Meta 开源 Omnilingual ASR:支持 1600+ 语言的语音识别系统Meta AI 近日发布了 Omnilingual ASR——一套开源、可扩展的多语言自动语音识别(ASR)系统,支持 1600 多种语言,并能通过零样本上下文学习泛化到 超过 5400 种语言,包括...语音模型# Meta# Omnilingual ASR# 语音识别3个月前0660
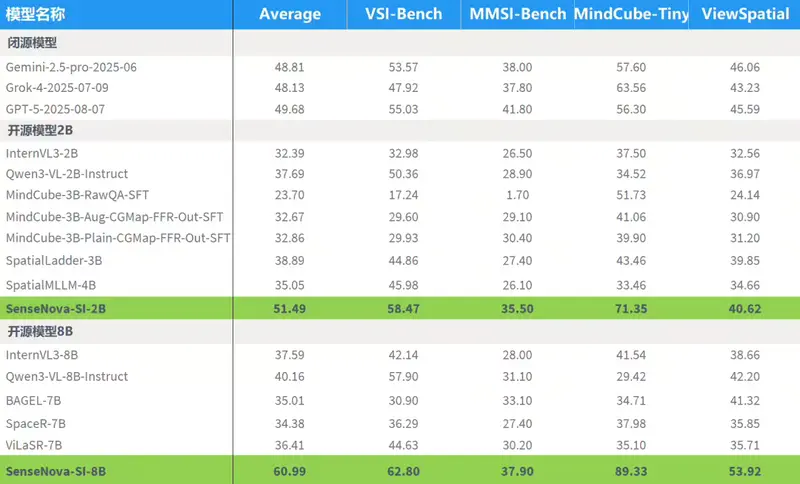
商汤开源SenseNova-SI:面向空间智能的多模态模型当前主流多模态基础模型在文本、图像理解、推理和生成任务上已取得显著进展,但在空间智能(Spatial Intelligence)方面仍存在系统性短板。具体表现为: 对物体尺度、距离、比例的估计不准确 ...多模态模型# SenseNova-SI# 商汤# 空间智能3个月前01140
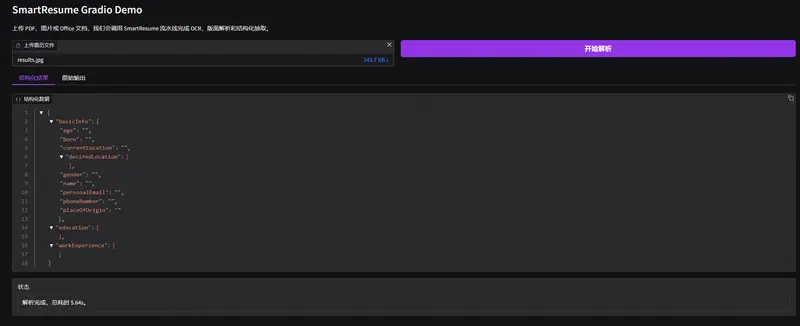
阿里巴巴推出 SmartResume:一个能“读懂”复杂简历版式的智能解析系统在企业招聘中,自动化处理海量简历是刚需,但简历格式千奇百怪——多栏排版、图文混排、表格嵌套,传统文本提取工具常会打乱语义顺序,导致关键信息错位。 针对这一难题,阿里巴巴企业智能团队发布了 SmartR...多模态模型# SmartResume# 智能简历解析# 阿里巴巴3个月前01530
阶跃星辰开源 Step-Audio-EditX:首个基于 LLM 的迭代式音频编辑模型阶跃星辰(Step AI)正式发布 Step-Audio-EditX —— 一款革命性的基于大语言模型(LLM)的音频编辑系统,首次实现对语音情感、说话风格与副语言特征的高精度、迭代式、零样本控制,并...语音模型# Step-Audio-EditX# 阶跃星辰# 音频编辑模型3个月前01430
