你有没有想过: 仅凭一段手机拍摄的旋转物体视频,就能重建出一个可自由操控、动态连贯的3D模型?
这不是特效,而是AI正在实现的能力。
中国科学技术大学与微软的研究团队近日提出 GVFDiffusion,一种全新的视频到4D生成框架,能够从单一视频输入中,直接生成高质量、时间连续的动态3D内容(即4D:3D空间 + 时间)。
这项工作突破了传统4D建模在数据成本和表示复杂性上的瓶颈,为动画制作、虚拟现实、数字人等领域提供了更高效、更具泛化能力的生成路径。
挑战:为什么4D生成如此困难?
4D生成的目标是:从2D视频中恢复一个随时间演化的3D对象——不仅要准确还原其几何形状和外观,还要保证运动过程的自然与连贯。
然而,这一任务面临两大核心难题:
- 数据构建成本高
真实世界的4D数据(如动态3D扫描)采集困难、设备昂贵,难以大规模获取。 - 表示维度高、建模复杂
同时建模3D形状、纹理和运动轨迹,参数空间巨大,直接进行端到端扩散建模极易导致训练不稳定或过拟合。
现有方法通常依赖逐实例拟合或静态3D先验,效率低且泛化弱。
解决方案:GVFDiffusion 的三大创新
GVFDiffusion 通过“高效表示 + 条件扩散”的两阶段策略,系统性地解决了上述问题。
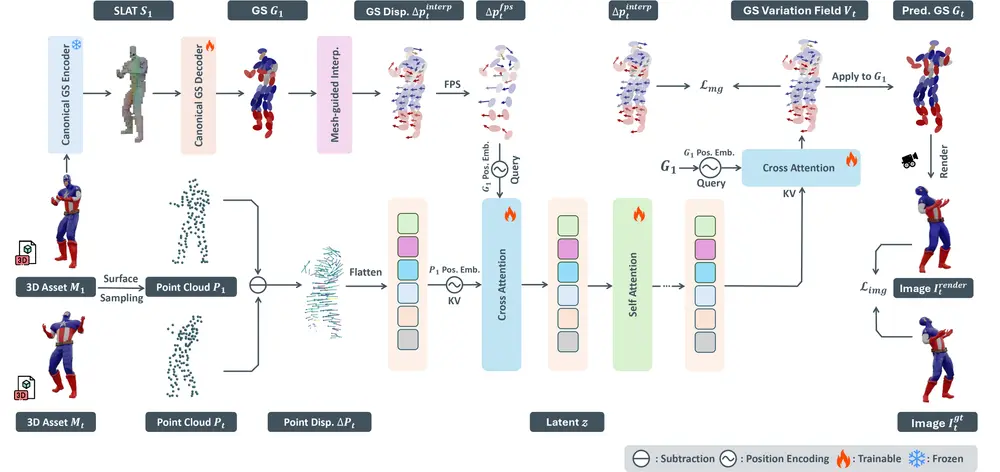
1. Direct 4DMesh-to-GS Variation Field VAE
——将4D动画压缩进紧凑潜在空间
这是整个框架的基础模块。它不依赖逐帧3D重建,而是直接将3D动画序列编码为 高斯变化场(Gaussian Variation Fields)。
核心思想:
- 使用 高斯斑点(Gaussian Splats, GS) 作为3D表示形式,避免显式网格变形带来的计算开销;
- 将每个时刻的GS状态及其变化趋势统一编码为一个时间感知的潜在向量;
- 通过变分自编码器(VAE),将高维动画压缩至仅 512维的紧凑潜在空间。
训练优化:
- 图像级重建损失:确保生成视角与原渲染图像一致;
- 网格引导损失(Mesh-Guided Loss):引入轻量级几何约束,提升形状保真度。
✅ 效果:无需逐实例拟合,即可实现跨对象的动画特征提取与压缩。
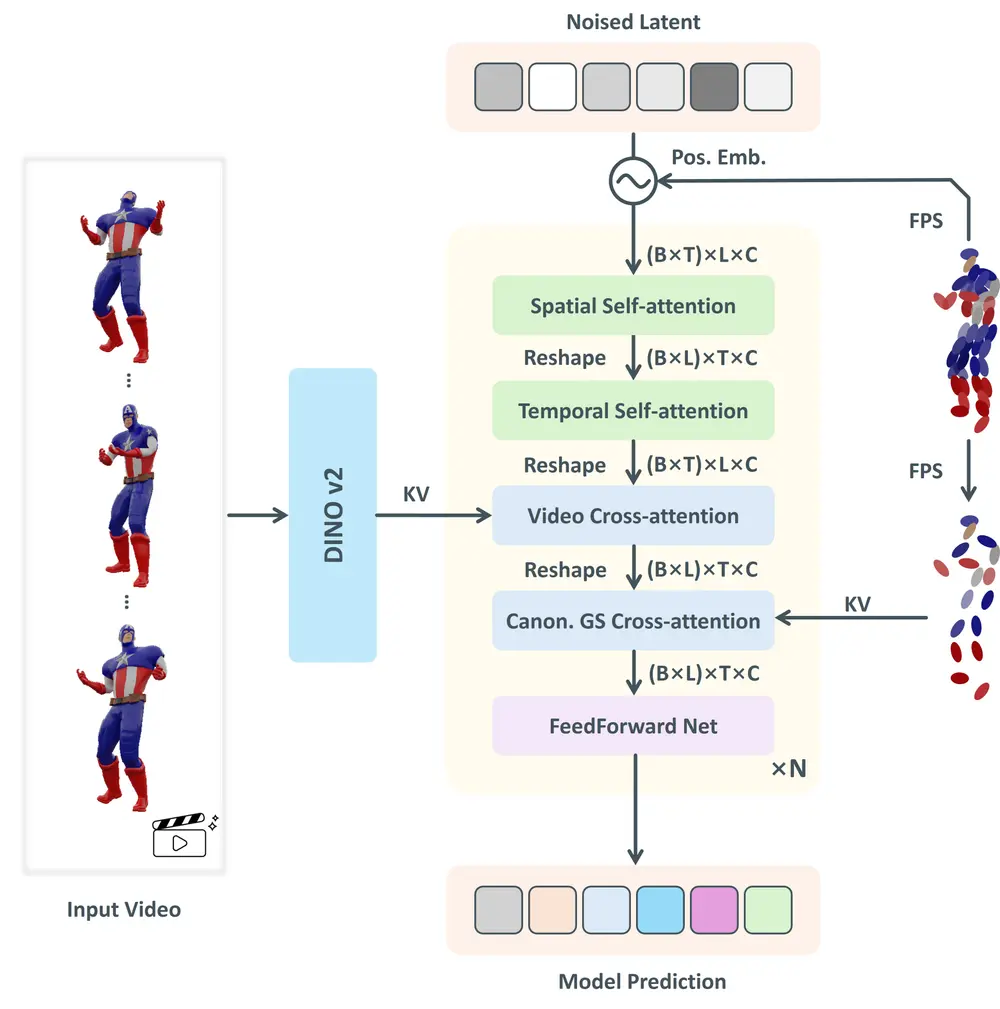
2. Gaussian Variation Field 扩散模型
——基于时间感知Transformer的条件生成
在获得高效的潜在表示后,团队构建了一个条件扩散模型,用于从视频中生成对应的4D潜在码。
模型架构特点:
| 组件 | 功能 |
|---|---|
| 时间感知扩散Transformer | 引入时间自注意力机制,建模帧间动态一致性 |
| 双条件输入 | 以输入视频帧序列 + 静态规范GS为条件,指导去噪过程 |
