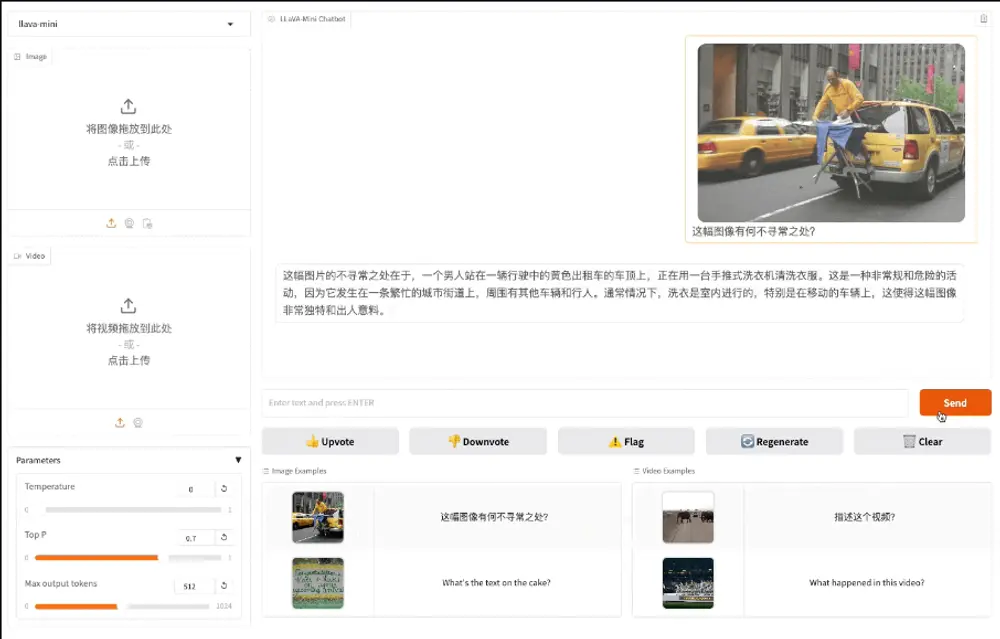
高效大型多模态模型LLaVA-Mini:通过最小化视觉令牌(vision tokens)的数量来提高模型的计算效率和响应速度中国科学院计算技术研究所智能信息处理重点实验室(ICT/CAS)、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出高效大型多模态模型LLaVA-Mini,旨在通过最小化视觉令牌(visi...多模态模型# LLaVA-Mini# 多模态模型1年前02930
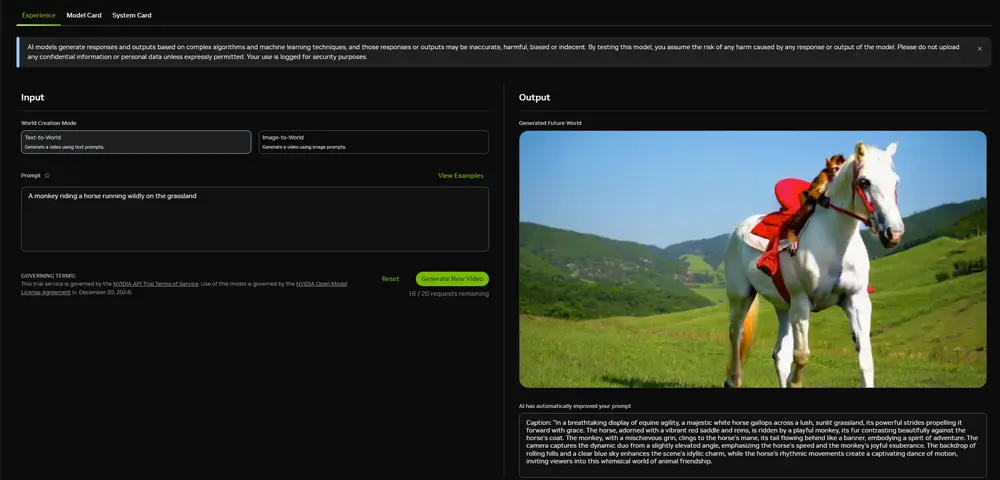
英伟达推出世界基础模型平台NVIDIA Cosmos :帮助物理 AI 开发人员更好、更快地构建物理 AI 系统英伟达在CES2025上宣布推出 NVIDIA Cosmos 平台,该平台包含先进的世界基础生成模型、高级分词器、防护栏和加速视频处理管道,旨在推动自动驾驶汽车(AV)和机器人等物理 AI 系统的发展...多模态模型# NVIDIA Cosmos# 世界模型# 英伟达1年前03590
