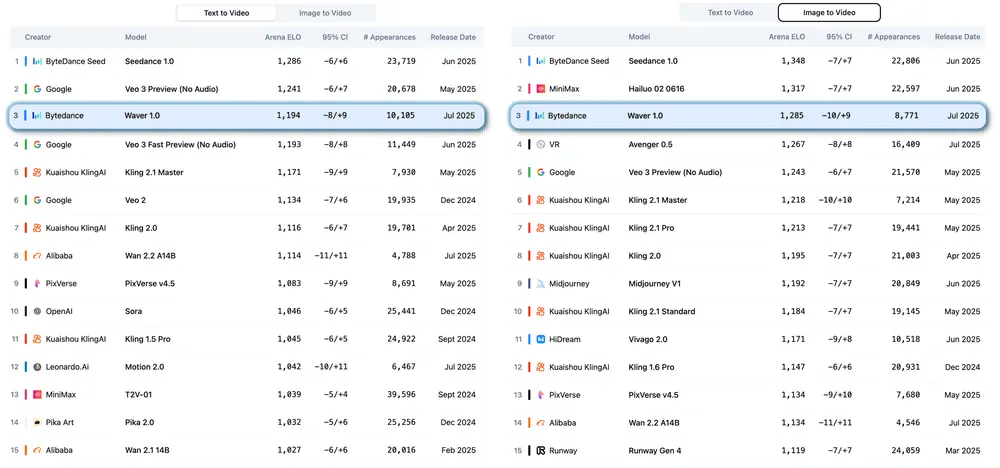
字节跳动 Waver 项目组推出一体化视频生成模型Waver 1.0:同时支持文生图、图生视频及文生图生成字节跳动 Waver 项目组近期正式推出 Waver 1.0 一体化视频生成模型,凭借多模态生成能力、高分辨率支持及卓越的运动建模效果,在视频生成领域实现重要突破,为工业级视频创作需求提供了全新解决方...视频模型# Waver 1.0# 字节跳动# 视频生成5个月前06080
OpenAI视频模型Sora技术报告:构建虚拟世界的模拟器Sora我们专注于研究如何在大规模视频数据上训练生成模型。具体来说,我们针对不同时长、分辨率和宽高比的视频及图像,联合训练了基于文本条件的扩散模型。为了实现这一目标,我们运用了一种能够处理视频和图像潜在编码时...视频模型# OpenAI# Sora# 技术报告12个月前05720
时间延时视频生成模型MagicTime:学习现实世界中的物理知识,并能够生成展示这些知识的时间延时视频来自北京大学深圳研究生院、罗彻斯特大学、新加坡国立大学、广东工业大学和加州大学圣克鲁斯分校的研究人员推出新型时间延时视频生成模型MagicTime,这个模型的目标是学习现实世界中的物理知识,并能够生成...视频模型# MagicTime# 时间延时视频生成模型12个月前05570
