FantasyPortrait:基于DIT架构模型的多角色肖像动画生成框架由阿里巴巴与北京邮电大学联合提出,FantasyPortrait 是一个基于扩散变换器(Diffusion Transformer)的创新框架,用于从静态图像生成高保真、富有表现力的单角色与多角色面部...视频模型# FantasyPortrait# 多角色肖像动画生成9个月前01020
LightX2V:轻量级视频生成推理框架,统一支持多种模态输入随着多模态生成模型的发展,文本到视频(T2V)、图像到视频(I2V)等任务逐渐成为研究热点。然而,不同模型往往使用不同的推理流程,导致部署与调用复杂、资源占用高。 为此,研究人员推出了一个全新的轻量级...视频模型# LightX2V# 视频生成9个月前02820
韩国科学技术院提出 ALG 方法:显著提升图生视频模型的动态性图像到视频(Image-to-Video, I2V)模型近年来取得了长足进展,能够根据一张静态图像和文本提示生成动态视频,实现更强的视觉控制。然而,研究发现,这类模型往往生成的视频过于静态,动态性远不...视频模型# ALG# 图生视频9个月前01680
PUSA V1.0:以500 美元成本超越 WAN-I2V-14B 的高效视频生成模型由香港城市大学、华为研究院、腾讯、岭南大学等机构联合提出,PUSA V1.0 是一个基于矢量化时间步适应(VTA) 的新型视频扩散模型,实现了极低资源消耗下的高质量视频生成能力。 项目主页:https...视频模型# PUSA V1.0# WAN-I2V-14B# 视频生成模型9个月前06370
清华大学推出SketchColour:基于扩散变换器的高效 2D 动画自动上色方案清华大学的研究人员提出了一种全新的 2D 动画着色方法——SketchColour。该方法基于扩散变换器(DiT)架构,能够将黑白草图序列自动转换为连贯的彩色动画,显著提升动画制作效率。 项目主页:h...视频模型# 2D 动画自动上色# SketchColour9个月前02000