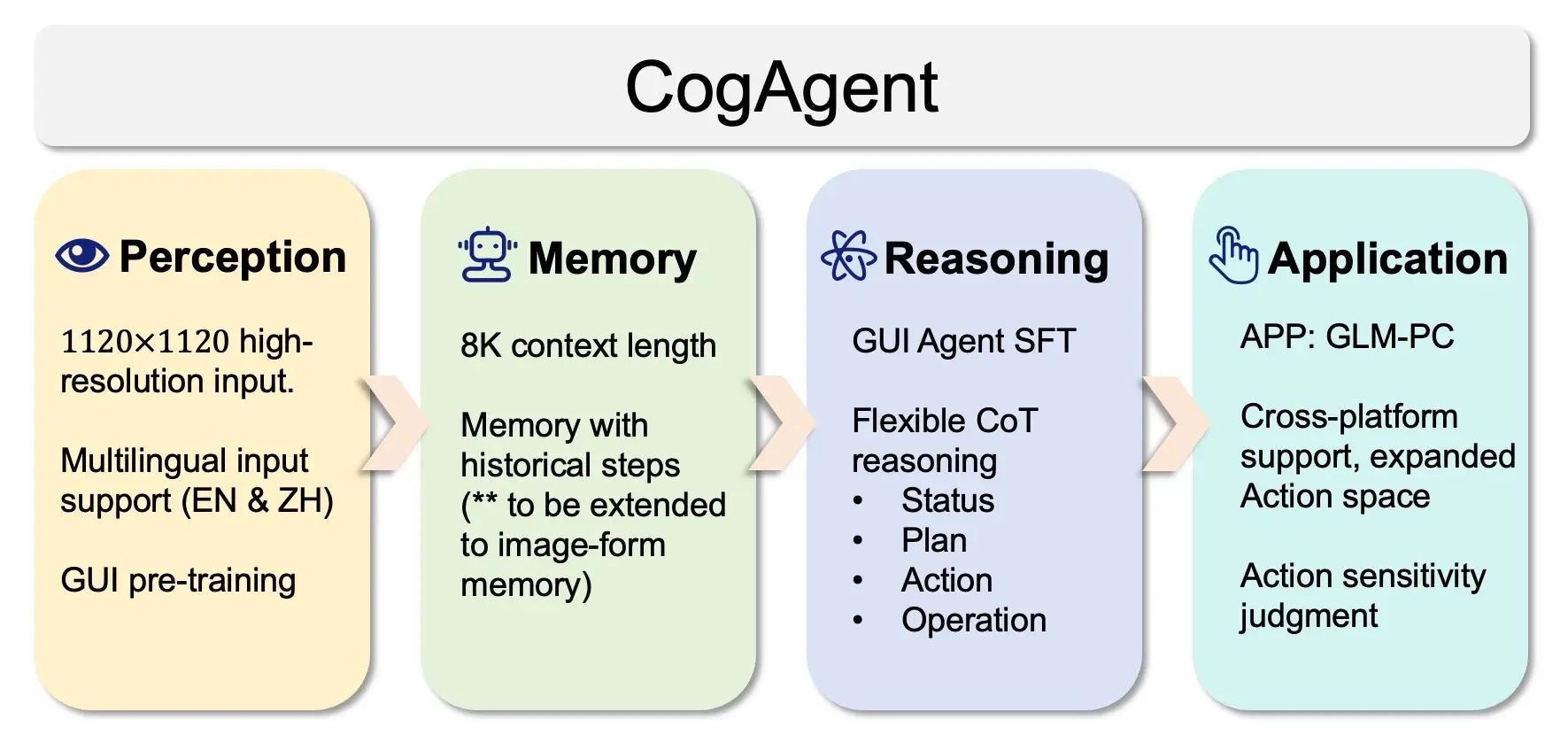
CogAgent-9B-20241220:基于视觉语言模型的开源 GUI agent 模型图形用户界面(GUI)是用户与软件交互的核心。然而,构建能够有效导航GUI的智能代理一直是一个持续的挑战。传统方法在适应性方面存在不足,尤其是在处理复杂布局或GUI频繁变化时,这些问题限制了自动化GU...多模态模型# CogAgent-9B-202412201年前02750
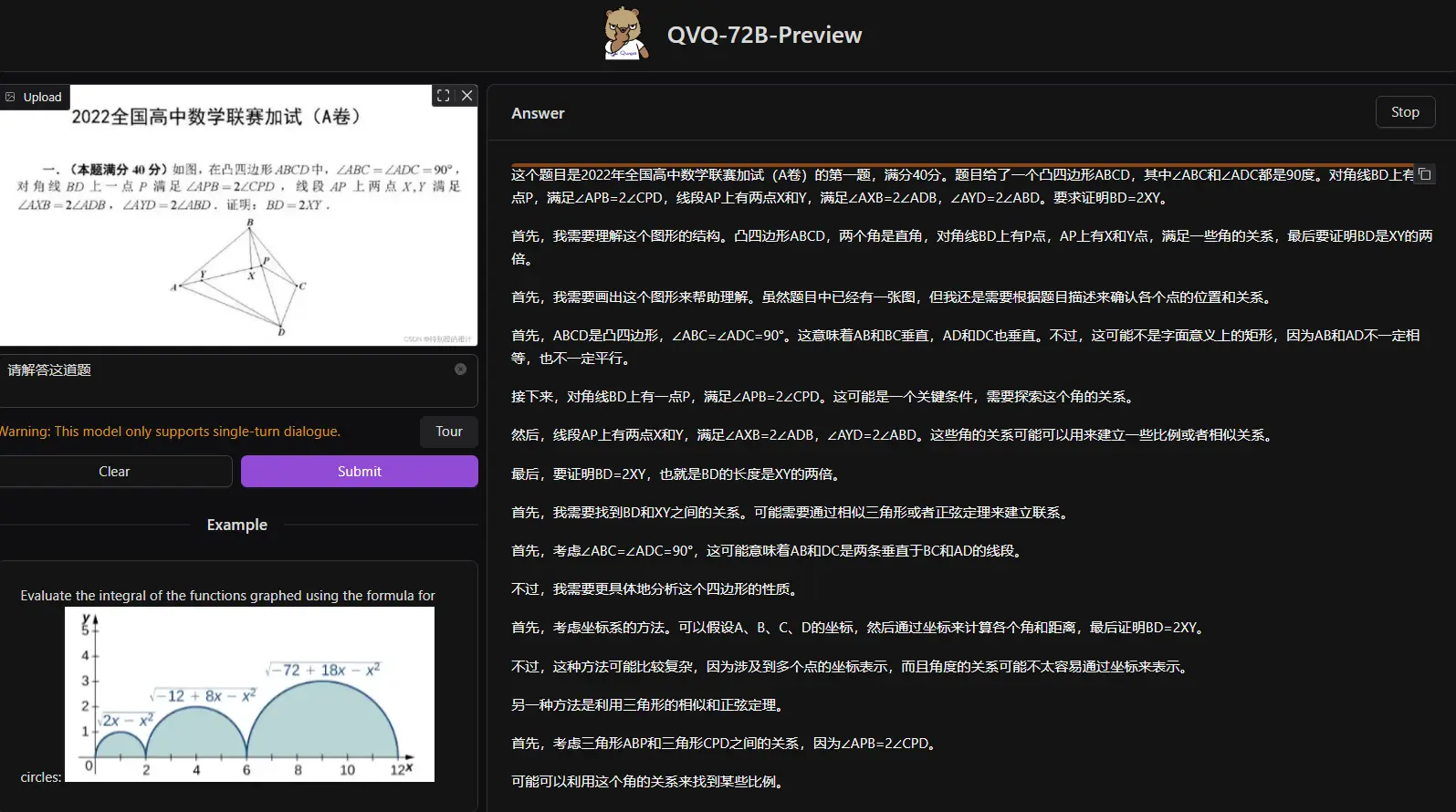
阿里通义团队为大家送上圣诞节大礼,开源全球首个视觉推理模型 QVQ-72B-Preview阿里通义团队为大家送上圣诞节大礼,开源了第一个视觉推理模型QVQ,其中V代表视觉。它只需读取一张图像和一个指令,开始思考,适时反思,持续推理,最终自信地生成预测!然而,它仍处于实验阶段,这个预览版本仍...多模态模型# QVQ-72B-Preview# 视觉推理模型# 阿里通义1年前03210
