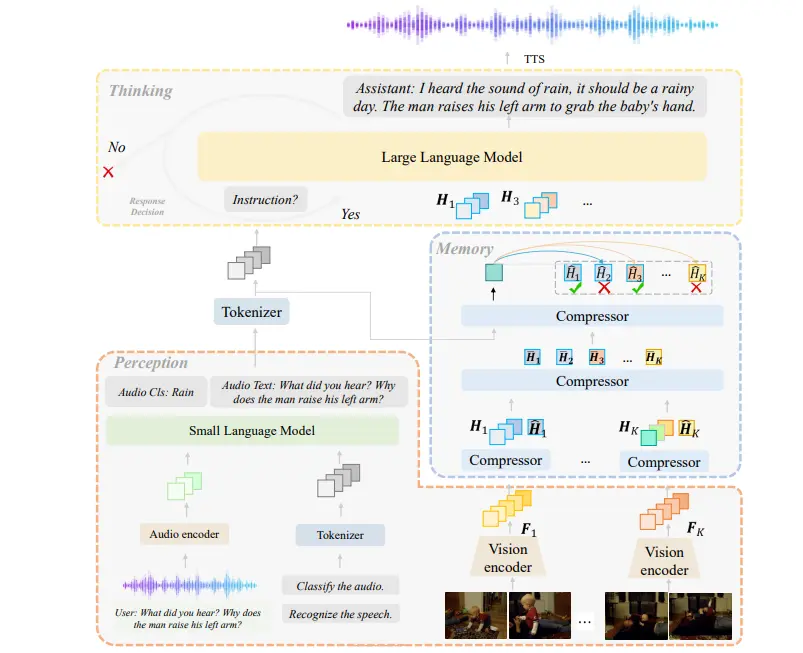
综合多模态系统InternLM-XComposer2.5-OmniLive (浦语·灵笔 2.5 OmniLive):实现实时视频和音频交互创建能够像人类认知一样长时间与环境互动的AI系统一直是人工智能领域的长期研究目标。尽管多模态大语言模型(MLLMs)在开放世界理解方面取得了显著进展,但在连续和同时的流式感知、记忆和推理方面仍然面临巨...多模态模型# InternLM-XComposer2.5-OmniLive# 浦语·灵笔 2.5 OmniLive12个月前02550
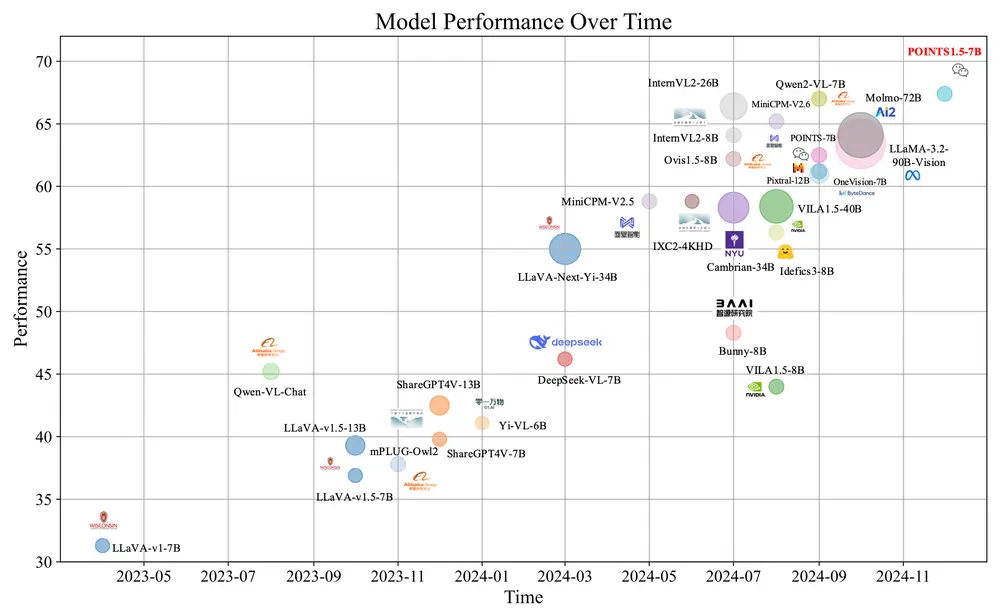
微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列:提升对真实世界应用的处理能力微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列,旨在提升对真实世界应用的处理能力。POINTS1.5是POINTS1.0的增强版本,它通过引入几项关键创新,改进了模型在处理高分辨率图像...多模态模型# POINTS1.5# 视觉语言模型12个月前03570