PUSA V1.0:以500 美元成本超越 WAN-I2V-14B 的高效视频生成模型由香港城市大学、华为研究院、腾讯、岭南大学等机构联合提出,PUSA V1.0 是一个基于矢量化时间步适应(VTA) 的新型视频扩散模型,实现了极低资源消耗下的高质量视频生成能力。 项目主页:https...视频模型# PUSA V1.0# WAN-I2V-14B# 视频生成模型7个月前05370
阿里通义实验室推出新型模型LHM:能够在几秒钟内从单张图像重建出可动画化的人体三维模型阿里通义实验室推出新型模型LHM,能够在几秒钟内从单张图像重建出可动画化的人体三维模型。该模型利用多模态变换器架构,有效融合了人体位置特征和图像特征,通过注意力机制实现了几何和视觉领域的联合推理。 项...视频模型# LHM# 阿里通义实验室11个月前05180
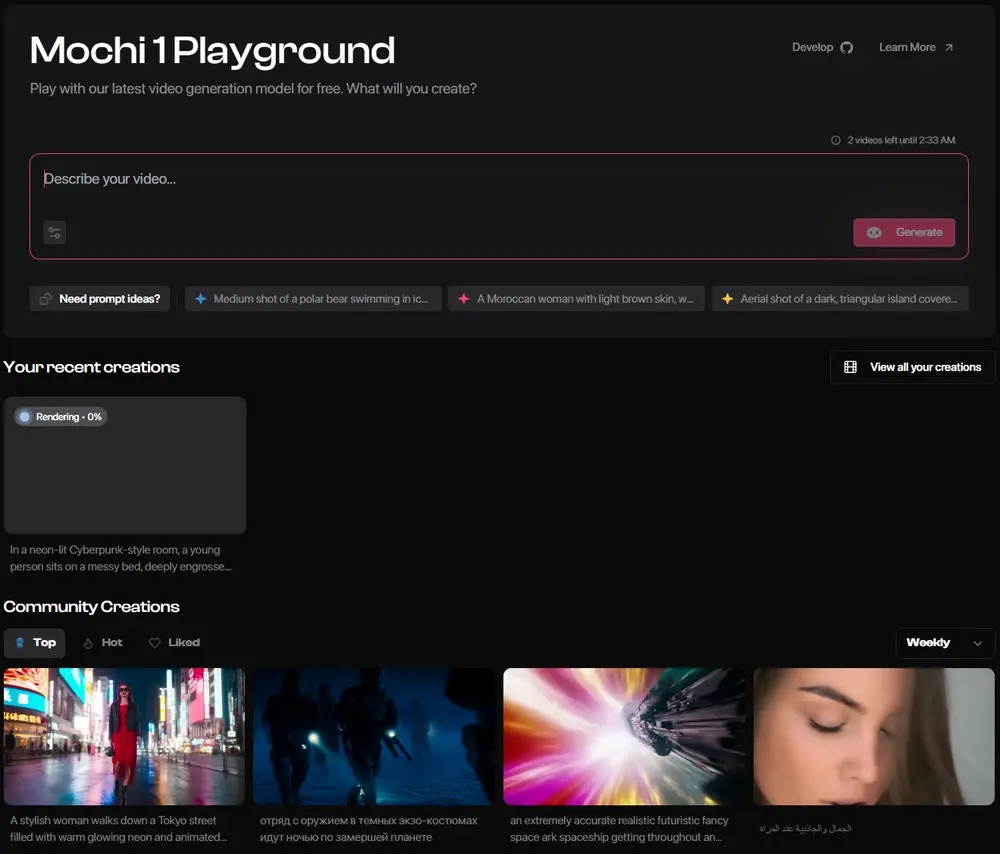
Genmo推出开源视频生成模型天花板Mochi 1,型需 4 块英伟达H100 显卡才可运行Genmo是一家专注于视频生成的AI初创公司,之前都是默默无闻,其官方视频生成产品也是半死不活,但他们在昨天突然放大招开源了一款视频生成模型Mochi 1,号称其性能可与领先的闭源/专有竞争对手(如R...视频模型# Genmo# Mochi 1# 视频生成模型12个月前05180
