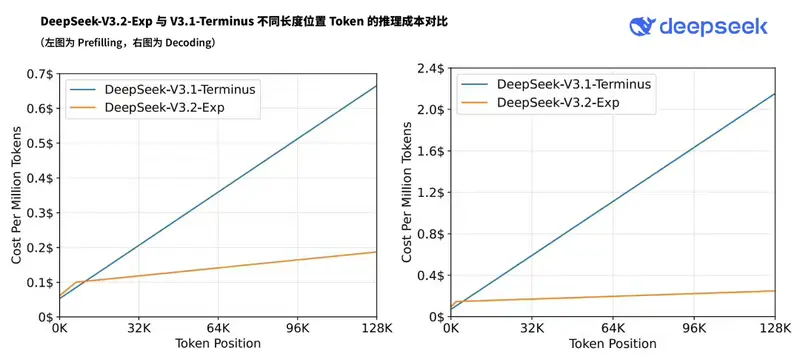
DeepSeek 发布DeepSeek-V3.2-Exp:首次引入细粒度稀疏注意力,API 成本直降 50%+在国庆节假期前夕,DeepSeek 正式推出 DeepSeek-V3.2-Exp ——一个面向未来架构演进的实验性(Experimental)版本。该模型并非最终发布版,而是通向新一代高效架构的关键中...大语言模型# DeepSeek# DeepSeek-V3.2-Exp6个月前02010
腾讯混元发布 HunyuanImage-3.0:800亿参数开源原生多模态模型,实现“语义理解-图像生成”的深度融合腾讯混元项目组正式发布并开源HunyuanImage-3.0——当前开源社区规模最大、性能最强的文生图模型。该模型总参数量突破800亿,推理时每token仅激活130亿参数(兼顾性能与效率),基于原生...图像模型# HunyuanImage-3.0# 腾讯混元6个月前07810
腾讯混元推出 Hunyuan3D-Omni:统一框架实现多模态可控 3D 生成腾讯混元项目组近日发布 Hunyuan3D-Omni ——一个面向 3D 资产生成的统一框架,解决传统单图生成 3D 模型时存在的几何失真、姿态不可控等问题。 地址:https://3d.hunyua...3D模型# Hunyuan3D-Omni# 腾讯混元6个月前02230
Stability AI 推出 SD3.5-Flash:让高质量图像生成在消费级设备上实现秒级输出Stability AI 近日发布 SD3.5-Flash ——一个全新的少步蒸馏(few-step distillation)图像生成模型,解决当前生成式 AI 模型在普通硬件上运行困难的核心痛点...图像模型# SD3.5-Flash# Stability AI6个月前04290
谷歌发布推出改进的 Gemini 2.5 Flash 和 Flash-Lite 版本:响应更快、成本更低、智能更强谷歌今日推出 Gemini 2.5 Flash 和 Gemini 2.5 Flash-Lite 的预览更新版本,已在 Google AI Studio 与 Vertex AI 平台上线。此次升级聚焦于...大语言模型# Gemini 2.5 Flash# Gemini 2.5 Flash-Lite# 谷歌6个月前02850
英伟达等提出 Lyra:基于自蒸馏的单图生成3D/4D场景新框架从游戏开发到机器人仿真,构建高质量虚拟环境的能力至关重要。然而,传统3D重建依赖多视角真实数据采集,成本高且难以规模化;而当前强大的视频扩散模型虽具备出色“想象力”,却受限于2D输出,无法满足需要空间...3D模型# Lyra7个月前03970
字节跳动发布统一加速多模态理解与生成的新框架Hyper-Bagel随着多模态大模型在图文理解、文本到图像生成、图像编辑等任务中表现日益强大,其高昂的推理成本也逐渐成为落地瓶颈。传统的自回归解码与扩散去噪过程需要大量迭代计算,在长上下文或多轮交互场景下响应迟缓。 为此...图像模型# Hyper-Bagel# 字节跳动7个月前03250
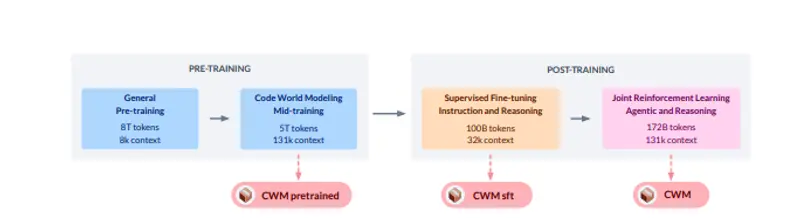
Meta 开源代码世界模型CWM:让AI像程序员一样"推演"代码的世界模型Meta近日发布并开源代码世界模型(Code World Model, CWM),这是一款320亿参数的仅解码器大型语言模型(LLM),支持最长131k tokens的上下文长度。不同于传统代码模型仅...大语言模型# CWM# Meta# 代码世界模型7个月前02380
通义万相 Wan2.5-Preview 正式发布:原生支持音画同步的多模态视觉生成引擎阿里通义实验室Wan项目组正式推出 Wan2.5-Preview——一个在架构层面实现革新、真正实现“音视频协同生成”的新一代视觉大模型。 它不是简单的功能叠加,而是通过原生多模态统一架构,将文本、图...视频模型# Wan2.5-Preview7个月前01430
Qwen3-Max 发布:阿里通义迄今最强语言模型,已开放 API在 Qwen3-2507 系列全面上线后,阿里通义实验室正式推出 Qwen3-Max——迄今为止参数规模最大、综合能力最强的 Qwen 模型。 作为 Qwen3 系列的旗舰型号,Qwen3-Max 不...大语言模型# Qwen3-Max7个月前04460
阿里发布Qwen3-LiveTranslate-Flash :全球首个视、听、说全模态实时同传大模型阿里通义实验室今日推出 Qwen3-LiveTranslate-Flash——一款基于 Qwen3-Omni 基座模型打造的多语言实时音视频同声传译大模型。 Demo:https://huggingf...语音模型# Qwen3-LiveTranslate-Flash# 实时同传大模型7个月前08630
阿里通义实验室发布 Qwen3-VL:迄今最强视觉语言模型,全面开源阿里通义实验室 Qwen 项目组正式推出全新升级的 Qwen3-VL 系列——这是截至目前 Qwen 多模态体系中能力最全面、性能最先进的视觉语言模型(Vision-Language Model, V...多模态模型# Qwen3-VL# 视觉语言模型7个月前04430