无问芯穹推出全球首个端侧全模态理解开源模型Megrez-3B-Omni12月16日,无问芯穹宣布正式开源其“端模型+端软件+端IP”端上智能一体化解决方案中的小模型——Megrez-3B-Omni,以及纯语言版本模型 Megrez-3B-Instruct。这一举措标志着...多模态模型# Megrez-3B-Omni# 无问芯穹1年前02720
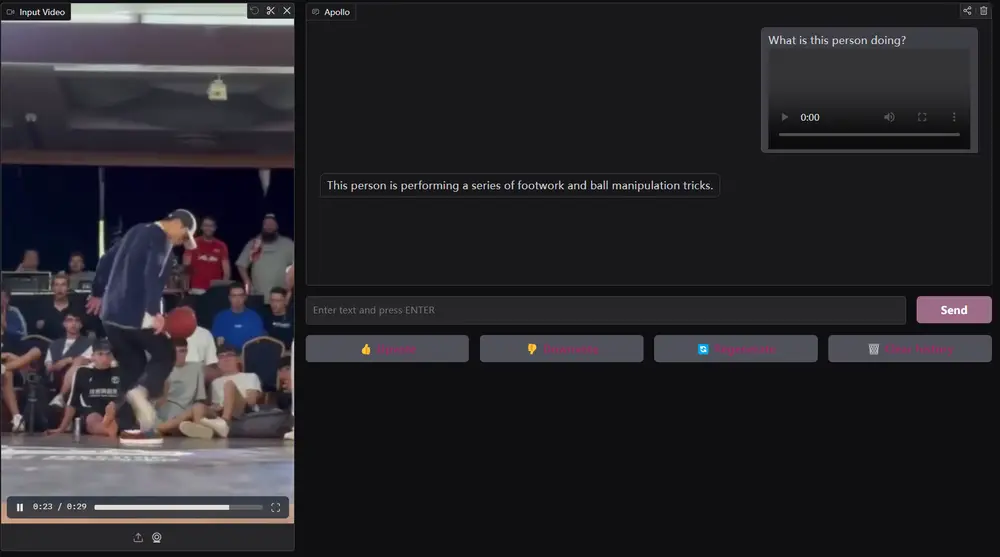
Meta推出多模态模型Apollo:擅长处理长视频,能够在长达一小时的视频中保持高效的理解能力尽管视频感知能力已经迅速集成到大型多模态模型(LMMs)中,但其驱动视频理解的基本机制仍未被充分理解。这导致了许多设计决策缺乏适当的理由或分析,尤其是在训练和评估这些模型时,高昂的计算成本和有限的开放...多模态模型# Apollo# Meta# 多模态模型1年前03060
