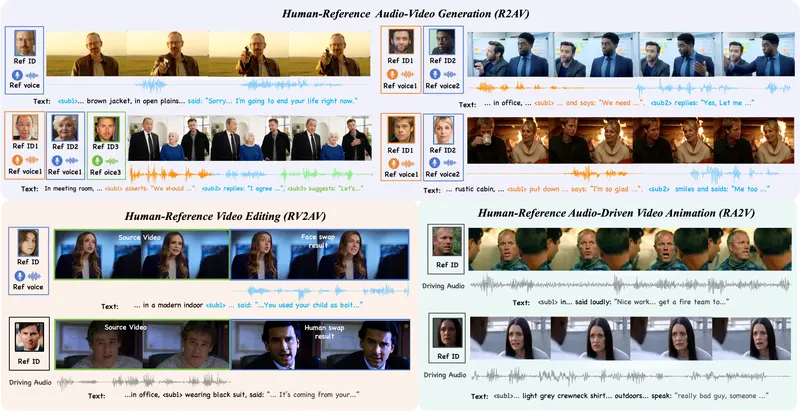
虚拟数字人项目DreamID-Omni:清华&字节联合发布统一框架,一人一模型搞定“换脸、变声、让照片说话”想象一下:你上传一张爱因斯坦的照片和一段录音,AI 就能生成他在办公室里发表演讲的完整视频,口型完美匹配,声音惟妙惟肖;或者,你想把电影片段中的主角换成自己,连声音也一并替换,动作表情却原汁原味。 这...视频模型# DreamID-Omni# 数字人3周前0750
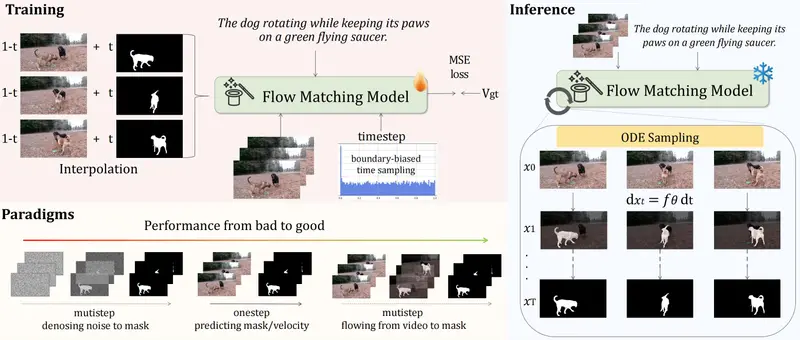
FlowRVS:颠覆“定位 - 分割”旧范式,用“视频变形”魔法实现指代视频对象分割新 SOTA想象这样一个场景:视频里有两只狗在玩耍,你对 AI 说:“帮我追踪那只正在跳的白色狗。”或者在一群人中,你指定:“锁定那个先骑自行车进画面的男人。” 这种用自然语言描述来指定视频中特定对象,并让 AI...视频模型# FlowRVS# 分割模型3周前0530
谷歌发布 Nano Banana 2:融合 Flash 速度与 Pro 级画质,角色一致性高达 5 人谷歌今日正式推出了其最新图像生成模型 Nano Banana 2(技术代号:Gemini 3.1 Flash Image)。这款新模型旨在打破“速度”与“质量”不可兼得的魔咒,将 Gemini Fla...图像模型早报# Gemini 3.1 Flash Image# Nano Banana 2# 谷歌3周前0430
Inception Labs 发布 Mercury 2:扩散式 LLM 打破自回归瓶颈,推理速度提升 10 倍在大型语言模型(LLM)领域,自回归(Autoregressive)架构长期占据主导地位,但其“逐字生成”的特性已成为高延迟场景的痛点。今日,Inception Labs 正式推出 Mercury 2...大语言模型# Inception Labs# Mercury 2# 扩散式 LLM3周前0360