阿里发布 Omni-Effects:首个支持空间可控复合特效生成的统一框架在现代电影与视频制作中,视觉特效(VFX)是实现创意表达的核心工具。然而,传统 VFX 制作成本高昂、周期长,依赖专业团队和复杂软件。 近年来,AI 视频生成模型为 VFX 提供了更具成本效益的替代方...视频模型# Omni-Effects# 视觉特效4个月前01970
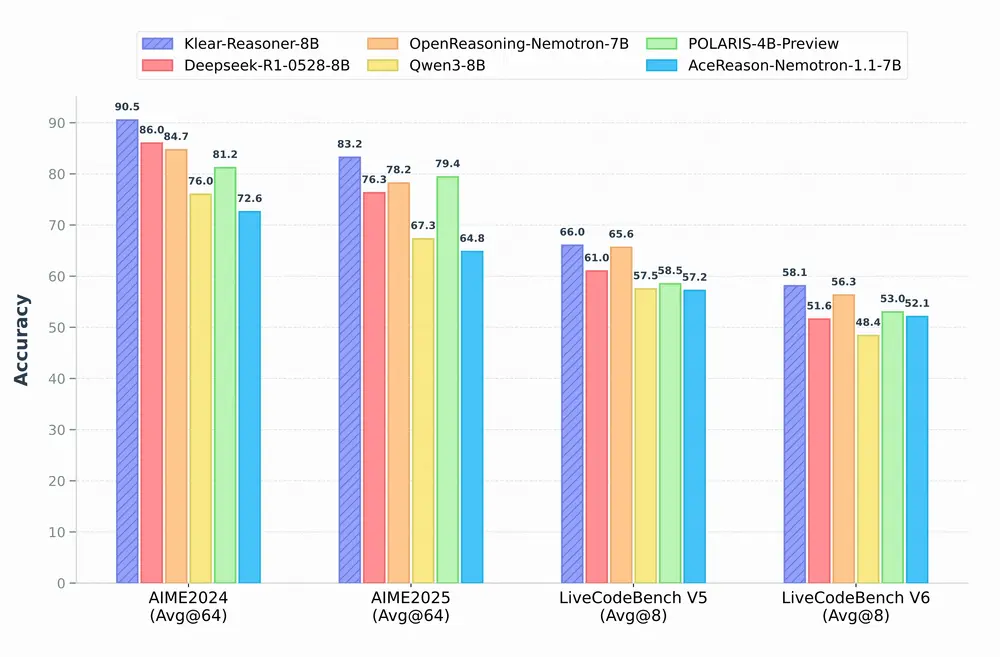
快手Klear项目组推出推理模型 Klear-Reasoner:结合长链推理监督微调和梯度保留剪辑策略优化来提升模型在数学和编程任务中的推理能力快手Klear项目组推出推理模型 Klear-Reasoner,它通过结合长链推理(Long Chain-of-Thought, Long CoT)监督微调和梯度保留剪辑策略优化(Gradient-P...大语言模型# Klear-Reasoner# 快手4个月前01730
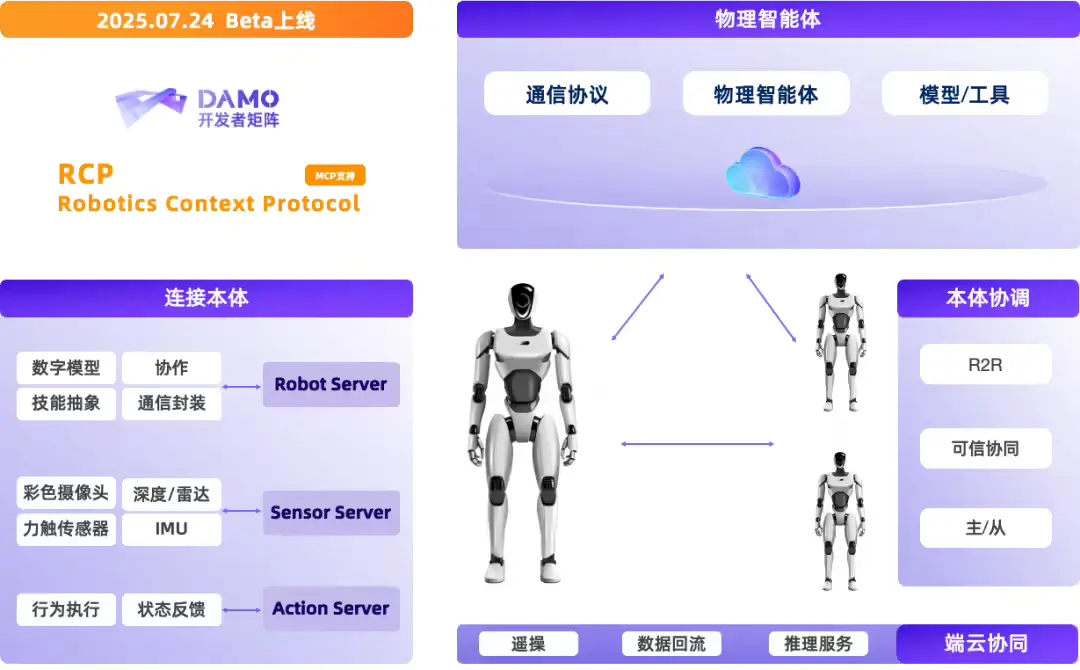
