在现实世界视频超分辨率(Real-VSR)任务中,如何从低质量(LQ)视频中恢复出既细节丰富又时间连贯的高质量(HQ)视频,是一个极具挑战性的问题。尤其是在使用预训练扩散模型(如 Stable Diffusion, SD)生成逼真细节时,这种权衡尤为明显。
近日,来自 香港理工大学 和 OPPO 研究院 的研究团队提出了一种新的解决方案 —— DLoRAL(Dual LoRA Learning),通过引入双 LoRA 学习机制,在保持时间一致性的同时,显著提升了视频的空间细节质量。

🔍 问题背景:细节 vs 时间一致性
视频超分辨率(VSR)的目标是从低质量视频中重建出高质量视频,广泛应用于老旧视频修复、在线内容增强、监控系统提升等多个领域。
然而,现有基于扩散模型的方法往往面临一个关键矛盾:
- 如果过度强调时间一致性,会导致视频缺乏细节,画面模糊;
- 如果追求空间细节,则容易出现帧间闪烁或跳跃,影响观看体验。
因此,如何在这两者之间取得平衡,成为 Real-VSR 领域的核心难题。
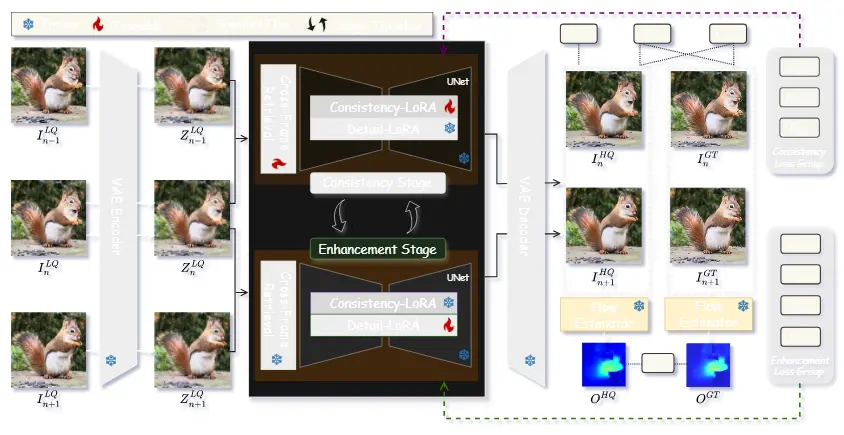
🧩 解决方案:DLoRAL 方法概述
DLoRAL 提出了一种两阶段学习策略,将“时间一致性”和“空间细节增强”分离建模,并通过高效的 LoRA 模块分别优化,最终融合输出。
核心模块介绍:
- 跨帧检索模块(CFR)
- 聚合相邻帧中的结构信息
- 提取对退化具有鲁棒性的时空特征
- 为后续一致性学习提供基础
- 一致性 LoRA(C-LoRA)
- 在第一阶段训练,专注于学习时间一致性表示
- 固定后用于指导第二阶段的细节增强
- 细节 LoRA(D-LoRA)
- 在第二阶段训练,专注于增强每一帧的空间细节
- 与 C-LoRA 对齐,确保增强过程不破坏时间一致性
训练流程:
- 第一阶段:利用 CFR + C-LoRA 学习时间一致性
- 第二阶段:固定 CFR 和 C-LoRA,仅训练 D-LoRA 来增强细节
- 交替迭代优化两个阶段,逐步提升性能
推理阶段:
- 将两个 LoRA 分支合并到原始 SD 模型中
- 实现单步扩散推理,大幅提升效率,同时保持高质量输出
✅ 技术优势
| 优势维度 | 描述 |
|---|---|
| 细节丰富性 | 能够恢复清晰纹理、边缘及微小结构,视觉效果更真实 |
| 时间一致性 | 帧间过渡自然,无闪烁或跳变现象 |
| 高效性 | 单步扩散设计使推理速度比多步方法快约 10 倍,参数量低 |
📊 实验结果
在多个主流 VSR 数据集上的测试表明,DLoRAL 表现出色:
- 感知质量指标(如 LPIPS、DISTS、MUSIQ)优于现有方法
- 时间一致性指标(如 E* warp)也达到领先水平
- 用户调研反馈 显示,其视觉质量和流畅度获得高度认可
🌐 应用场景
DLoRAL 可广泛应用于以下实际场景:
- 视频修复与增强:提升老旧视频或压缩视频的画质,适配高清播放设备
- 数字内容创作:为后期制作提供更高质量的素材基础
- 远程教育与会议:改善在线教学视频的观看体验
- 视频监控分析:增强监控视频清晰度,辅助目标识别与行为追踪
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











