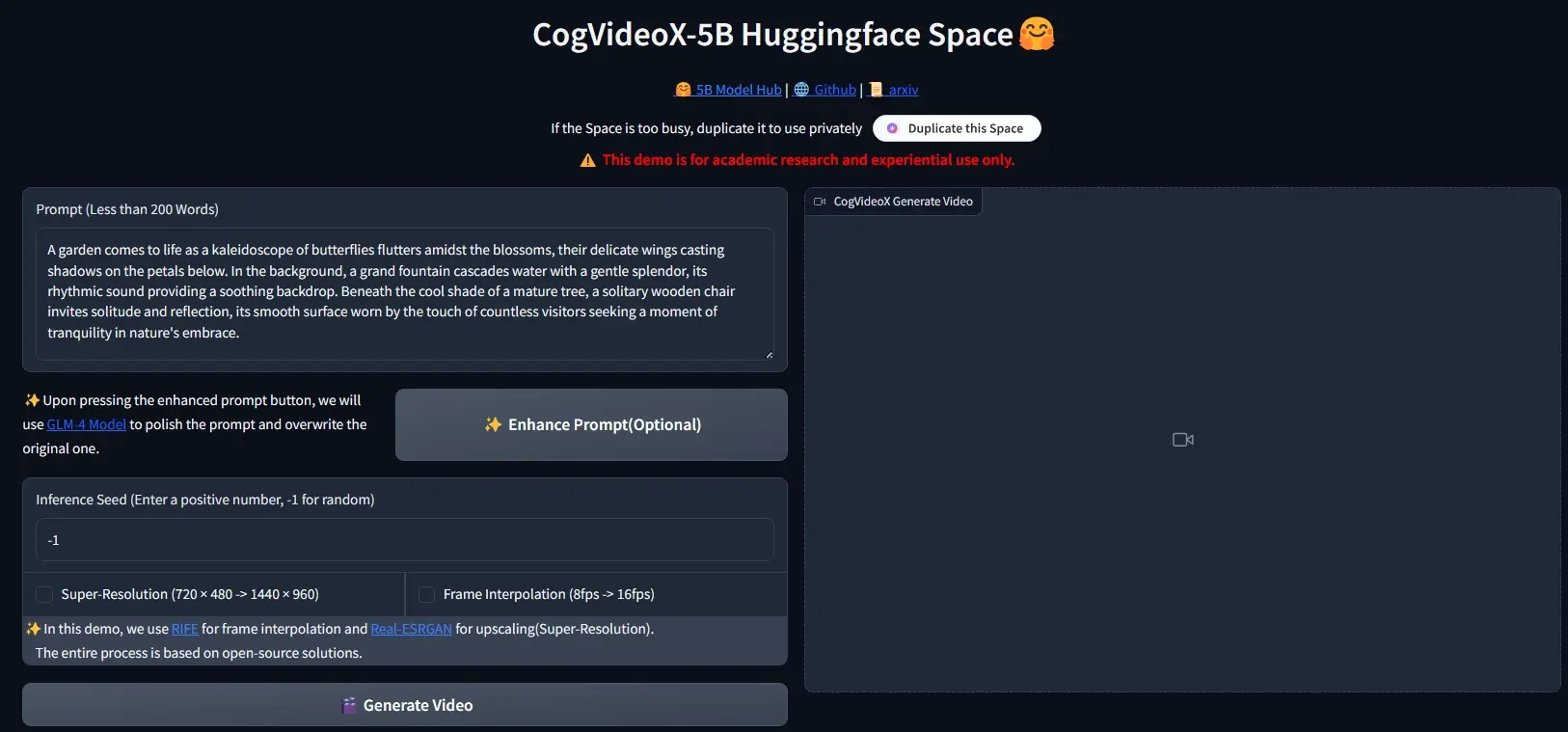
智谱 AI 开源视频生成模型 CogVideoX-5B ,RTX 3060 显卡可运行之前已经给大家分享了《智谱AI推出视频生成模型CogVideoX:与“清影”同源,单张 4090 显卡可推理》,之前推出的是CogVideoX-2B模型,智谱 AI又开源了CogVideoX-5B,相...视频模型# CogVideoX-5B# 智谱 AI12个月前01,0990
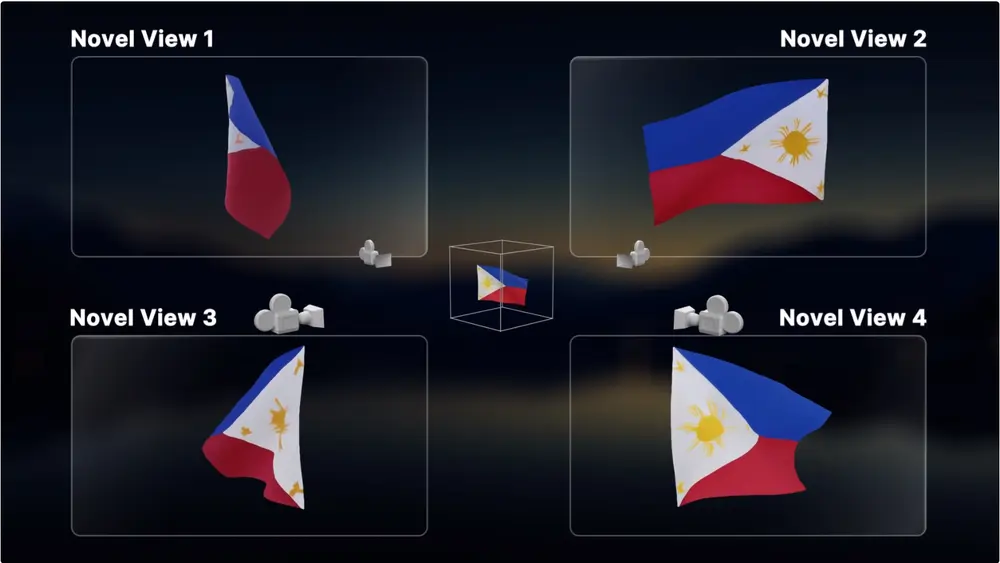
StabilityAI推出全新视频生成模型Stable Video 4D(SV4D):可将单个视频转化为 8 个不同角度/视图的新视图视频StabilityAI在今天推出一个新的视频生成模型Stable Video 4D(SV4D),只需 40 秒就可将单个视频转化为 8 个不同角度/视图的新视图视频(5 帧/个视角),整个 4D 优化...视频模型# StabilityAI# Stable Video 4D# SV4D12个月前01,0510
阿里 WAN 项目组正式推出 Wan2.2:MoE 架构 + 高压缩设计,开源视频生成再进化阿里 WAN 项目组正式推出 Wan2.2,这是对 WAN 系列视频生成模型的一次重大升级。本次发布涵盖多个模型变体,全面支持文本到视频(T2V)、图像到视频(I2V)以及混合输入(TI2V)任务,在...视频模型# Wan2.2# 视频生成模型6个月前01,0330