阿里达摩院开源 Rynn 系列:从协议到模型,打通具身智能“最后一公里”在上周开幕的 2025 世界机器人大会上,阿里达摩院宣布开源一套完整的具身智能技术体系,包括: 视觉-语言-动作模型 RynnVLA-001-7B 世界理解模型 RynnEC 机器人上下文协议 Ryn...多模态模型# RynnEC# RynnRCP# RynnVLA-001-7B4个月前02930
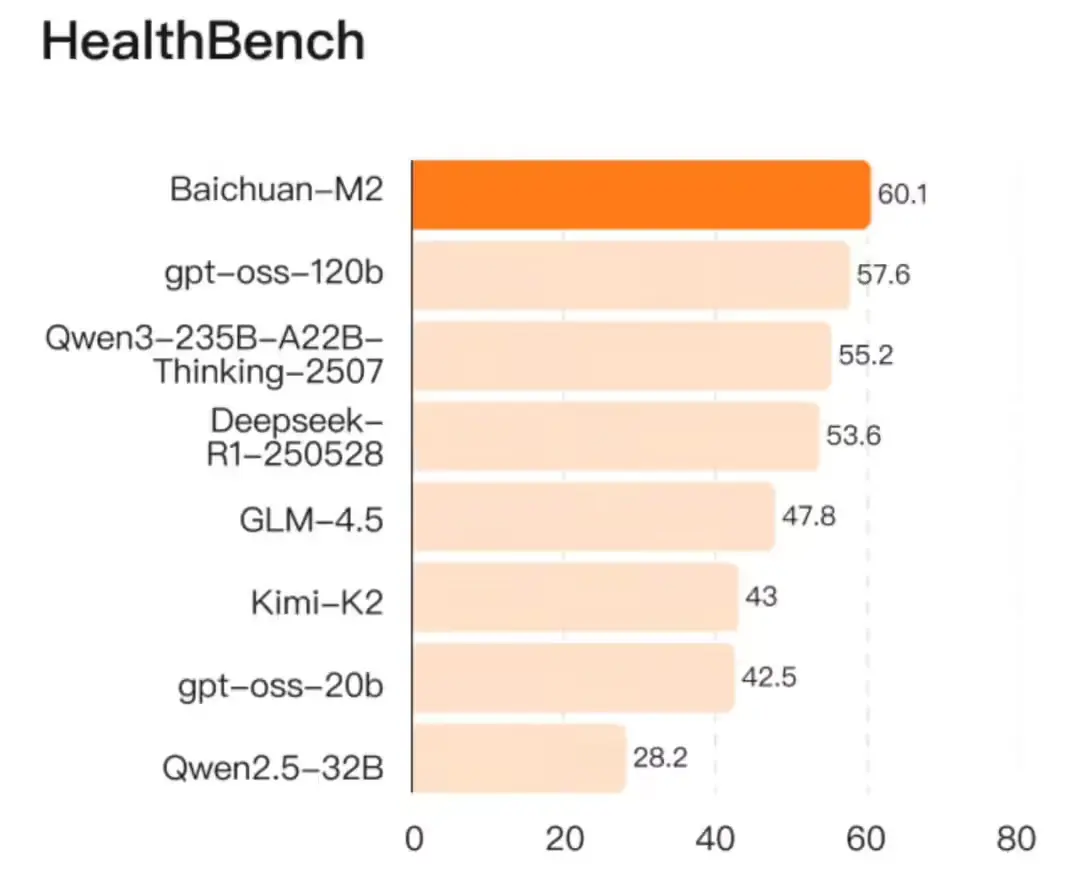
百川智能发布 Baichuan-M2:小模型,大医疗,单卡可部署的开源医疗大模型8 月 6 日,OpenAI 开源两款大模型,主打“低成本部署”与“医疗能力突破”。仅仅五天后,百川智能推出 Baichuan-M2 ——一款在更小参数规模下实现医疗能力反超的开源模型。 模型:htt...大语言模型# Baichuan-M2# 医疗大模型# 百川智能4个月前05330
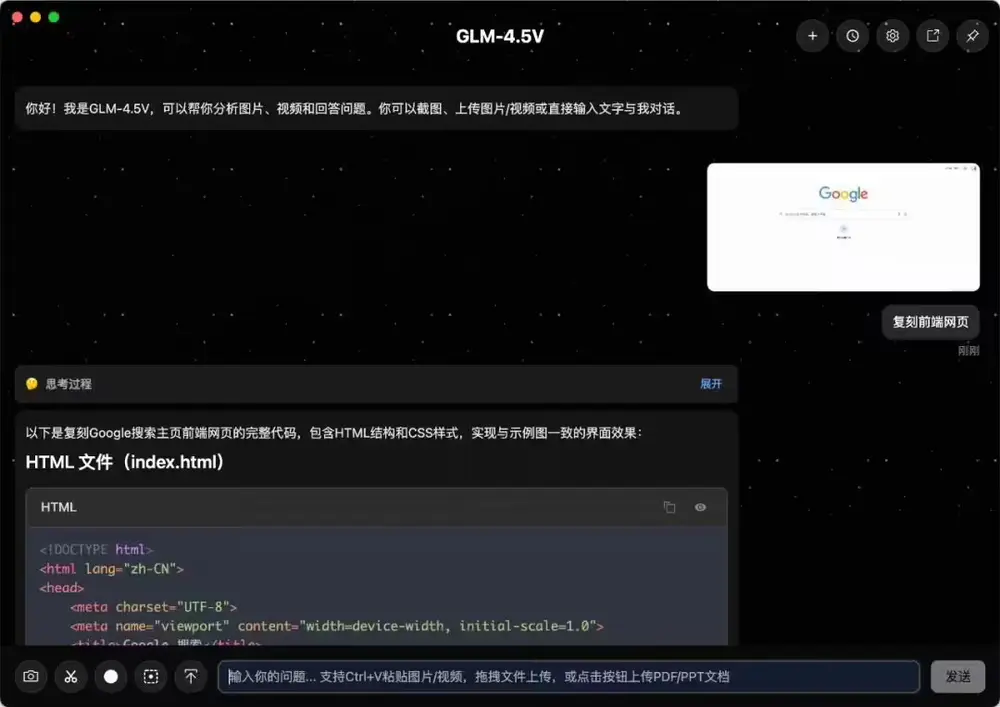