StreamDiT:实现实时流式文本到视频生成的新一代扩散模型近年来,随着基于变换器(Transformer)的扩散模型向数十亿参数扩展,文本到视频(Text-to-Video, T2V)生成技术取得了显著进展。尽管当前模型已能生成高质量视频内容,但它们通常只能...视频模型# StreamDiT# 流式视频生成模型9个月前03800
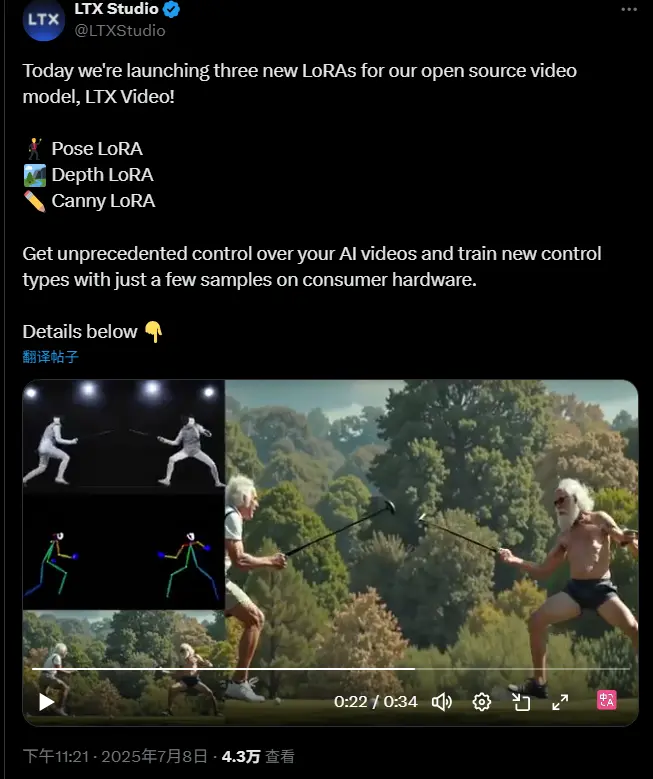
LTX Studio为其开源视频生成模型 LTX Video 推出三款全新 LoRA控制模型,为开源视频模型带来前所未有的控制力LTX Studio 为其开源视频生成模型 LTX Video 推出了三项全新的 LoRA 控制模块,让 AI 视频创作进入一个更具操控性与表现力的新阶段。 Depth Control: LTX-Vi...视频模型# LTX Studio# LTX Video9个月前01850
DLoRAL:一种兼顾细节与时间一致性的视频超分辨率新方法在现实世界视频超分辨率(Real-VSR)任务中,如何从低质量(LQ)视频中恢复出既细节丰富又时间连贯的高质量(HQ)视频,是一个极具挑战性的问题。尤其是在使用预训练扩散模型(如 Stable Dif...视频模型# DLoRAL# 视频超分辨率9个月前04160
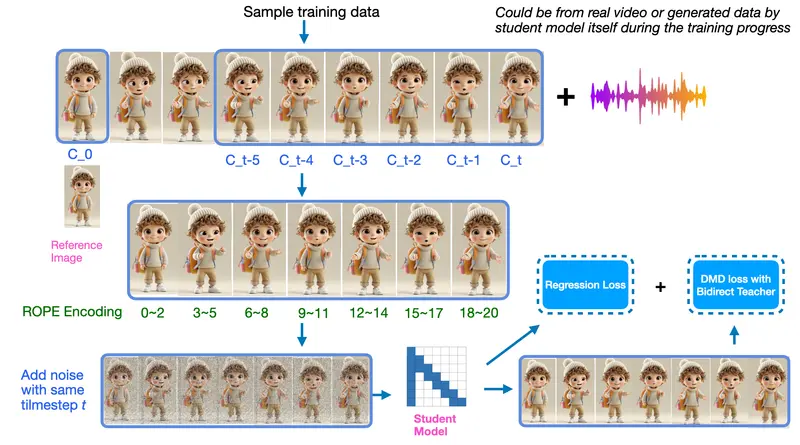
