
腾讯混元项目组近日发布 Hunyuan3D-Omni ——一个面向 3D 资产生成的统一框架,解决传统单图生成 3D 模型时存在的几何失真、姿态不可控等问题。
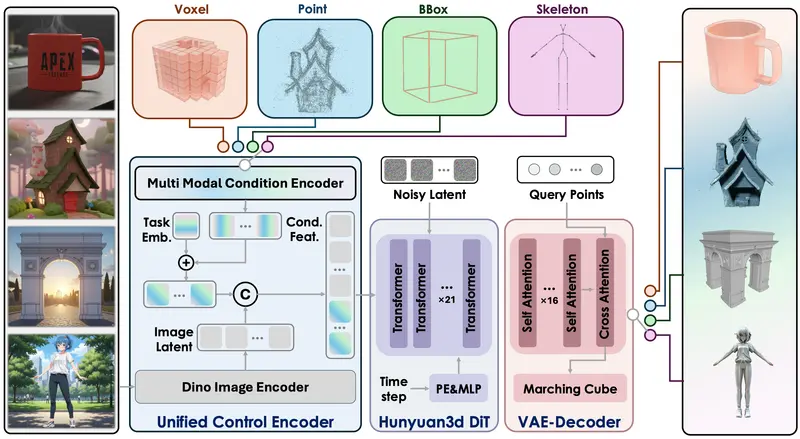
该模型基于此前发布的 Hunyuan3D 2.1 架构升级而来,核心创新在于引入了一个统一控制编码器(Unified Control Encoder),支持融合多种条件信号,包括点云、体素、边界框和骨骼姿态,从而实现对生成结果的细粒度、高精度控制。

这一进展为游戏开发、影视制作、工业设计等需要高质量 3D 内容的领域提供了更高效、更灵活的生成方案。
模型库
生成需要10GB显存。
| 模型 | 描述 | 日期 | 大小 | Huggingface |
|---|---|---|---|---|
| Hunyuan3D-Omni | 具有多模态控制的图像转形状模型 | 2025-09-25 | 3.3B | 下载 |
多模态条件控制:从“能生成”到“可控制”
传统 3D 生成模型通常仅依赖单张图像作为输入,导致输出结果在比例、结构或姿态上常有偏差。Hunyuan3D-Omni 则通过多模态引导,让创作者可以精确干预生成过程:
| 控制方式 | 功能说明 |
|---|---|
| 边界框控制 | 约束生成物体的整体尺寸与空间比例,确保符合物理规格 |
| 姿态控制 | 输入骨骼姿态,将静态角色调整为指定动作,适用于动画预览 |
| 点云控制 | 基于稀疏点云数据重建完整 3D 形状,适合扫描后修复与补全 |
| 体素控制 | 从低分辨率体素网格出发,生成高保真 3D 模型,便于草图转资产 |
例如,设计师只需上传一张角色图片并附加一组骨骼信息,即可生成一个处于奔跑状态的 3D 模型;或通过调整边界框,快速生成不同尺寸的家具变体。
核心功能亮点
- ✅ 多模态融合:在一个框架内处理图像、点云、体素、骨架等多种输入;
- ✅ 高精度几何生成:相比纯图像驱动方法,显著提升拓扑正确性与细节还原度;
- ✅ 风格化与姿态编辑:支持对生成结果进行艺术化处理与动态姿态调整;
- ✅ 跨模态协同:多种控制信号可组合使用,如“图像 + 姿态 + 边界框”,实现复合约束下的精准生成。
技术架构解析
Hunyuan3D-Omni 基于 3D 变分自编码器(VAE) 和 3D 潜在扩散模型(LDM) 构建,其工作流程如下:
- 3D 表示压缩
使用 3D VAE 将原始点云压缩为紧凑的离散表示 VecSet,降低计算复杂度。 - 统一编码器融合条件信号
设计轻量级统一控制编码器,将不同模态的控制信号(如骨骼、体素)编码为统一特征向量,避免为每种模态单独设计网络头,提升训练效率。 - 联合特征注入
将控制特征与图像的 DINO 视觉特征拼接,共同指导扩散模型去噪过程。 - 解码与重建
解码器从 VecSet 恢复出符号距离函数(SDF)场,再通过等值面采样(如 Marching Cubes)生成最终 3D 网格。
此外,团队采用渐进式、难度感知的训练策略,优先训练更具挑战性的任务(如姿态控制),逐步提升模型对复杂输入的鲁棒性。
实测表现:精度与鲁棒性双提升
根据官方测试结果,Hunyuan3D-Omni 在多个维度优于基线模型:
- 几何精度更高:在点云和体素引导下,生成模型的形状误差显著降低;
- 姿态对齐准确:人体模型能紧密贴合输入骨骼,动作自然;
- 抗噪能力强:即使输入存在缺失或噪声,仍能生成完整合理的 3D 结果;
- 多信号协同有效:组合使用多种控制信号时,生成质量与多样性均优于单一条件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











