
知名 AI 角色平台 Character.AI 发布了一项引人注目的研究成果——TalkingMachines,一个基于扩散模型的新型自回归视频生成系统。该系统仅需一张静态图像和一段语音输入,即可生成高质量、实时响应的 AI 视频角色,效果接近 FaceTime 式的自然对话体验。
目前,该项目仍处于研究阶段,相关论文和演示视频已公开,但尚未集成到 Character.AI 的正式产品中。
技术亮点
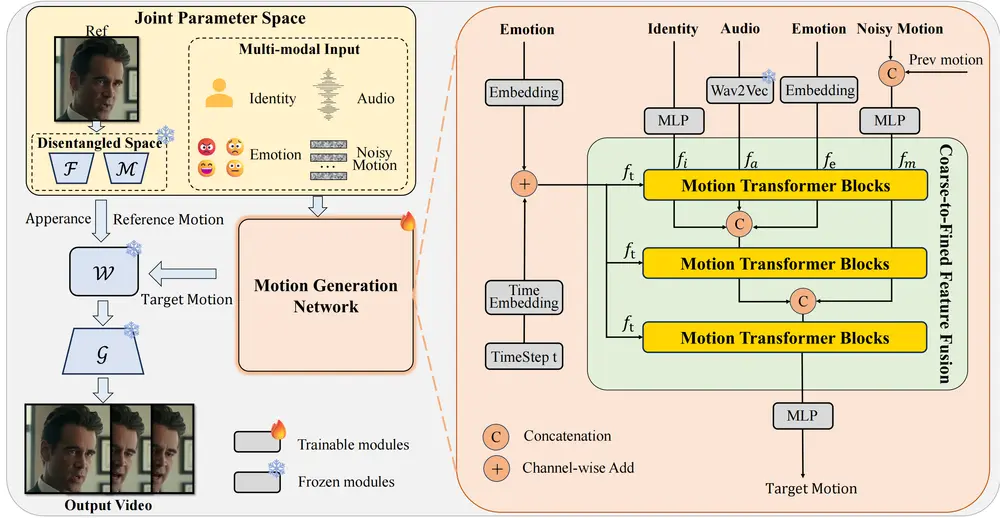
✅ 模型架构:Diffusion Transformer (DiT)
TalkingMachines 基于 DiT 架构构建,融合了扩散模型的高质量生成能力和 Transformer 的序列建模优势,能够生成从细微表情到动态手势在内的复杂面部动作。
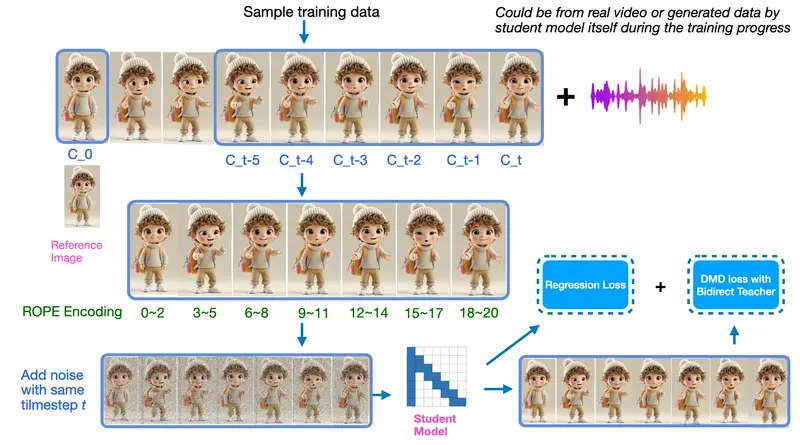
✅ 流匹配扩散(Flow-Matched Diffusion)
- 通过流匹配机制,使模型能够学习连续帧之间的运动模式;
- 支持从静态图像出发生成连贯、自然的面部动画;
- 可模拟眨眼、头部微动、口型变化等细节表现。
✅ 音频驱动注意力机制(Audio-Driven Cross Attention)
- 内置 12 亿参数的音频理解模块;
- 能够精准捕捉语音中的节奏、停顿与语调;
- 实现嘴唇、眼睛、头部动作与语音内容的高同步性。
✅ 稀疏因果注意力(Sparse Causal Attention)
- 区别于传统双向注意力机制;
- 仅关注最相关的前序帧,降低计算冗余;
- 在保证质量的同时显著减少内存占用与推理延迟。
✅ 非对称知识蒸馏(Asymmetric Distillation)
- 利用改进版 CausVid 方法训练轻量级学生模型;
- 学习高质量教师模型的行为,实现快速两步扩散生成;
- 支持无限长度视频生成,且无时间衰减问题。
💡 核心能力总结
| 功能 | 描述 |
|---|---|
| 🎤 音频驱动生成 | 输入语音信号即可生成嘴部、眼部、头部动作,高度同步 |
| 📷 单图启动 | 仅需提供一张人物图片作为初始状态 |
| ⚡ 实时生成 | 不依赖预渲染,逐帧实时输出,支持低延迟互动 |
| 🧠 自回归建模 | 利用稀疏注意力机制维持长时间一致性 |
| 🖼️ 风格多样性 | 支持真实人类、动漫角色、3D 头像等多种视觉风格 |
| 🧑🤝🧑 多角色轮换 | 自动检测发言/沉默状态,实现多个 AI 角色间自然切换 |
🚀 技术突破意义
TalkingMachines 是 Character.AI 在生成式 AI 视频领域的一次重要飞跃,标志着其从静态角色交互向视听一体化沉浸式体验的关键转变。
