StableAvatar:首个端到端生成无限长度虚拟人视频的扩散模型你是否曾想过,仅凭一张静态照片和一段语音,就能让照片中的人物“开口说话”,并持续数分钟自然表达?这正是音频驱动虚拟人视频生成(Audio-Driven Talking Head Generation...视频模型# StableAvatar# 虚拟人6个月前04610
腾讯微信视觉团队发布 Stand-In:轻量级身份保持视频生成新框架在文本到视频(T2V)生成领域,一个长期存在的难题是:如何让生成的视频中的人物始终“长成你想要的样子”? 尽管现有模型能生成流畅、高质量的视频,但在身份一致性(identity-preserving...视频模型# Stand-In# 视频生成框架5个月前04600
AccVideo:通过知识蒸馏技术,将HunyuanVideo模型生成速度提高了 8.5 倍,同时保持生成质量视频扩散模型是一种强大的生成模型,能够生成高质量的视频内容。然而,传统的视频扩散模型在生成视频时需要大量的迭代去噪步骤,这使得生成过程非常缓慢且计算成本高昂。例如,HunyuanVideo 模型在单个...视频模型# AccVideo# HunyuanVideo# 知识蒸馏10个月前04550
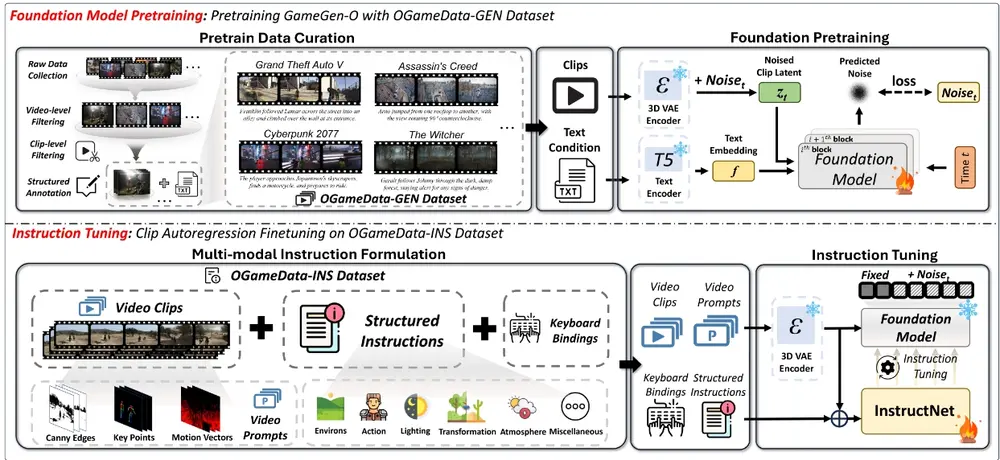
腾讯推出专为生成开放世界游戏量身定制的DiT模型GameGen-O:通过模拟各种游戏引擎特性,如创新角色、动态环境、复杂动作和多样事件,促进了高质量、开放领域的生成香港科技大学、中国科学技术大学和腾讯光子工作室的研究人员推出一个专为生成开放世界游戏量身定制的DiT模型GameGen-O,该模型通过模拟各种游戏引擎特性,如创新角色、动态环境、复杂动作和多样事件,促...视频模型# DiT模型# GameGen-O# 开放世界游戏12个月前04530