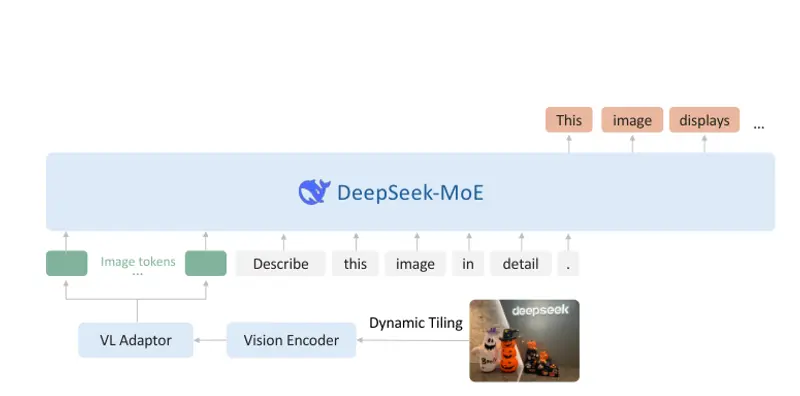
深度求索推出开源视觉模型DeepSeek-VL2 :支持动态分辨率、处理科研图表、解析各种梗图等DeepSeek-VL2 是由深度求索(DeepSeek-AI)推出的一系列先进混合专家(MoE, Mixture of Experts)视觉语言模型,旨在显著提升其前代产品 DeepSeek-VL ...多模态模型# DeepSeek-VL 2# 深度求索1年前02780
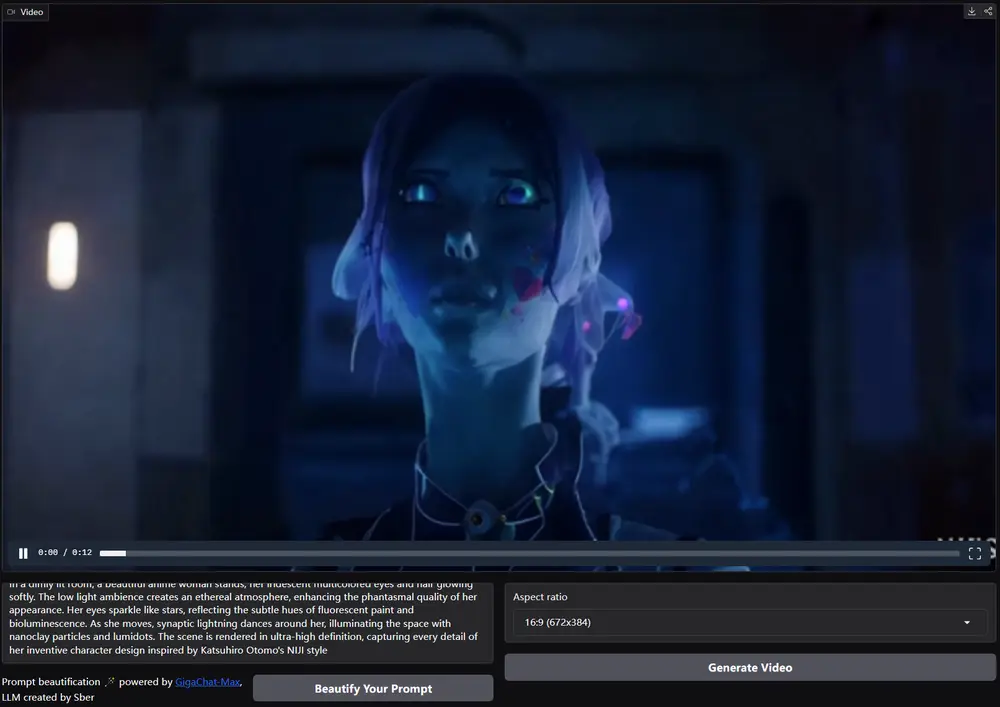
Sber AI 推出新一代多模态生成模型Kandinsky 4.0:包含3个视频生成模型(T2V、T2V Flash、I2V)和一个视频生成音频模型(V2A)去年,在 AI Journey 2023 大会上,Sber AI 推出了两款引人注目的模型:用于图像生成的 Kandinsky 3.0 和俄罗斯首个文本到视频生成模型 Kandinsky Video...多模态模型# Kandinsky 4.01年前03720
