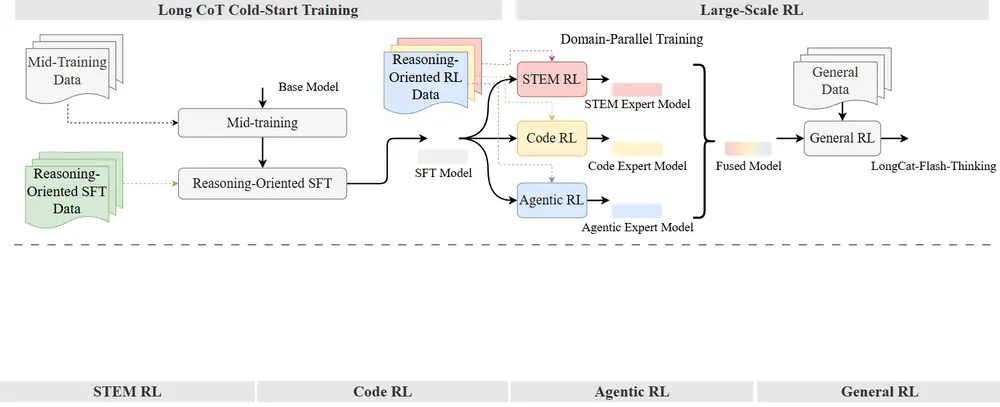
美团 LongCat 团队发布 LongCat-Flash-Thinking:具备形式化与智能体推理能力的新一代高效推理模型美团 LongCat 团队正式推出 LongCat-Flash-Thinking——一款专注于高复杂度任务推理的大型语言模型(LRM)。该模型在保持前代 LongCat-Flash-Chat 高效响应...大语言模型# LongCat-Flash-Thinking# 推理模型# 美团7个月前01920
Qianfan-VL:百度推出的多模态大模型系列,面向企业级视觉语言任务由百度 AI 云团队研发,Qianfan-VL 是一系列参数规模从 3B 到 70B 的多模态大语言模型(MLLM),专注于提升企业在文档理解、OCR识别和数学推理等高频场景下的自动化能力。 项目主页...多模态模型# Qianfan-VL# 多模态大模型# 百度7个月前01710
LatticeWorld:基于多模态指令的高效 3D 世界生成框架由网易、北京航空航天大学、清华大学与香港城市大学联合研究团队提出,LatticeWorld 是一个面向复杂 3D 虚拟环境自动生成的新框架。它通过融合轻量级大型语言模型(LLM)与工业级渲染引擎,探索...3D模型# LatticeWorld7个月前01310
Mini-Omni-Reasoner:将推理能力引入大型语音模型,让语音模型“边说边思考”由南洋理工大学、新加坡国立大学、腾讯、北京工业大学与北京航空航天大学联合研发,Mini-Omni-Reasoner 正式推出——这是一次将推理能力引入大型语音模型(Large Speech Model...语音模型# Mini-Omni-Reasoner# 语音思考模型7个月前03530
苹果发布多模态统一模型Manzano:能够同时理解和生成视觉内容苹果发布多模态统一模型Manzano,它能够同时理解和生成视觉内容。该模型通过结合一个混合图像标记化器和精心设计的训练方案,显著减少了在理解和生成能力之间的性能权衡。Manzano 在统一模型中实现了...多模态模型# Manzano# 多模态统一模型7个月前01120
视觉-语言模型中的“隐形损耗”:我们如何测量图像信息的丢失?视觉-语言模型(Vision-Language Models, VLMs)如 LLaVA、Qwen-VL 等,在图像理解、视觉问答和图文生成等任务中表现优异。这些模型通常依赖一个核心流程:将图像通过视...多模态模型# 视觉-语言模型7个月前01620