浙大 & vivo 联合发布 MagicTryOn:首个基于扩散 Transformer 的视频虚拟试衣框架在虚拟试衣技术持续发展的背景下,如何在视频中实现自然、真实、连贯的服装模拟,依然是一个极具挑战性的课题。 浙江大学、vivo 和博维智慧科技的研究团队提出了一种全新的视频虚拟试衣(Video Virt...视频模型# MagicTryOn# Wan2.1# 视频虚拟试衣8个月前04520
阿里通义实验室 Wan 团队推出一体化视频编辑框架 VACE阿里通义实验室 Wan 团队近日推出了一款专为视频创建和编辑设计的一体化视频编辑框架——VACE。该框架集成了多种视频任务,包括参考到视频生成(R2V)、视频到视频编辑(V2V)和蒙版视频到视频编辑...视频模型# VACE# Wan# 通义实验室11个月前04440
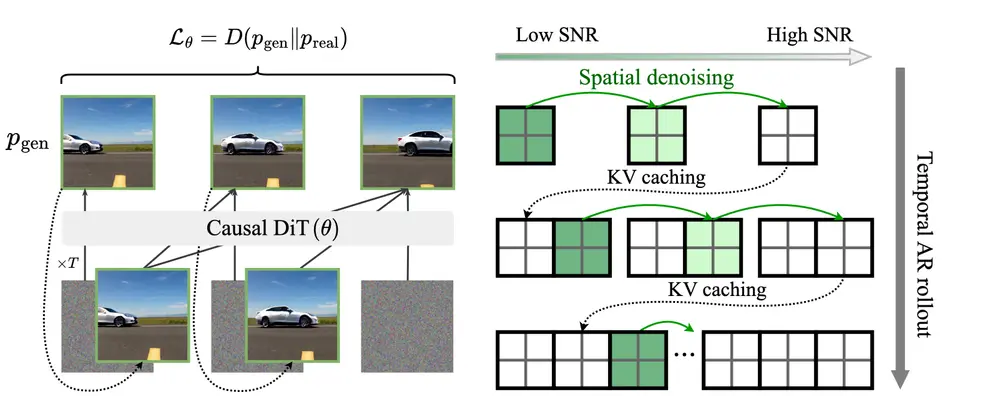
新型训练范式Self Forcing:用于自回归视频扩散模型,解决模型在训练和推理时的分布不一致问题Adobe研究和德克萨斯大学奥斯汀分校的研究人员推出新型训练范式Self Forcing ,用于自回归视频扩散模型,旨在解决模型在训练和推理时的分布不一致问题(即暴露偏差问题),从而提高视频生成的...视频模型# Self Forcing# 训练范式7个月前04420
B站Index团队开源动漫视频生成模型 AniSora:一键生成多种风格的动漫视频片段哔哩哔哩(B站)Index团队开源了一款名为 AniSora 的动漫视频生成模型。作为目前最强大的开源动漫视频生成工具,AniSora 能够一键生成多种风格的动漫视频片段,包括番剧剧集、国创动画、漫画...视频模型# AniSora# B站# 动漫视频生成模型9个月前04410