美团 LongCat 团队发布 LongCat-Video:高效长视频生成的开源新标杆美团LongCat团队推出 LongCat-Video,这是一个基础视频生成模型,拥有 13.6B 参数,在文本到视频、图像到视频以及视频续接生成任务中表现出色。它特别擅长高效且高质量的长视频生成,标...视频模型# LongCat# LongCat-Video# 美团3个月前0270
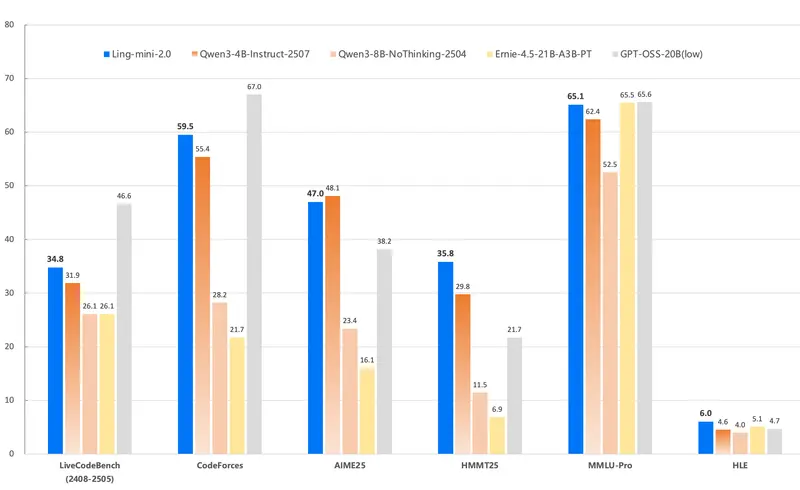
蚂蚁集团发布 Ling 2.0:基于“推理优先”原则的稀疏大模型家族蚂蚁集团 百灵大模型团队近日发布 Ling 2.0 —— 一个系统性构建的 稀疏混合专家(MoE)语言模型系列,核心理念是:模型容量可无限扩展,但每个 token 的计算成本应保持恒定。该系列通过统一...大语言模型# Ling 2.0# 蚂蚁集团3个月前0390
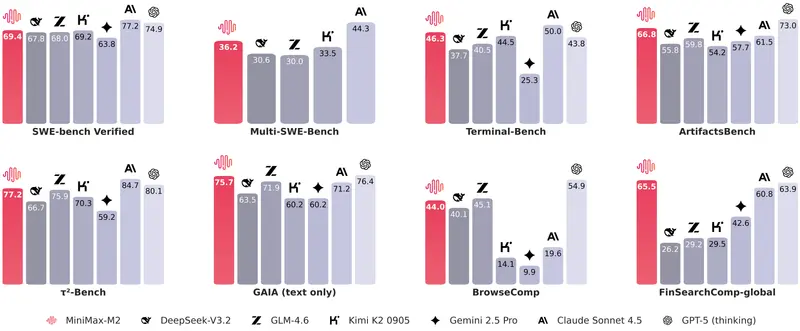
MiniMax 发布 MiniMax M2:面向编码与代理的高性能开源 MoE 模型MiniMax 团队正式发布 MiniMax M2 —— 一款专为代码生成与 AI 代理工作流优化的混合专家(Mixture-of-Experts, MoE)模型。该模型以 MIT 开源许可 在 Hu...大语言模型# MiniMax M23个月前0280
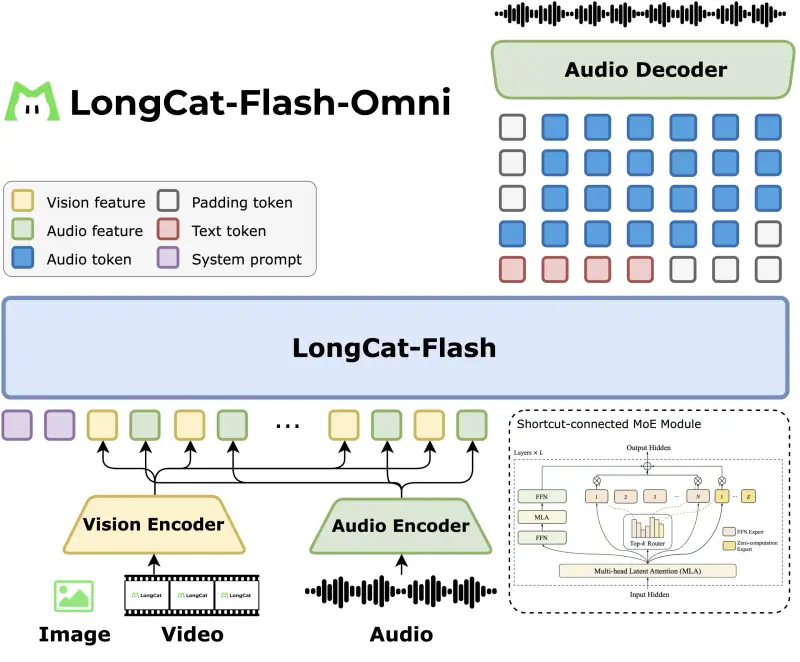
美团发布LongCat-Flash-Omni:开源全模态大模型的实时交互新标杆美团 LongCat 团队近日开源了 LongCat-Flash-Omni —— 一款参数总量达 5600 亿、每 token 动态激活 270 亿参数 的 全模态大模型(Full-Modal LLM...多模态模型# LongCat-Flash-Omni# 美团3个月前0130