智谱AI发布GLM-4.5V:106B参数的开源视觉推理模型,支持“思考模式”切换今日,智谱 AI 正式推出其新一代开源视觉语言模型 GLM-4.5V,并在魔搭社区与 Hugging Face 同步开源。该模型总参数达 106B,采用 MOE(Mixture of Experts...多模态模型# GLM-4.5V# 智谱AI4个月前01510
LIA-X:一种可解释的肖像动画方法,让面部动作“看得见、控得住”上海人工智能实验室和蔚蓝海岸大学的研究人员推出一种新颖的可解释肖像动画器LIA-X,旨在将驱动视频中的面部动态转移到源肖像上,并实现精细控制。 项目主页:https://wyhsirius.githu...视频模型# LIA-X# 肖像动画4个月前02700
EchoMimicV3:用一个13亿参数模型,统一处理音频、文本、图像驱动的人体动画你是否想象过这样的场景? 输入一段语音,AI 自动生成人物说话的视频,唇形精准对齐,表情自然生动; 给一张静态肖像,加上一句“他开始微笑并挥手”,画面立刻动起来; 结合提示词和参考图,生成一段人物动作...视频模型# EchoMimicV3# 人体动画4个月前01970
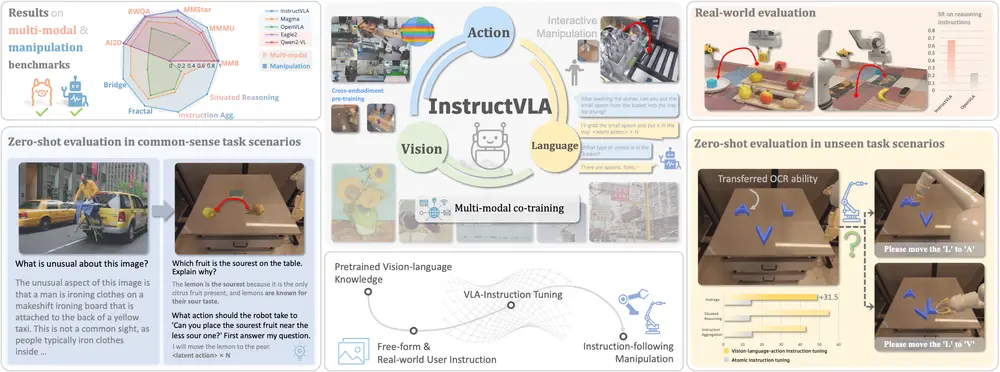