多模态大语言模型InternVL 2.5:处理和理解来自多种模态(如文本、图像和视频)的信息InternVL 2.5 是由上海人工智能实验室、商汤科技研究院、清华大学、南京大学、复旦大学、香港中文大学和上海交通大学等多家机构联合推出的一款先进的多模态大语言模型(MLLM)。该模型基于此前发布...多模态模型# InternVL 2.5# 多模态大语言模型12个月前02930
开源视觉语言模型Moondream:将强大的图像理解能力与极小的资源占用完美结合Moondream 是一款高效的开源视觉语言模型(VLM),它将强大的图像理解能力与极小的资源占用完美结合。这款模型设计初衷是为各种设备和平台提供多功能且易于访问的人工智能解决方案。 官网:https...多模态模型# Moondream# 视觉语言模型12个月前03330
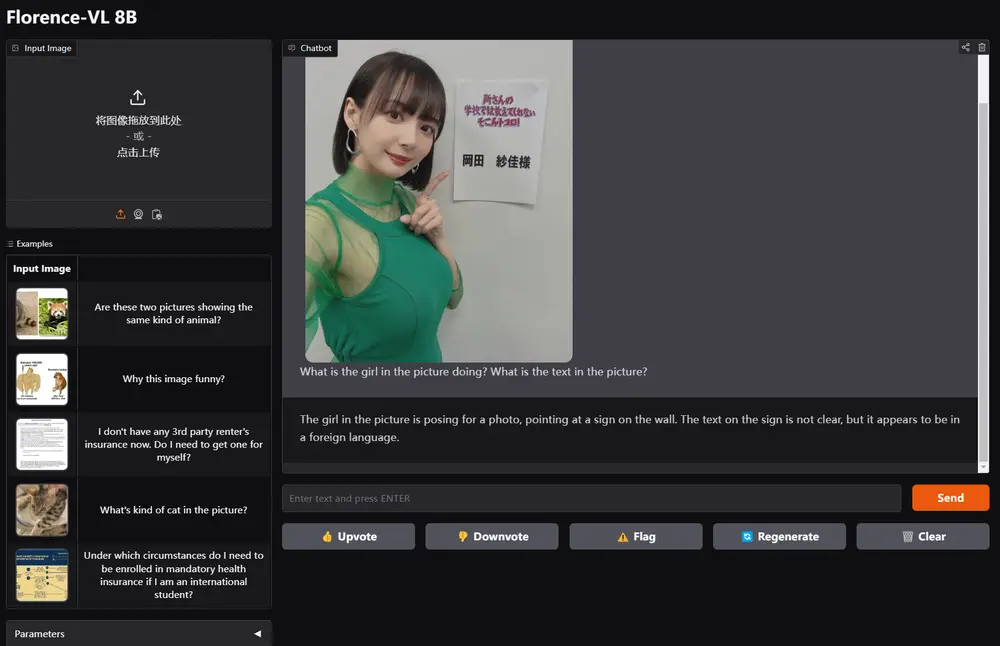
微软推出全新多模态大语言模型家族Florence-VL马里兰大学和微软研究院的研究团队共同提出了Florence-VL,这是一个全新的多模态大语言模型(MLLMs)家族。Florence-VL的视觉表示由生成式视觉基础模型Florence-2生成,与传统...多模态模型# Florence-VL# 多模态大语言模型# 微软12个月前03110
谷歌推出开源视觉语言模型PaliGemma2:增加了强大的视觉能力,更容易微调今年5月,谷歌推出了 PaliGemma,这是 Gemma 家族中的第一个视觉语言模型,旨在使一流的视觉AI更加普及。现在,谷歌自豪地推出 PaliGemma 2,这是一个可调视觉语言模型的最新进化版...多模态模型# PaliGemma2# 视觉语言模型# 谷歌12个月前03060