百度飞桨发布 PaddleOCR-VL(0.9B):轻量级端到端多语言文档解析模型百度飞桨团队近日开源 PaddleOCR-VL(0.9B)——一款专为复杂版式文档智能解析设计的视觉语言模型(VLM)。该模型以仅 9亿参数的轻量级架构,实现了对文本、表格、数学公式、图表及手写体的高...多模态模型# PaddleOCR-VL# 文档解析模型3个月前0200
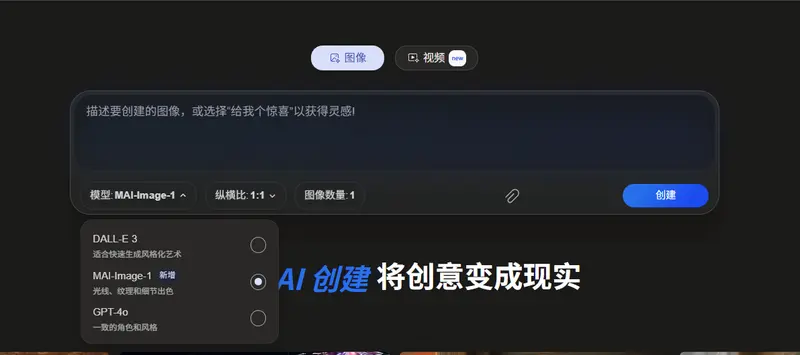
微软在Bing平台推出AI图像生成模型MAI-Image-1尽管微软已全面接入OpenAI最新前沿模型,该公司仍在自主研发AI模型,通过差异化产品与服务更好地满足用户需求。今年初,微软曾宣布首批两个自研AI模型:MAI-Voice-1与MAI-1-previe...图像模型# MAI-Image-1# 微软3个月前0420
月之暗面推出开源思维模型Kimi K2 Thinking,多项能力达SOTA水平月之暗面正式发布旗下迄今能力最强的开源思考模型——Kimi K2 Thinking。这款基于“模型即Agent”理念训练的新一代Thinking Agent,最核心的突破在于原生掌握“边思考,边使用工...大语言模型# Kimi K2 Thinking# 月之暗面3个月前0480
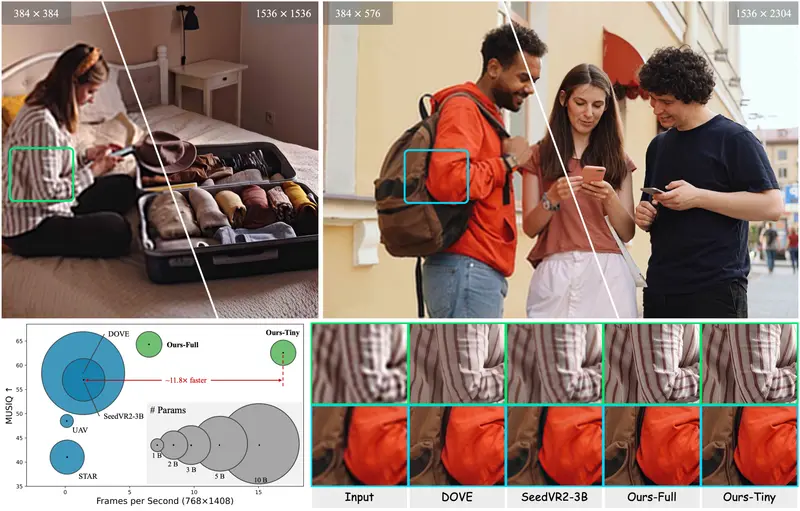
FlashVSR:首个实时扩散视频超分框架,17 FPS 处理 1408p 视频视频超分辨率(Video Super-Resolution, VSR)的目标是将低分辨率视频高质量地重建为高分辨率版本。近年来,扩散模型在图像和视频恢复任务中展现出强大能力,但其高延迟、高计算开销和对...视频模型# FlashVSR# 视频超分辨率框架3个月前0270