端到端的 VLA 模型InstructVLA:让机器人真正“听懂”指令并准确执行要让机器人走进真实世界,完成诸如“把苹果放进桌上的红碗”这样的任务,仅靠预设程序远远不够。它必须具备两项关键能力: 理解复杂语义——分辨“红碗”是颜色还是材质?“桌上”是否包含边缘? 生成精确动作...多模态模型# InstructVLA# VLA 模型4个月前01830
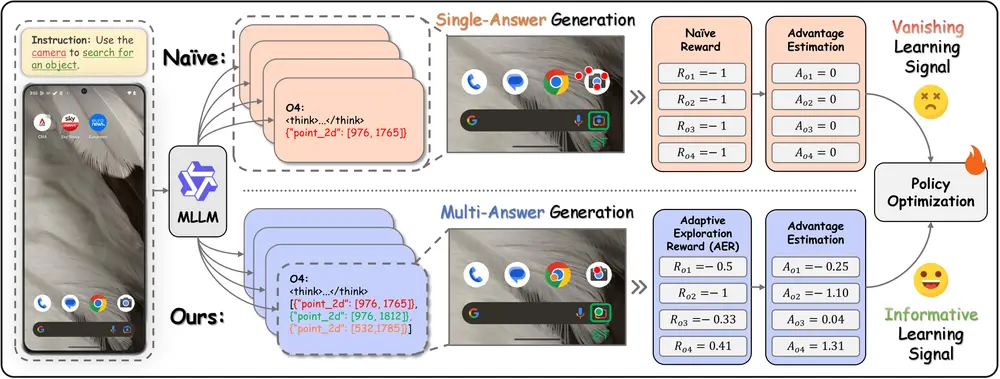
让大模型真正“看懂”界面:InfiGUI-G1提升 GUI 操作中的语义理解能力在图形用户界面(GUI)自动化任务中,让多模态大语言模型(MLLM)准确执行自然语言指令,远不只是“点击坐标”那么简单。真正的挑战在于:既要精准定位界面上的元素(空间对齐),又要正确理解指令背后的意图...多模态模型# InfiGUI-G14个月前01720
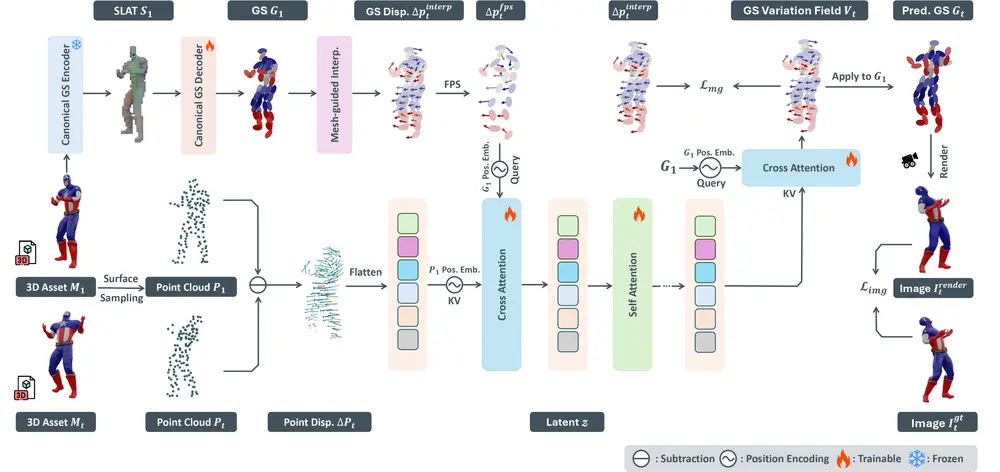