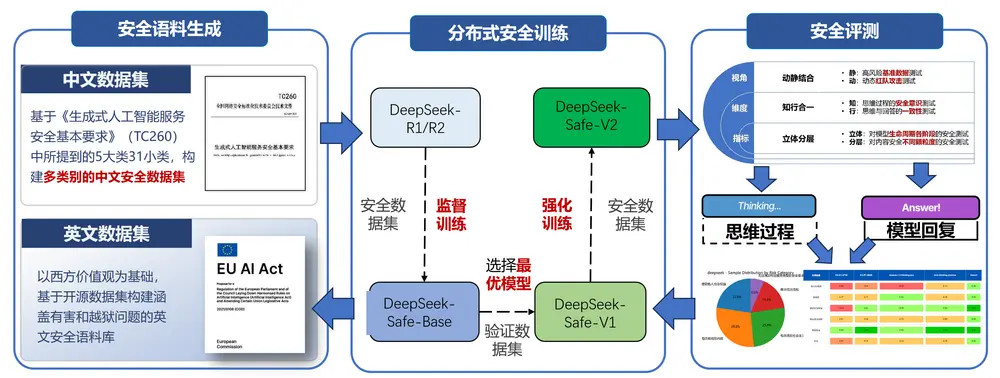
浙大×华为联合推出 DeepSeek-R1-Safe:基于昇腾的安全大模型浙江大学网络空间安全学院与华为合作,发布了一款基于 DeepSeek 模型架构 的安全增强型大语言模型 —— DeepSeek-R1-Safe。该模型依托华为昇腾(Ascend)AI 芯片及 Mind...大语言模型# DeepSeek-R1-Safe# 华为7个月前02970
百度发布 PP-OCRv5:0.07亿参数模型,挑战百亿级大模型的OCR精度在通用视觉语言模型(VLM)主导多模态任务的当下,百度飞桨团队反其道而行之,推出新一代轻量级文字识别模型 PP-OCRv5 ——一个仅含 70万参数(0.07B)的超小模型,在多项 OCR 任务中表现...多模态模型# PP-OCRv5# 百度7个月前03140
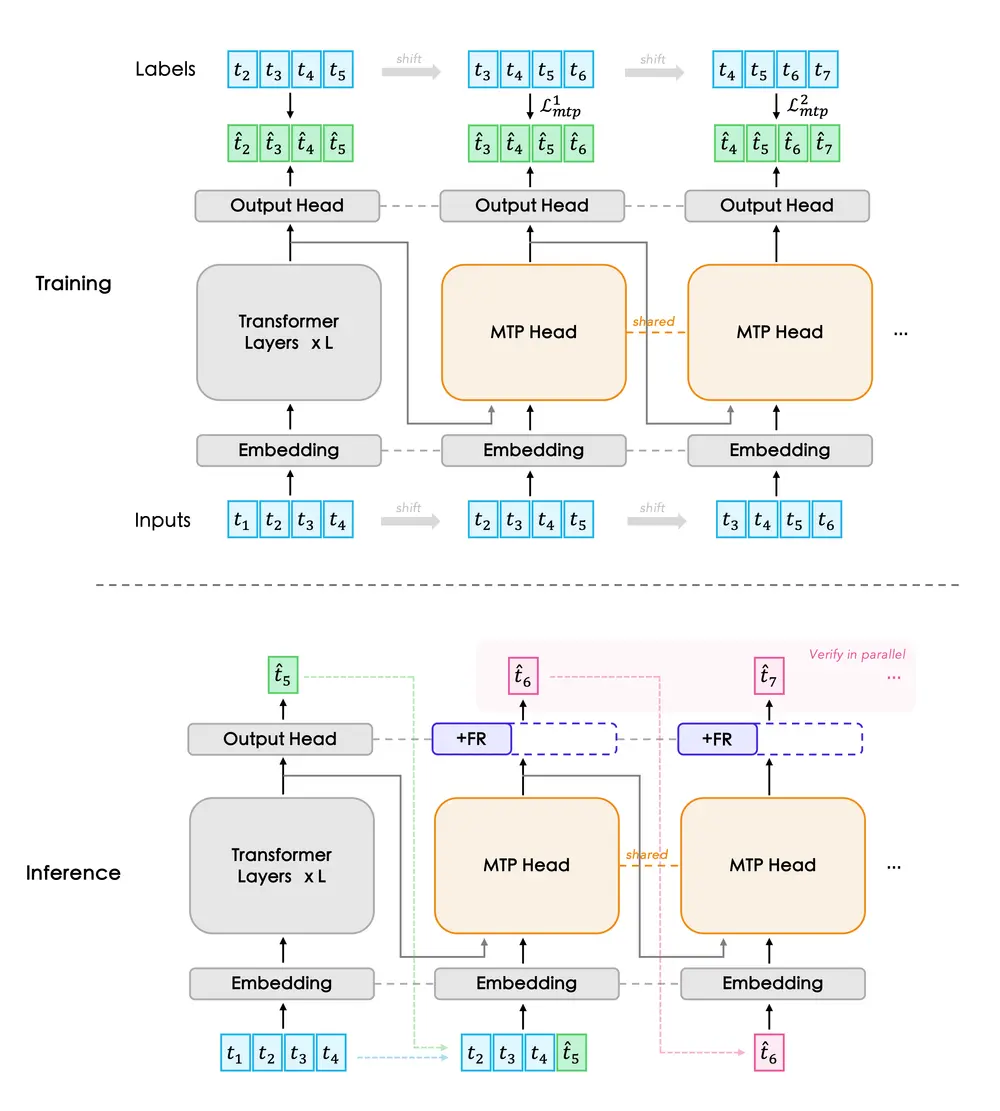
FastMTP:通过增强多令牌预测提升大模型推理效率在大语言模型(LLM)的实际应用中,推理速度是影响用户体验和部署成本的关键因素。尽管模型能力不断提升,但逐个生成 token 的方式带来了较高的延迟和计算开销。推测解码(Speculative Dec...大语言模型# FastMTP# 推理模型7个月前02010
Mistral AI 发布 Magistral Small 1.2:支持视觉输入的小型高效开源推理模型法国AI初创公司 Mistral AI 本周正式发布并开源其小型语言模型的新版本 —— Magistral Small 1.2。该模型在前代基础上全面升级,不仅提升了数学与编程任务的基准表现,还首次引...多模态模型# Magistral Small 1.2# Mistral AI7个月前02580
蚂蚁集团开源 Ring-flash-2.0:高效 MoE 架构下的高性能思考模型蚂蚁集团正式宣布开源 Ring-flash-2.0 ——一款基于 MoE(混合专家)架构的高性能“思考型”大语言模型。该模型总参数量达 100B,但在每次推理时仅激活 6.1B 参数(其中非嵌入部分约...大语言模型# Ring-flash-2.0# 蚂蚁集团7个月前02950
小米发布 MiMo-Audio:基于亿级小时预训练的开源音频语言模型小米近日正式推出 MiMo-Audio ——一个统一的生成式音频-语言模型,支持跨模态语音理解与生成任务。该模型通过超过一亿小时的大规模预训练,实现了强大的少样本学习能力,能够在无需微调的情况下,仅凭...语音模型# MiMo-Audio# 小米# 音频语言模型7个月前02450