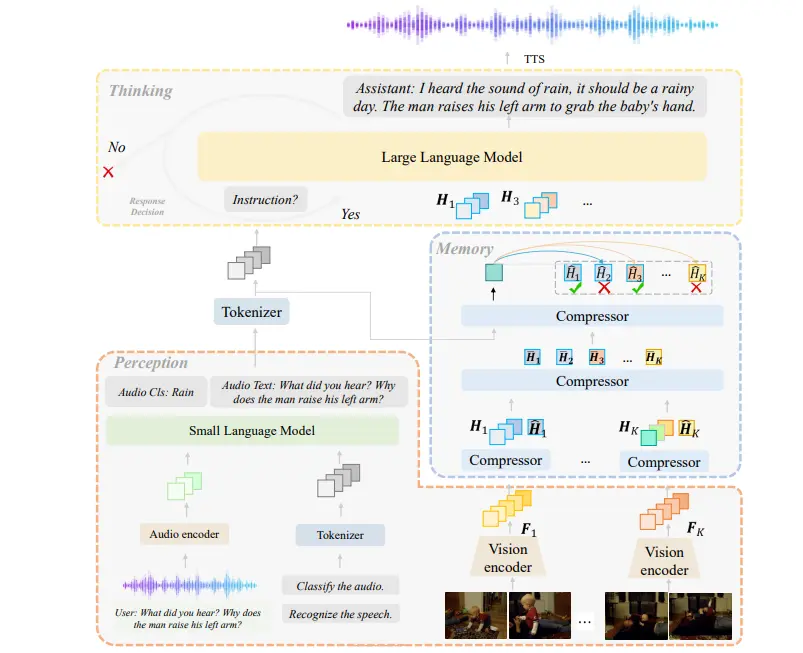
多模态大语言模型Lyra:专注于增强多模态能力,特别是高级长语音理解、声音理解、跨模态效率和无缝语音交互随着多模态大语言模型(MLLMs)的发展,扩展到单一领域之外的能力对于满足更通用和高效AI的需求至关重要。然而,之前的全模态模型在语音处理方面存在不足,忽视了其与视觉、文本等其他模态的深度整合。为了解...多模态模型# Lyra# 多模态大语言模型1年前03000
综合多模态系统InternLM-XComposer2.5-OmniLive (浦语·灵笔 2.5 OmniLive):实现实时视频和音频交互创建能够像人类认知一样长时间与环境互动的AI系统一直是人工智能领域的长期研究目标。尽管多模态大语言模型(MLLMs)在开放世界理解方面取得了显著进展,但在连续和同时的流式感知、记忆和推理方面仍然面临巨...多模态模型# InternLM-XComposer2.5-OmniLive# 浦语·灵笔 2.5 OmniLive1年前02590
