从游戏开发到机器人仿真,构建高质量虚拟环境的能力至关重要。然而,传统3D重建依赖多视角真实数据采集,成本高且难以规模化;而当前强大的视频扩散模型虽具备出色“想象力”,却受限于2D输出,无法满足需要空间交互的应用需求。
为此,来自 英伟达、多伦多大学、矢量研究所(Vector Institute)和西蒙弗雷泽大学 的研究人员联合提出 Lyra ——一种新型3D与4D场景生成框架,能够仅从单张图像或单目视频中生成显式的3D高斯点云(3D Gaussian Splatting, 3DGS)表示,支持实时渲染与动态交互。
该方法无需任何真实世界的多视角训练数据,通过“自蒸馏”机制,将预训练视频扩散模型中的隐式3D知识转化为可渲染的显式几何结构。

核心思想:用AI教AI理解三维世界
Lyra 的核心在于知识迁移:利用一个已经掌握丰富视觉-运动规律的视频扩散模型作为“教师”,指导另一个网络学习如何生成对应的3D结构。
具体来说:
- 教师模型是预训练的相机控制视频扩散模型(如 GEN3C),能根据指定相机轨迹生成连贯的多视角视频;
- 学生模型是一个新增的 3DGS 解码器,目标是从相同潜在空间直接解码出3D高斯点云;
- 训练过程中,冻结教师模型,仅训练3DGS解码器,并使其渲染结果与教师生成的RGB画面对齐。
这一过程称为“自蒸馏”——即同一系统内部的知识转移,避免了对真实3D标注或同步多视角数据的依赖。
技术实现:如何让2D模型教会3D生成?
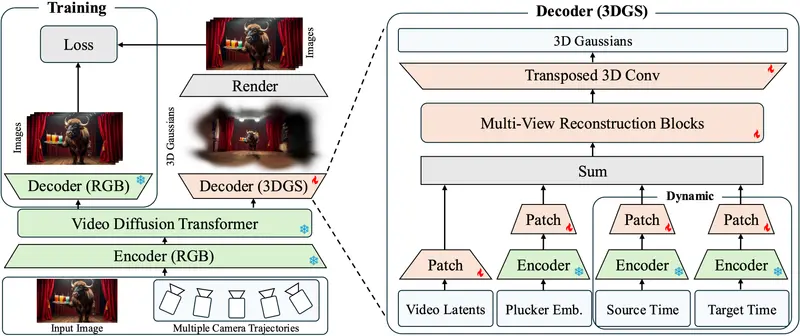
1. 双分支架构设计
在训练阶段,模型包含两个解码通路:
- RGB 解码器(已冻结):生成标准2D视频帧;
- 3DGS 解码器(待训练):输出显式3D高斯分布集合。
通过最小化3DGS渲染图像与RGB输出之间的差异(如L1、SSIM、LPIPS损失),迫使3D结构逼近真实视图一致性。
2. 多轨迹监督提升泛化能力
为扩大视角覆盖并减少几何畸变,Lyra 在训练时采样多个虚拟相机轨迹,生成多样化的观察序列,增强学生模型对不同视角组合的理解能力。
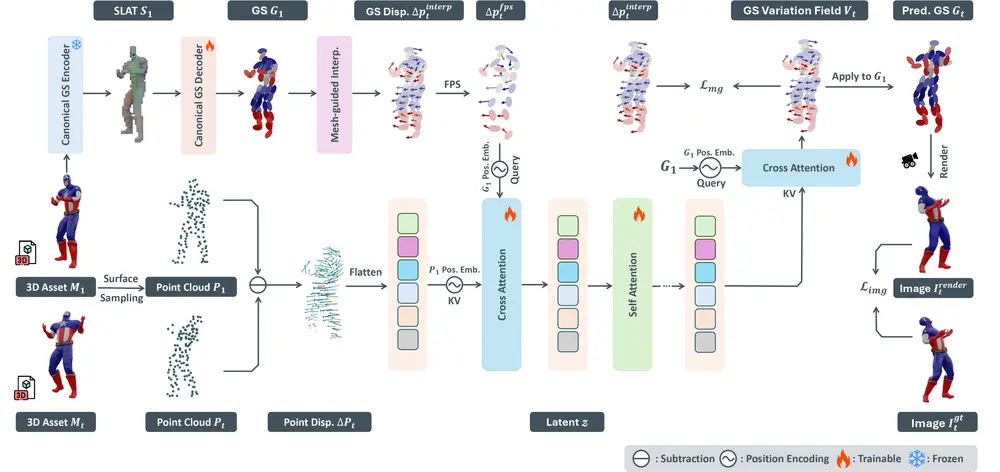
3. 动态扩展至4D:时间维度建模
对于视频输入,Lyra 进一步扩展至动态3D场景生成(即4D,含时间轴)。其关键改进包括:
- 引入动态数据增强策略:反转输入视频帧序,生成额外监督信号;
- 确保每个时间步都被充分建模,防止早期帧出现低不透明度伪影;
- 输出随时间演化的3DGS状态序列,支持回放、暂停与视角切换。
推理流程:从输入到实时渲染
推理阶段完全脱离教师模型,仅使用训练好的3DGS解码器:
- 输入:一张图像 或 一段单目视频;
- 模型推断:生成对应的3D高斯点云(静态)或带时间索引的动态点云序列(4D);
- 渲染:使用原生3DGS渲染器实现实时可视化,支持自由视角漫游与交互。
整个过程前馈完成,无迭代优化,适合部署于模拟、AR/VR等低延迟场景。
性能表现:超越现有方法
实验表明,Lyra 在多个基准上达到最先进水平:
| 数据集 | 指标 | Lyra 表现 |
|---|---|---|
| RealEstate10K (静态) | PSNR / SSIM / LPIPS | 21.79 / 0.752 / 0.219 |
| Tanks-and-Temples (静态) | 均优于NeRF、3DGS基线方法 | ✅ |
| Lyra 自建动态数据集 | PSNR / SSIM / LPIPS | 23.07 / 0.779 / 0.231 |
相比直接使用 GEN3C 生成视频再尝试逆向重建的方法(如 BTimer),Lyra 显著提升了空间一致性和细节保真度。
消融实验也验证了以下设计的有效性:
- 深度损失:防止生成扁平化几何;
- 不透明度剪枝:提升渲染效率,降低冗余点数量;
- 多视图融合机制:缓解长期一致性问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...