多模态大语言模型ChatRex:提升对人类姿态的感知和理解能力IDEA的研究人员推出多模态大语言模型ChatRex,它旨在提升对人类姿态的感知和理解能力。ChatRex通过结合视觉和语言模型,能够执行多种与人体姿态相关任务,包括姿态理解、生成和编辑。这个模型特别...多模态模型# ChatRex# 多模态大语言模型12个月前02730
用于 GUI 自动化的视觉代理模型ShowUI:结合了视觉、语言和行动能力,提高人机交互的效率和生产力新加坡国立大学和微软的研究人员推出用于 GUI(图形用户界面) 自动化的视觉代理模型ShowUI ,它是一个结合了视觉、语言和行动能力的大模型,旨在提高人机交互的效率和生产力。ShowUI通过理解和执...多模态模型# ShowUI# 视觉代理模型12个月前02580
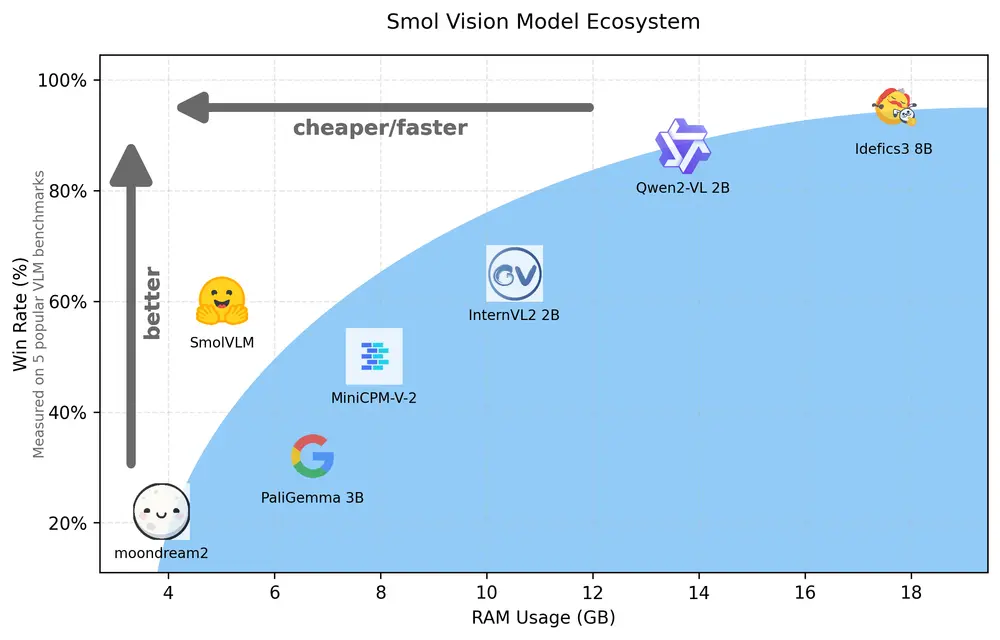
Hugging Face发布一个用于设备上推理的2B参数小型多模态模型SmolVLM近年来,随着机器学习技术的飞速发展,视觉-语言模型(VLM)的需求不断增加。这些模型能够处理图像和文本的组合任务,如图像描述、问答和故事生成等。然而,大多数现有的VLM需要大量的计算资源和内存,这限制...多模态模型# Hugging Face# SmolVLM# 多模态模型12个月前02920