| 交叉注意力机制 | 融合视频视觉特征与3D先验信息,实现精准对齐 |
推理流程:
- 输入一段物体运动视频(如旋转、摆动)
- 提取视频时序特征,并提供初始静态GS表示
- 扩散模型在潜在空间中逐步去噪,生成完整的高斯变化场
- 解码器还原为动态3D高斯场景,实现4D内容输出
工作原理简图
[输入视频]
↓
视觉编码器(提取时序特征)
↓
[规范GS表示] → + → [Gaussian Variation Field Diffusion Model]
↓(去噪生成)
[512维动态潜在码]
↓
[4DMesh-to-GS VAE 解码器]
↓
[动态3D高斯场景输出]
整个流程端到端可微,支持从2D视频到4D内容的无缝生成。
效果展示:从视频到可动画3D
示例场景
输入:一段展示玩具猫旋转的短视频(无标注、非专业拍摄)
输出:一个可在任意视角查看、支持时间轴播放的动态3D模型,其姿态、光照、纹理均与原始视频高度一致。
与传统方法相比,GVFDiffusion 不需要:
- 多视角同步拍摄
- 显式3D扫描
- 逐帧手动对齐
只需一段普通视频,即可自动完成4D重建。
实验结果:质量与泛化双优
1. 定量评估(Objaverse 子集测试)
| 指标 | GVFDiffusion | 次优方法 |
|---|---|---|
| PSNR ↑ | 28.7 | 26.3 |
| SSIM ↑ | 0.891 | 0.852 |
| LPIPS ↓ | 0.142 | 0.187 |
| FVD ↓(时间一致性) | 36.5 | 48.9 |
✅ 在空间细节与时间连贯性上均显著领先。
2. 定性表现
- 几何细节丰富,边缘清晰,无明显模糊或漂移;
- 动态过程平滑自然,无跳变或抖动;
- 对遮挡、光照变化具有较强鲁棒性。
3. 泛化能力
尽管模型仅在合成数据上训练(使用Objaverse中可动画对象生成的渲染视频),但在真实世界视频(如YouTube片段、手机拍摄)上仍表现优异。
🌍 这意味着:无需真实4D标注数据,也能用于现实场景建模。
主要功能与特点总结
✅ 主要功能
- 视频到4D生成:从单视角视频生成动态3D内容
- 无需多视角输入:支持非专业拍摄条件下的建模
- 端到端生成:无需中间3D重建或优化步骤
🔍 核心特点
| 特性 | 说明 |
|---|---|
| 高效潜在表示 | 512维向量即可编码完整4D动画 |
| 时间感知建模 | 时间自注意力保障动态连贯性 |
| 强泛化能力 | 合成训练 → 真实视频推理,跨域表现稳定 |
| 免逐实例拟合 | 不依赖对象特定初始化,支持快速推理 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...