Rhymes AI开源视频生成模型Allegro:从简单的文本提示生成高质量的 6 秒视频Rhymes AI在推出多模态原生模型Aria后,又在昨天开源了视频生成模型Allegro,Allegro 使用户能够从简单的文本提示生成高质量的 6 秒视频,帧率为 15 帧每秒,分辨率为 720P...视频模型# Allegro# Rhymes AI# 视频生成模型12个月前04380
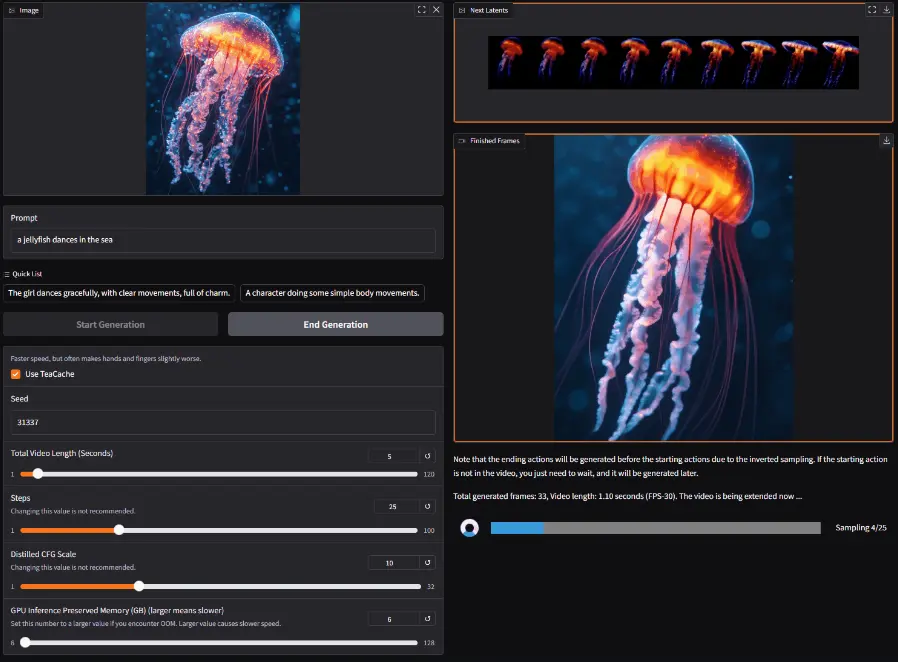
FramePack:用神经网络破解视频生成难题,能够将输入上下文压缩至固定长度,使生成工作量不受视频长度影响视频生成技术一直是AI领域的热门研究方向之一。然而,现有的视频生成模型在处理长视频时常常面临两大挑战:一是“遗忘”问题,模型难以记住早期的视频内容,导致生成的视频缺乏连贯性;二是“漂移”问题,随着视频...视频模型# controlnet# FramePack# Lvmin Zhang9个月前04320
Lightricks 推出 LTX Video 0.9.6:更快、更稳定,助力创意视频生成Lightricks 在 5 个月前推出了视频生成模型 LTX Video。今天,官方宣布 LTXV 0.9.6 版本正式发布,为视频生成领域带来了新的突破。此次更新推出了 2B 参数开源视频模型的两...视频模型# LTX Video# LTXV 0.9.6# 视频生成模型10个月前04300
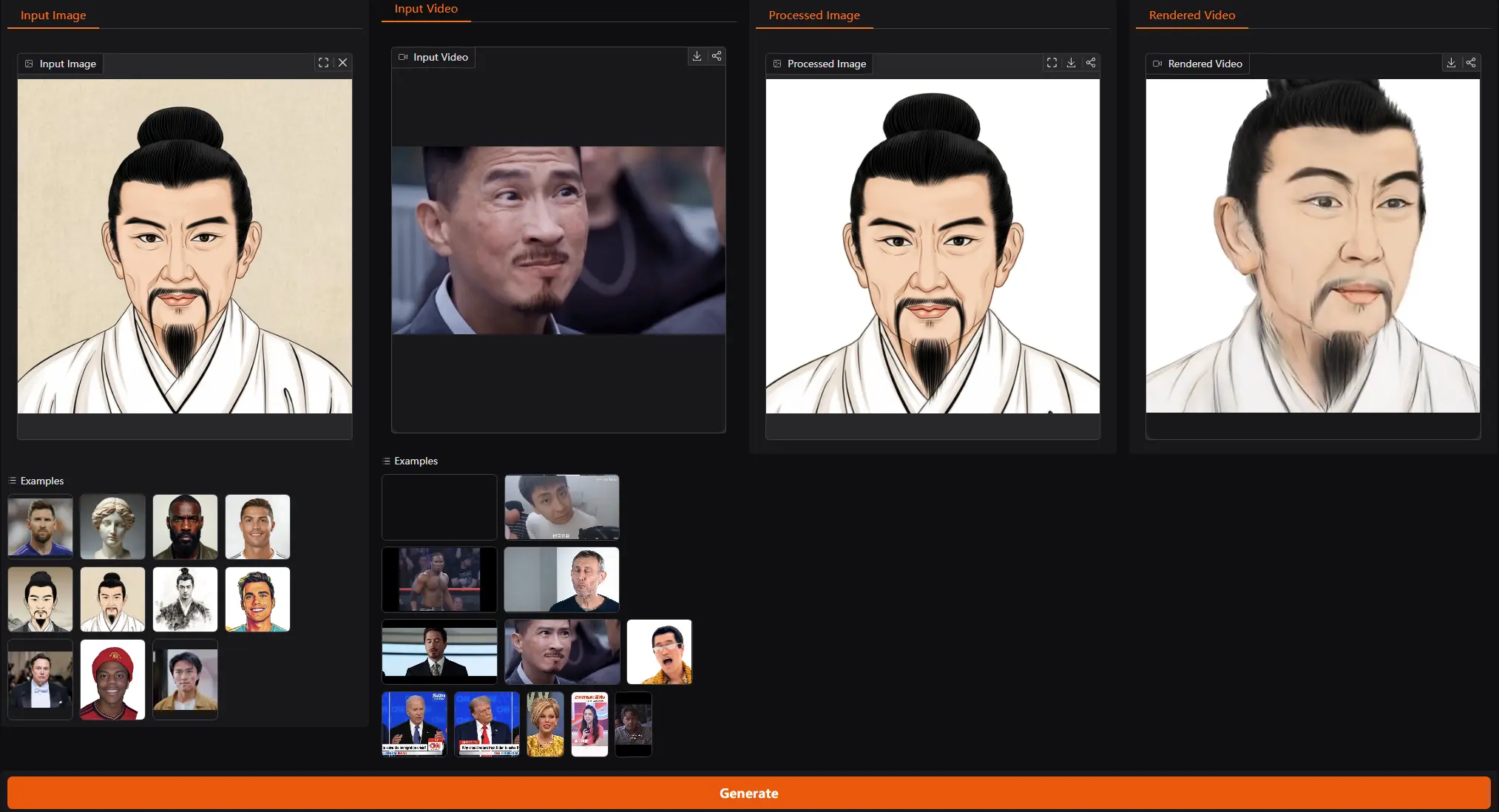
阿里巴巴通义实验室推出新型单次拍摄可动画化的高斯头部模型 LAM:能够从单张图像中生成可动画化且可渲染的高斯头像阿里巴巴通义实验室推出新型单次拍摄可动画化的高斯头部模型 LAM(Large Avatar Model),能够从单张图像中生成可动画化且可渲染的高斯头像。与以往需要大量视频序列训练或依赖辅助神经网络进...视频模型# LAM# 通义实验室# 高斯头像10个月前04300