Character.AI 推出 TalkingMachines:音频驱动的实时视频生成模型,打造“FaceTime 风格”AI 视频交互知名 AI 角色平台 Character.AI 发布了一项引人注目的研究成果——TalkingMachines,一个基于扩散模型的新型自回归视频生成系统。该系统仅需一张静态图像和一段语音输入,即可生成...视频模型# Character.AI# TalkingMachines9个月前02020
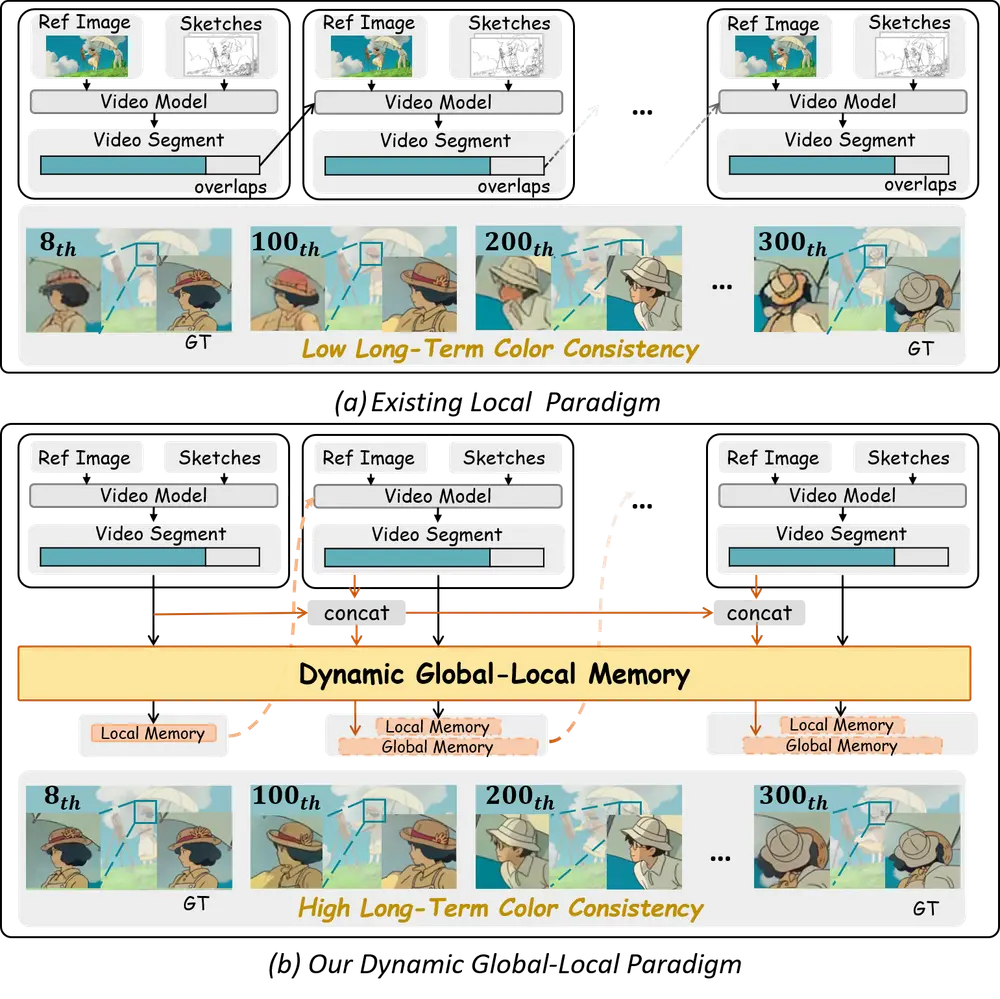
中科大 & 港科大联合推出 LongAnimation :实现长动画自动上色的新框架来自中国科学技术大学与香港科技大学的研究团队联合提出了一种名为 LongAnimation 的新型动画着色框架。该框架旨在实现长动画序列的自动化着色,并在整个动画过程中保持长期的颜色一致性。 项目主页...视频模型# LongAnimation# 动画自动上色9个月前02250
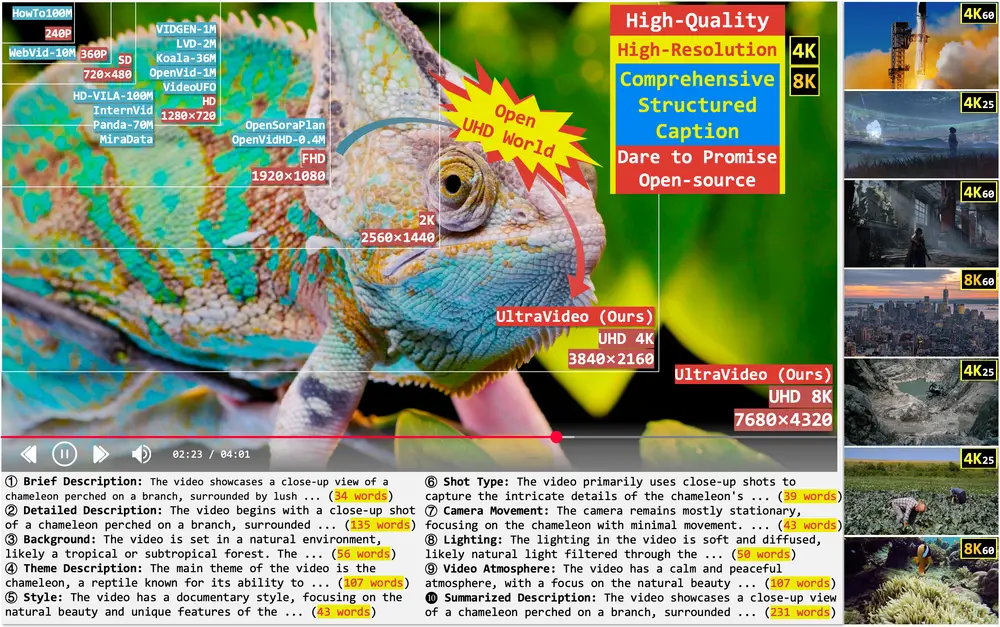
UltraVideo 与 UltraWAN:首个支持原生 UHD 视频生成的开源数据集与模型随着高质量视频内容需求的快速增长,如电影级超高清(UHD)制作、沉浸式媒体和短视频创作,对文本到视频(T2V)模型的能力提出了更高要求。 然而,现有公开数据集在分辨率、图像质量及字幕细节方面存在明显不...视频模型# UltraVideo# UltraWAN# UltraWanComfy10个月前04440
EdgeTAM:Meta 与南洋理工等联合推出可在手机运行的视频分割模型,比 SAM 2 快 22 倍由 Meta Reality 实验室、南洋理工大学 和 上海人工智能实验室 联合提出的新模型 EdgeTAM 引起了广泛关注。该模型是对 Segment Anything Model 2(SAM 2...视频模型# EdgeTAM# SAM 2# 视频分割模型10个月前02860