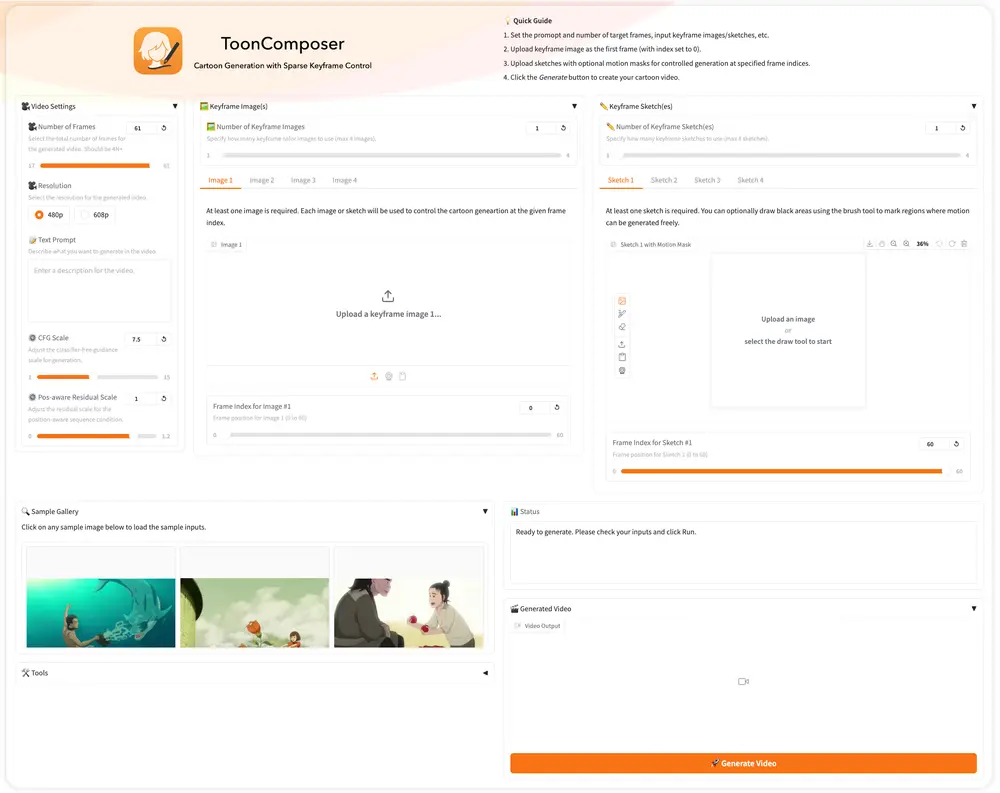
ToonComposer:通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程香港中文大学、腾讯PCG ARC Lab和北京大学的研究人员推出 ToonComposer ,通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程。传统的卡通和动画制作涉及关键帧绘...视频模型# ToonComposer# 卡通制作6个月前01,0170
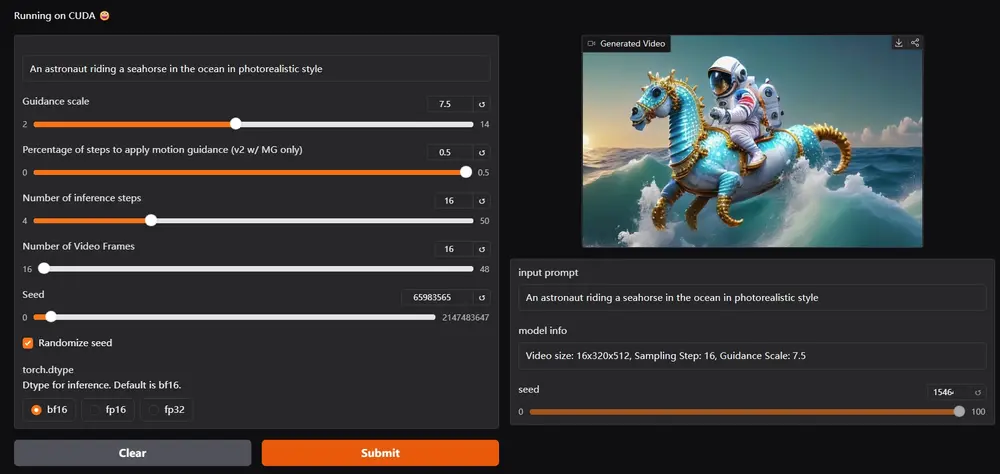
Stable Video DiffusionStability AI于北京时间2023年11月22日推出AI视频生成模型 Stable Video Diffusion,Stable Video Diffusion 由两个模型组成的 ——SVD ...视频模型# AI视频生成# Stable Video Diffusion# SVD12个月前08830
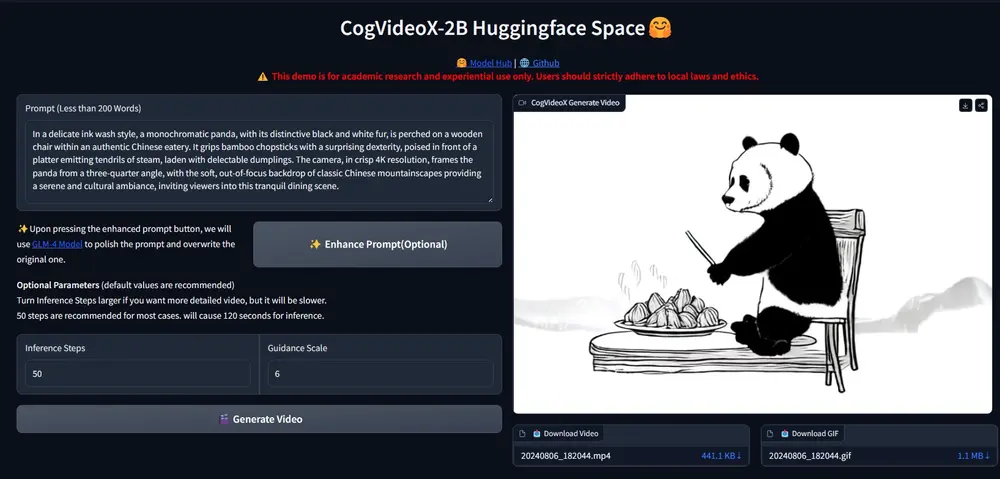