中科大&微软提出GVFDiffusion:从单个视频生成动态3D,实现高效4D生成你有没有想过: 仅凭一段手机拍摄的旋转物体视频,就能重建出一个可自由操控、动态连贯的3D模型? 这不是特效,而是AI正在实现的能力。 中国科学技术大学与微软的研究团队近日提出 GVFDiffusion...3D模型# GVFDiffusion4个月前01250
图像质量评估体系HPSv3:用“人类偏好”重新定义图像生成质量评估当AI画出一张“森林中休息的鹿”,我们如何判断它画得好不好? 是看它是否包含“鹿”和“树木”?还是看光影是否自然、构图是否美观、整体是否令人愉悦?显然,后者更贴近人类的真实审美。然而,当前大多数文本到...图像模型# HPSv3# 图像质量评估体系4个月前03400
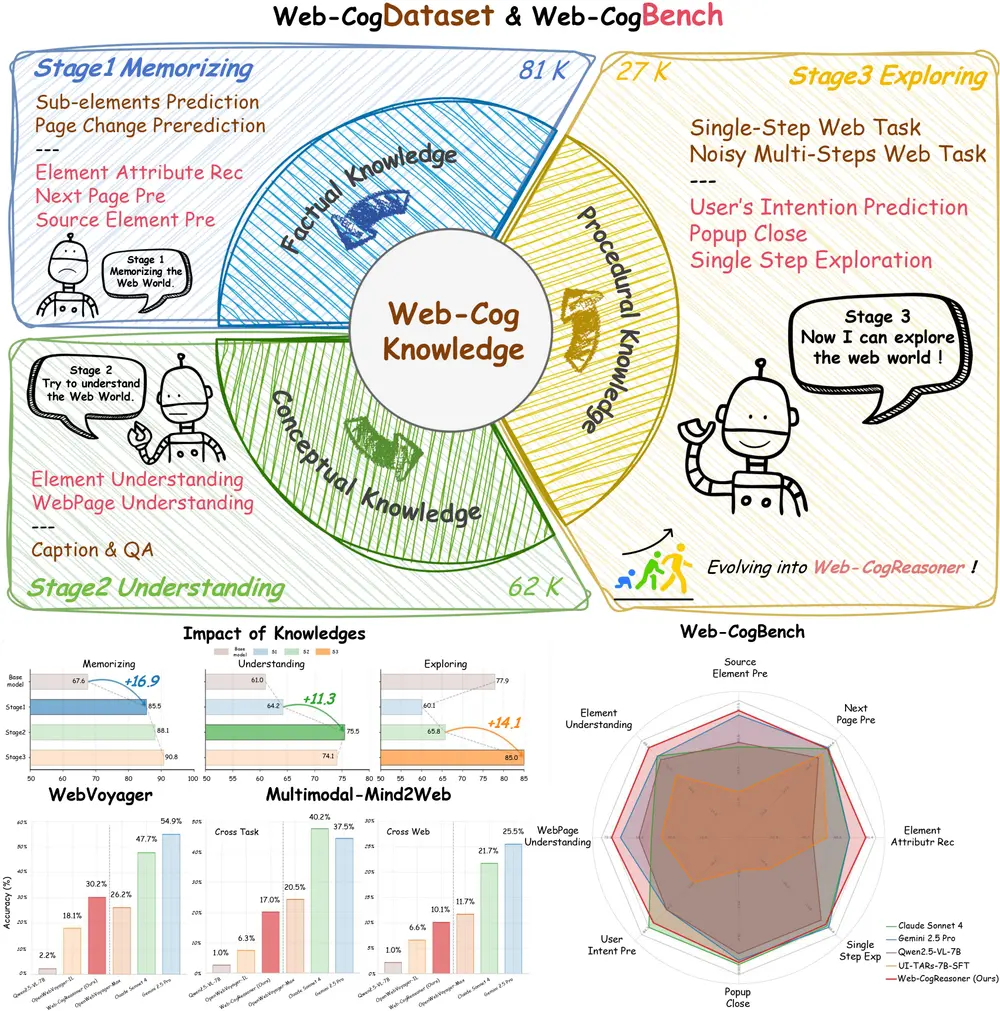
多模态智能体的“认知升级”:Web-CogReasoner 如何让网络代理真正“会思考”联合研究团队:西南财经大学、上海交通大学、中南大学、Hithink研究院、西湖大学、哈尔滨工业大学、曼彻斯特大学、加州大学洛杉矶分校、阿德莱德大学、复旦大学、中国科学院深圳先进技术研究院 当AI开始替...多模态模型# Web-CogReasoner# 多模态智能体4个月前01250