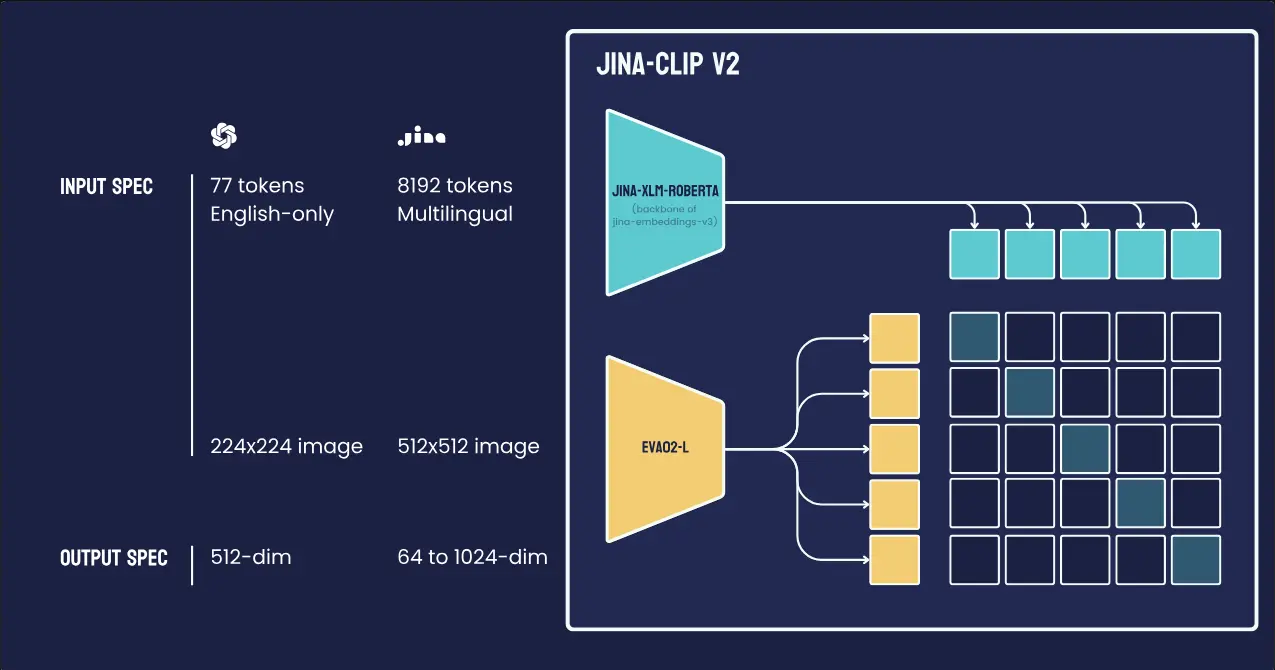
Jina CLIP v2:用于文本和图像的多语言多模态嵌入在互联互通的世界中,跨多种语言和媒介的有效沟通变得越来越重要。多模态AI在结合图像和文本以实现不同语言的无缝检索和理解方面面临着诸多挑战。现有的模型在英语中表现良好,但在其他语言中则表现不佳。此外,同...多模态模型# Jina CLIP v2# 多语言多模态嵌入12个月前03010
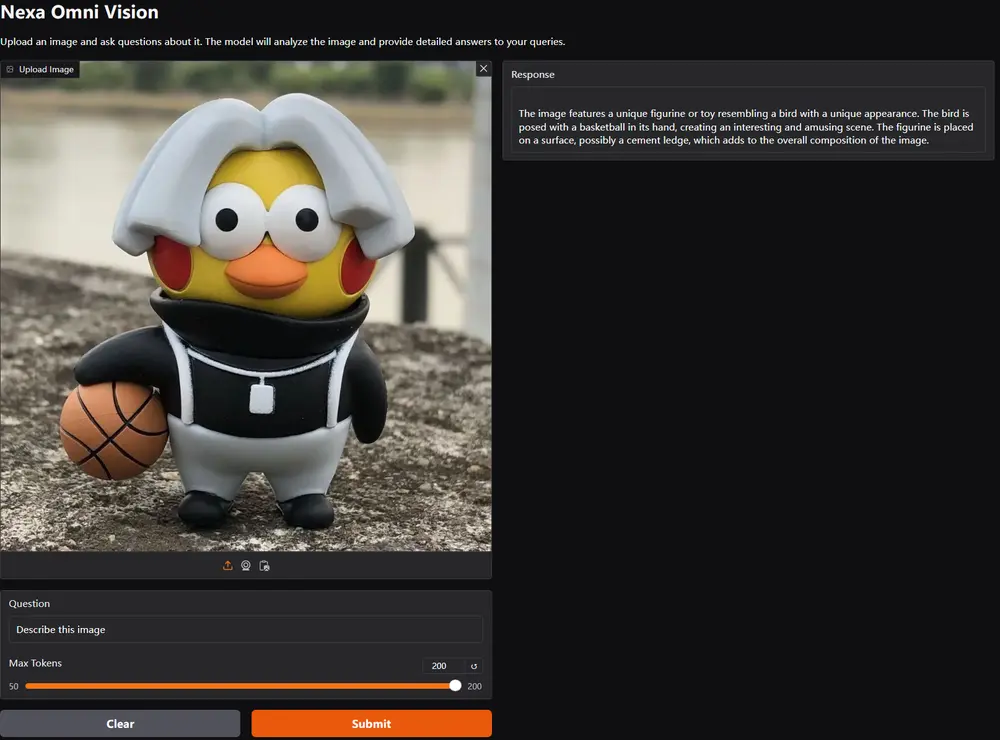
Nexa AI 推出迷你视觉语言模型 OmniVision-968MNexa AI 最新发布了 OmniVision-968M,这是一款专为边缘设备设计的视觉语言模型,它通过技术创新,将图像标记数量大幅减少,显著降低了延迟和计算负担,还提升了处理速度,为边缘计算领域带...多模态模型# Nexa AI# OmniVision-968M# 视觉语言模型12个月前07350
深度求索推出统一图像理解和生成的创新框架JanusFlow:将图像理解和生成统一在一个模型中来自深度求索(DeepSeek-AI)、香港大学、清华大学和北京大学的研究人员提出了一种名为JanusFlow的创新框架,该框架将图像理解和生成统一在一个模型中。JanusFlow引入了一个极简的架构...多模态模型# JanusFlow# 深度求索12个月前05180