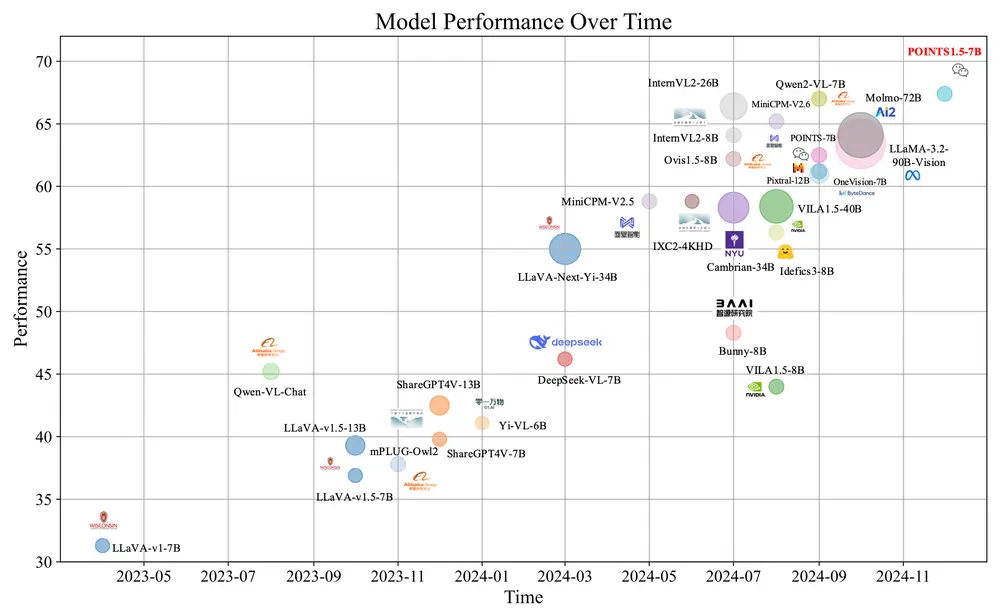
微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列:提升对真实世界应用的处理能力微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列,旨在提升对真实世界应用的处理能力。POINTS1.5是POINTS1.0的增强版本,它通过引入几项关键创新,改进了模型在处理高分辨率图像...多模态模型# POINTS1.5# 视觉语言模型1年前03600
多模态大语言模型InternVL 2.5:处理和理解来自多种模态(如文本、图像和视频)的信息InternVL 2.5 是由上海人工智能实验室、商汤科技研究院、清华大学、南京大学、复旦大学、香港中文大学和上海交通大学等多家机构联合推出的一款先进的多模态大语言模型(MLLM)。该模型基于此前发布...多模态模型# InternVL 2.5# 多模态大语言模型1年前02960