智谱AI推出视频生成模型CogVideoX:与“清影”同源,单张 4090 显卡可推理智谱 AI推出与“清影”同源的视频生成模型 —CogVideoX,CogVideoX模型包含多个不同尺寸大小的模型,目前将开源 CogVideoX-2B,它在 FP-16 精度下的推理需 18GB 显...视频模型# CogVideoX# 智谱AI# 视频生成模型12个月前08070
别让好模型消失,这个 WAN2.1 LoRA 合集值得收藏”近日,CivitAI 在 Visa 和 Mastercard 的压力下进一步收紧内容政策,导致平台上大量 模型被删除。这些模型中包含了许多创作者精心训练的作品,尤其是 NSFW类内容。 地址:http...视频模型# WAN2.1 LoRA8个月前07740
新型视频生成模型T2V-Turbo-v2:基于VideoCrafter2模型提炼,提升视频生成的质量和效率加州大学圣巴巴拉分校、加州大学洛杉矶分校、亚马逊 AGI和滑铁卢大学的研究人员推出新型视频生成模型T2V-Turbo-v2,它旨在提升基于扩散的文本到视频(T2V)生成的质量和效率。简单来说,这项技术...视频模型# T2V-Turbo-v2# 视频生成模型12个月前07630
Sand AI推出新型视频生成模型MAGI-1:通过自回归预测视频块序列来生成视频MAGI-1是由Sand AI研究团队开发的一种新型视频生成模型。该模型通过自回归预测视频块序列来生成视频,每个视频块由固定长度的连续帧组成。MAGI-1的核心目标是实现高保真、实时、因果一致的视频生...视频模型# MAGI-1# Sand AI# 自回归9个月前07120