这项研究不仅限于人脸动画,更是在为未来的:
- AI 对话助手
- 虚拟主播 / 数字人
- 角色扮演与故事叙述
- 交互式虚拟世界构建
打下坚实基础。
📈 应用前景展望
TalkingMachines 的推出,意味着 AI 视频生成正在迈向更高层次的交互性和实时性:
| 场景 | 描述 |
|---|---|
| 🗣️ 类似 FaceTime 的 AI 通话 | 用户可与个性化的 AI 角色进行面对面交流 |
| 🎭 角色扮演游戏(RPG) | 创建具有丰富表情和语音反应的 NPC 角色 |
| 📺 虚拟主播与数字人 | 自动生成带语音同步的虚拟主持人或客服形象 |
| 📚 教育与培训场景 | 打造更具沉浸感的虚拟讲师或模拟对话训练系统 |
| 🌐 元宇宙与虚拟世界 | 构建可自由定制、实时响应的虚拟居民 |
🛠 训练与部署细节
为了打造 TalkingMachines,Character.AI 在以下方面进行了大量工程优化:
📊 数据规模
- 使用超过 150 万个精选视频片段 进行训练;
- 覆盖多种性别、种族、年龄及表达方式;
- 涵盖真实人类、卡通风格与 3D 渲染角色。
🧪 训练流程
采用三阶段训练流水线,使用约 256 块 H100 GPU,确保模型具备强大的泛化能力与细节还原度。
🚀 部署优化
- 引入 CUDA 流重叠 技术提升吞吐;
- 使用 KV 缓存 加速注意力计算;
- 将 VAE 解码器分离,进一步压缩推理延迟;
- 经过深度优化后,仅需双卡 GPU 即可实时运行。
🧩 当前限制与未来方向
尽管 TalkingMachines 展现出强大潜力,但仍存在一些技术挑战:
| 限制 | 说明 |
|---|---|
| 📸 依赖高质量图像输入 | 图像分辨率、角度和清晰度影响最终生成质量 |
| 🎙️ 语音必须清晰可辨 | 含糊或背景噪音可能影响动作同步精度 |
| 📺 目前仅支持单人视角 | 多人互动尚处于探索阶段 |
| 📱 未上线正式产品 | 仍在研究验证阶段,尚未面向公众开放 |
Character.AI 表示正积极推动该技术落地,未来将逐步整合进其平台,实现:
- 类 FaceTime 的 AI 视频聊天功能
- 角色流式传输
- 可视化世界构建工具链
📺 示例演示
Character.AI 已发布多个演示视频,展示了 TalkingMachines 的以下能力:
- 高质量唇形与语音同步
- 自然的头部动作与眼神变化
- 多风格角色适配(真人、二次元、3D)
- 多角色轮流发言的初步尝试
这些演示表明,TalkingMachines 已具备构建“会说话的 AI 角色”的核心能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