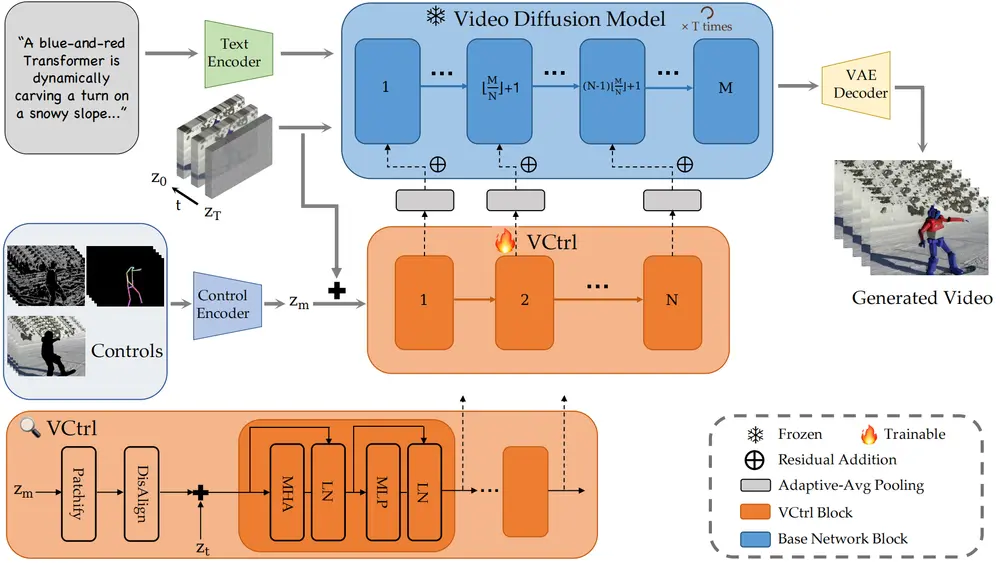
通用视频生成控制模型PP-VCtrl:引入辅助条件编码器,能够灵活对接各类控制模块在数字创意蓬勃发展的当下,视频生成技术已成为内容创作的核心驱动力之一。然而,尽管文本到视频的扩散模型取得了显著进展,但在精确控制生成内容的时空特征方面仍存在诸多挑战。广告创意、影视后期制作、直播带货...视频模型# PP-VCtrl# 视频生成控制模型10个月前05150
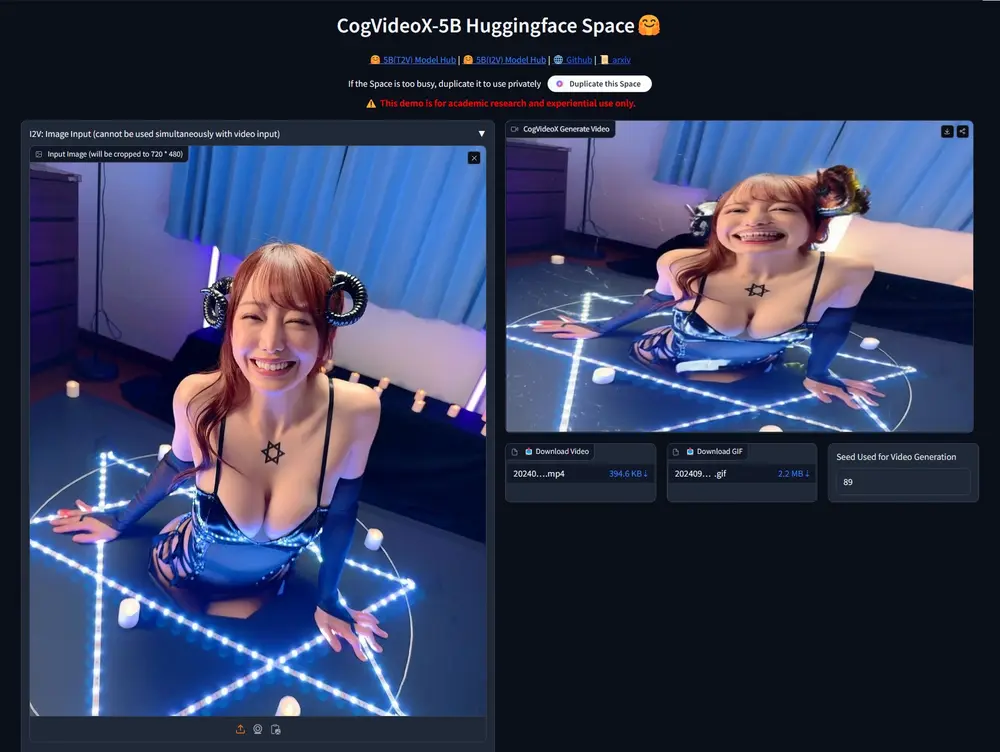
智谱 AI推出CogVideoX 系列图生视频模型 CogVideoX-5B-I2VCogVideoX是智谱 AI推出的与 清影 同源的开源版本视频生成模型,之前已经释出了CogVideoX-2B和CogVideoX-5B模型,智谱 AI又在昨天释出了 CogVideoX 系列图生视...视频模型# CogVideoX-5B-I2V# 智谱 AI12个月前05140
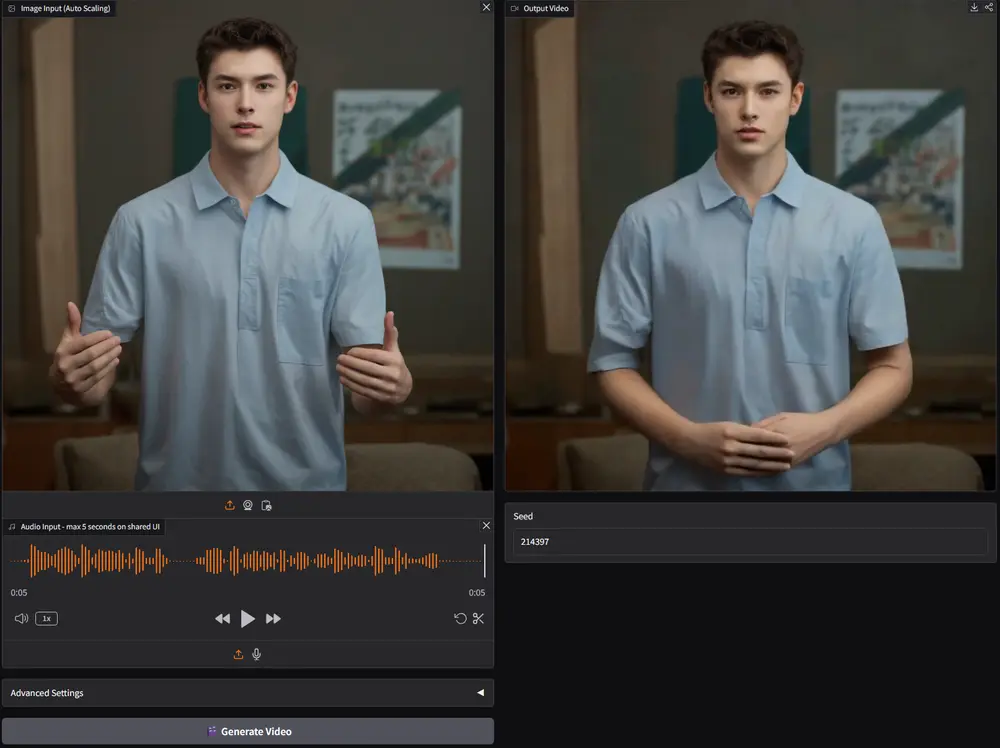
阿里开源 Wan2.2-S2V-14B:输入一张图 + 一段音频,生成电影级数字人视频阿里Wan团队正式开源音频驱动视频生成模型Wan2.2-S2V-14B。这款模型打破了传统视频生成对复杂输入的依赖——用户仅需提供一张静态图像与一条音频,即可生成面部表情自然、口型精准同步、肢体动作流...视频模型# Wan2.2-S2V-14B# 数字人# 阿里5个月前04910
新型视频生成模型Pyramidal Flow:提高视频生成的效率,同时保持生成视频的高质量北京大学、快手科技和北京邮电大学的研究人员推出新型视频生成模型Pyramidal Flow,这个模型的目的是提高视频生成的效率,同时保持生成视频的高质量。可以想象一下,你想制作一个视频,里面有一只小猫...视频模型# Pyramidal Flow# 视频生成模型12个月前04810
半身人体动画生成框架 EchoMimicV2:利用参考图像、音频剪辑和一系列手部姿势来生成高质量的动画视频随着计算机图形学和人工智能的发展,生成高质量的人类动画变得越来越重要。特别是,当涉及到创建生动、自然的动画时,音频、姿势或运动图等条件的引入大大提升了动画的真实性和表现力。然而,这些增强的方法也带来了...视频模型# EchoMimicV2# 动画生成12个月前04740
字节跳动推出基于修正流Transformer 架构的新型图像和视频生成模型家族Goku香港大学和字节跳动的研究人员推出新型图像和视频生成模型家族Goku,它基于修正流Transformer 架构,实现了行业领先的图像和视频联合生成性能。Goku 的目标是通过高质量的视觉内容生成,推动媒...视频模型# Goku# 字节跳动# 视频生成12个月前04670