智谱AI推出CogVideoX 开源模型的升级版本CogVideoX1.5-5B智谱技术团队对于旗下开源视频生成模型CogVideoX进行了升级,今天释出了CogVideoX1.5-5B 系列模型,相比于原有模型,CogVideoX v1.5 将包含 5/10 秒、768P、16...视频模型# CogVideoX1.5-5B# 智谱AI# 智谱清影12个月前06660
字节跳动推出AnimateDiff-Lightning模型:根据文本描述生成视频,还可以视频转视频字节跳动推出了AnimateDiff-Lightning模型,能够更快地根据文本描述生成视频,比起原来的AnimateDiff模型,速度提升十倍以上。 模型地址:https://huggingface...视频模型# AnimateDiff-Lightning# 字节跳动12个月前06380
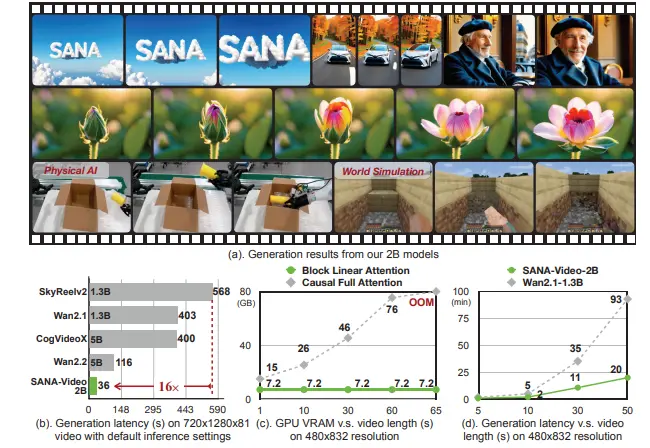
线性注意力 + 恒定内存 KV 缓存!SANA-Video:高效生成分钟级高清视频的新一代文生视频模型在文本到视频(T2V)生成领域,高分辨率、长时长与低延迟三者往往难以兼得。现有大模型虽能生成高质量视频,但动辄数千秒的推理时间与高昂的训练成本严重限制了其落地应用。 为此,由英伟达、香港大学、麻省理工...视频模型# SANA-Video# 文生视频模型4个月前06170